Abflachen eine flache Liste in Python [Duplicate]
 https://stackoverflow.com/questions/406121
https://stackoverflow.com/questions/406121
-
03-07-2019 - |
 italiano
italiano english
english français
français española
española 中国
中国 日本の
日本の العربية
العربية Deutsch
Deutsch 한국어
한국어 Português
Português Russian
RussianFrage
Diese Frage bereits eine Antwort hier:
Gibt es eine einfache Möglichkeit, eine Liste von Iterables mit einer Liste Verständnis, oder andernfalls zu glätten, was würden Sie alle betrachten der beste Weg, um eine flache Liste wie diese zu glätten, Leistung und Lesbarkeit balancieren?
Ich habe versucht, eine solche Liste mit einer verschachtelten Liste Verständnis abzuflachen, wie folgt aus:
[image for image in menuitem for menuitem in list_of_menuitems]
Aber ich bekomme Ärger der NameError Vielfalt gibt, weil die name 'menuitem' is not defined. Nach googeln und schaut sich um auf Stack-Überlauf, bekam ich die gewünschten Ergebnisse mit einer reduce Anweisung:
reduce(list.__add__, map(lambda x: list(x), list_of_menuitems))
Aber diese Methode ist ziemlich unleserlich, weil ich, dass list(x) Anruf dort brauchen, weil x eine Django QuerySet Objekt.
Fazit :
Vielen Dank an alle, die zu dieser Frage beigetragen. Hier ist eine Zusammenfassung dessen, was ich gelernt habe. Ich mache auch dies ein Community Wiki bei anderen hinzufügen möchten oder diese Beobachtungen zu korrigieren.
Meine ursprüngliche reduzieren Erklärung ist überflüssig und wird besser auf diese Weise geschrieben:
>>> reduce(list.__add__, (list(mi) for mi in list_of_menuitems))
Dies ist die korrekte Syntax für eine verschachtelte Liste Verständnis (Brilliant Zusammenfassung dF !):
>>> [image for mi in list_of_menuitems for image in mi]
Aber keine dieser Methoden sind so effizient wie itertools.chain mit:
>>> from itertools import chain
>>> list(chain(*list_of_menuitems))
Und wie @cdleary Noten, ist es wahrscheinlich besser Stil * Operator Magie zu vermeiden, indem chain.from_iterable mit etwa so:
>>> chain = itertools.chain.from_iterable([[1,2],[3],[5,89],[],[6]])
>>> print(list(chain))
>>> [1, 2, 3, 5, 89, 6]
Lösung
Wenn Sie nur eine abgeflachte Version der Datenstruktur iterieren suchen und keine Wendesequenz benötigen, sollten Sie itertools.chain und Unternehmen .
>>> list_of_menuitems = [['image00', 'image01'], ['image10'], []]
>>> import itertools
>>> chain = itertools.chain(*list_of_menuitems)
>>> print(list(chain))
['image00', 'image01', 'image10']
Es wird auf etwas arbeiten, das iterable ist, der Djangos iterable QuerySets enthalten soll, die es scheint, dass Sie in der Frage verwenden.
Edit: Dies ist wahrscheinlich so gut wie ein ohnehin zu reduzieren, weil reduziert die gleichen Kopf Kopieren Sie die Elemente in die Liste, die verlängert haben werden. chain wird nur entstehen diese (gleiche) Overhead, wenn Sie list(chain) am Ende ausgeführt werden.
Meta-Edit:. Eigentlich ist es weniger Overhead als die vorgeschlagene Lösung auf die Frage, weil Sie die temporären Listen wegzuwerfen Sie erstellen, wenn Sie das Original mit der temporären verlängern
Edit: Wie J. F. Sebastian sagt itertools.chain.from_iterable das Auspacken vermeidet und Sie sollten, dass * Magie zu vermeiden verwenden, aber die timeit App vernachlässigbaren Unterschied in der Leistung zeigt.
Andere Tipps
Sie fast haben es! Die Weise verschachtelte Liste Comprehensions zu tun ist die for Aussagen zu setzen in der gleichen Reihenfolge wie würden sie in regelmäßigen verschachtelten for Aussagen gehen.
Damit diese
for inner_list in outer_list:
for item in inner_list:
...
entspricht
[... for inner_list in outer_list for item in inner_list]
Sie wollen also
[image for menuitem in list_of_menuitems for image in menuitem]
@ S.Lott : Sie hat mich inspiriert, ein zu schreiben timeit App.
