https://stackoverflow.com/questions/20387333
https://stackoverflow.com/questions/20387333
 italiano
italiano english
english français
français española
española 中国
中国 日本の
日本の العربية
العربية Deutsch
Deutsch 한국어
한국어 Português
Português Russian
RussianTheres two ways you can achieve what you're looking to do...
Using search
Extract the fields with rex and use eval to concatenate the values.
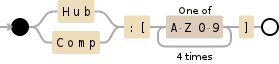
| rex field=_raw "Hub:\[(?<Hub>[^\]]*)\]\sComp:\[(?<Comp>[^\]]*)\]" | eval someNewField=Hub."-".Comp
The rex command allows you to run a regular expression against a field, _raw is a special field name that contains the entire event data. The regex itself captures any characters between [ and ] and extracts it to the field named within the <>.
This is the easiest way as you don't need to modify any configuration to do it, but the drawback is that you'll need to add this to your search string to get the values extracted and formatting the way you want.
Using search time extraction with prop.conf and transforms.conf
In transforms.conf, add a transform to extract the fields...
[hubCompExtract]
REGEX = Hub:\[(?<Hub>[^\]]*)\]\sComp:\[(?<Comp>[^\]]*)\]
In props.conf, execute the extract and concatenate the values using an eval...
[yourSourceTypeName]
REPORT-fieldExtract = hubCompExtract
EVAL-yourNewFieldName = Hub."-".Comp
No need to add anything to your search string, but it does require config file changes.
Regex example
gSkinner example (without the capture group names).