 https://stackoverflow.com/questions/21300309
https://stackoverflow.com/questions/21300309
 italiano
italiano english
english français
français española
española 中国
中国 日本の
日本の العربية
العربية Deutsch
Deutsch 한국어
한국어 Português
Português Russian
Russianhere is your regular expression:
\s+(((زا(ی)?)?|ام?|ات|اش|ای?(د)?|ایم?|اند?)[\.\!\?\،]*)
and here is a visualization:
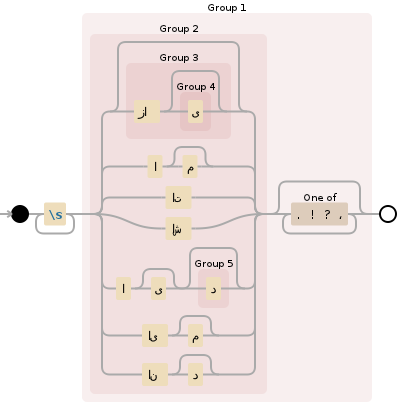
Your replacement is r'\1 ' which means replace what you found with the 1st group followed by space. I don't read farsi, but here is another example:
\s+((a|b)[./?]*)
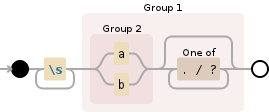
so let's execute some code:
>>> newline = ' a? b? a.'
>>> re.sub('\s+((a|b)[./?]*)', r'\1 ', newline)
'a? b? a. '
This eats extra spaces preceding a particular group of characters (the leading \s+) and changes it to the identified group 1 followed by one space (r'\1 ').