Habe ich es auch auf die Anzahl der Partitionen (Anzahl der Iteratoren innerhalb der Containerliste) variieren würde - Ihr Kommentar nicht erwähnt, wie viele Partitionen gab es von den dreißig Artikeln. Dieses Grundstück befindet sich Abflachung tausend Artikel in jedem Lauf, mit unterschiedlicher Anzahl von Partitionen. Die Elemente werden unter den Partitionen verteilt sind.
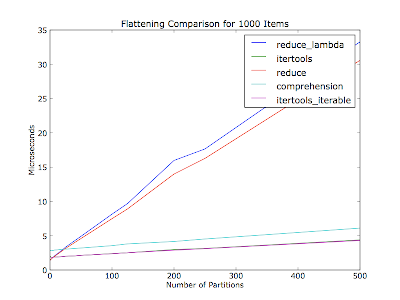
-Code (Python 2.6):
#!/usr/bin/env python2.6
"""Usage: %prog item_count"""
from __future__ import print_function
import collections
import itertools
import operator
from timeit import Timer
import sys
import matplotlib.pyplot as pyplot
def itertools_flatten(iter_lst):
return list(itertools.chain(*iter_lst))
def itertools_iterable_flatten(iter_iter):
return list(itertools.chain.from_iterable(iter_iter))
def reduce_flatten(iter_lst):
return reduce(operator.add, map(list, iter_lst))
def reduce_lambda_flatten(iter_lst):
return reduce(operator.add, map(lambda x: list(x), [i for i in iter_lst]))
def comprehension_flatten(iter_lst):
return list(item for iter_ in iter_lst for item in iter_)
METHODS = ['itertools', 'itertools_iterable', 'reduce', 'reduce_lambda',
'comprehension']
def _time_test_assert(iter_lst):
"""Make sure all methods produce an equivalent value.
:raise AssertionError: On any non-equivalent value."""
callables = (globals()[method + '_flatten'] for method in METHODS)
results = [callable(iter_lst) for callable in callables]
if not all(result == results[0] for result in results[1:]):
raise AssertionError
def time_test(partition_count, item_count_per_partition, test_count=10000):
"""Run flatten methods on a list of :param:`partition_count` iterables.
Normalize results over :param:`test_count` runs.
:return: Mapping from method to (normalized) microseconds per pass.
"""
iter_lst = [[dict()] * item_count_per_partition] * partition_count
print('Partition count: ', partition_count)
print('Items per partition:', item_count_per_partition)
_time_test_assert(iter_lst)
test_str = 'flatten(%r)' % iter_lst
result_by_method = {}
for method in METHODS:
setup_str = 'from test import %s_flatten as flatten' % method
t = Timer(test_str, setup_str)
per_pass = test_count * t.timeit(number=test_count) / test_count
print('%20s: %.2f usec/pass' % (method, per_pass))
result_by_method[method] = per_pass
return result_by_method
if __name__ == '__main__':
if len(sys.argv) != 2:
raise ValueError('Need a number of items to flatten')
item_count = int(sys.argv[1])
partition_counts = []
pass_times_by_method = collections.defaultdict(list)
for partition_count in xrange(1, item_count):
if item_count % partition_count != 0:
continue
items_per_partition = item_count / partition_count
result_by_method = time_test(partition_count, items_per_partition)
partition_counts.append(partition_count)
for method, result in result_by_method.iteritems():
pass_times_by_method[method].append(result)
for method, pass_times in pass_times_by_method.iteritems():
pyplot.plot(partition_counts, pass_times, label=method)
pyplot.legend()
pyplot.title('Flattening Comparison for %d Items' % item_count)
pyplot.xlabel('Number of Partitions')
pyplot.ylabel('Microseconds')
pyplot.show()
Edit:. Beschlossen, es Community Wiki machen
Hinweis: METHODS sollte wahrscheinlich mit einem Dekorateur gesammelt werden, aber ich glaube es einfacher sein würde für die Menschen auf diese Weise lesen
sum(list_of_lists, []) wäre es abzuflachen.
l = [['image00', 'image01'], ['image10'], []]
print sum(l,[]) # prints ['image00', 'image01', 'image10']
Diese Lösung funktioniert für beliebige Verschachtelung Tiefen - und nicht nur die „Liste der Listen“ Tiefe, die einige (alle?) Von den anderen Lösungen sind begrenzt:
def flatten(x):
result = []
for el in x:
if hasattr(el, "__iter__") and not isinstance(el, basestring):
result.extend(flatten(el))
else:
result.append(el)
return result
Es ist die Rekursion, die für beliebige Tiefe Verschachtelung erlaubt - bis die maximale Rekursionstiefe getroffen, natürlich ...
In Python 2.6 unter Verwendung von chain.from_iterable() :
>>> from itertools import chain
>>> list(chain.from_iterable(mi.image_set.all() for mi in h.get_image_menu()))
Es vermeidet Erstellen von Zwischen Liste.
Performance-Ergebnisse. Überarbeitete.
import itertools
def itertools_flatten( aList ):
return list( itertools.chain(*aList) )
from operator import add
def reduce_flatten1( aList ):
return reduce(add, map(lambda x: list(x), [mi for mi in aList]))
def reduce_flatten2( aList ):
return reduce(list.__add__, map(list, aList))
def comprehension_flatten( aList ):
return list(y for x in aList for y in x)
I abgeflacht eine 2-Level-Liste der 30 Produkte 1000 mal
itertools_flatten 0.00554
comprehension_flatten 0.00815
reduce_flatten2 0.01103
reduce_flatten1 0.01404
reduzieren, ist immer eine schlechte Wahl.
Es scheint eine Verwechslung mit operator.add zu sein! Wenn Sie zwei Listen zusammen fügen, die korrekte Bezeichnung für das concat ist, fügen Sie nicht. operator.concat ist, was Sie verwenden müssen.
Wenn Sie funktional denken, es ist so einfach, wie dies ::
>>> list2d = ((1,2,3),(4,5,6), (7,), (8,9))
>>> reduce(operator.concat, list2d)
(1, 2, 3, 4, 5, 6, 7, 8, 9)
Sie sehen Hinsicht den Sequenztyp reduzieren, so dass, wenn Sie ein Tupel liefern, erhalten Sie ein Tupel zurück. Lassen Sie uns mit einer Liste versuchen ::
>>> list2d = [[1,2,3],[4,5,6], [7], [8,9]]
>>> reduce(operator.concat, list2d)
[1, 2, 3, 4, 5, 6, 7, 8, 9]
Aha, erhalten Sie zurück eine Liste.
Wie wäre Leistung ::
>>> list2d = [[1,2,3],[4,5,6], [7], [8,9]]
>>> %timeit list(itertools.chain.from_iterable(list2d))
1000000 loops, best of 3: 1.36 µs per loop
from_iterable ist ziemlich schnell! Aber es ist kein Vergleich mit concat zu reduzieren.
>>> list2d = ((1,2,3),(4,5,6), (7,), (8,9))
>>> %timeit reduce(operator.concat, list2d)
1000000 loops, best of 3: 492 ns per loop
Aus der Spitze von meinem Kopf, können Sie das Lambda beseitigen:
reduce(list.__add__, map(list, [mi.image_set.all() for mi in list_of_menuitems]))
Oder sogar die Karte eliminieren, da Sie bereits eine Liste-comp bekam:
reduce(list.__add__, [list(mi.image_set.all()) for mi in list_of_menuitems])
Sie können auch ausdrücken gerade dies als eine Summe von Listen:
sum([list(mi.image_set.all()) for mi in list_of_menuitems], [])
Hier ist die richtige Lösung mit Listenkomprehensionen (sie sind rückwärts in der Frage):
>>> join = lambda it: (y for x in it for y in x)
>>> list(join([[1,2],[3,4,5],[]]))
[1, 2, 3, 4, 5]
In Ihrem Fall wäre es
[image for menuitem in list_of_menuitems for image in menuitem.image_set.all()]
oder Sie könnten join verwenden und sagen
join(menuitem.image_set.all() for menuitem in list_of_menuitems)
In jedem Fall ist die Gotcha die Verschachtelung der for Schleife war.
Sie haben versucht, glätten? Aus matplotlib.cbook.flatten (Seq, scalarp =) ?
l=[[1,2,3],[4,5,6], [7], [8,9]]*33
run("list(flatten(l))")
3732 function calls (3303 primitive calls) in 0.007 seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
1 0.000 0.000 0.007 0.007 <string>:1(<module>)
429 0.001 0.000 0.001 0.000 cbook.py:475(iterable)
429 0.002 0.000 0.003 0.000 cbook.py:484(is_string_like)
429 0.002 0.000 0.006 0.000 cbook.py:565(is_scalar_or_string)
727/298 0.001 0.000 0.007 0.000 cbook.py:605(flatten)
429 0.000 0.000 0.001 0.000 core.py:5641(isMaskedArray)
858 0.001 0.000 0.001 0.000 {isinstance}
429 0.000 0.000 0.000 0.000 {iter}
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
l=[[1,2,3],[4,5,6], [7], [8,9]]*66
run("list(flatten(l))")
7461 function calls (6603 primitive calls) in 0.007 seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
1 0.000 0.000 0.007 0.007 <string>:1(<module>)
858 0.001 0.000 0.001 0.000 cbook.py:475(iterable)
858 0.002 0.000 0.003 0.000 cbook.py:484(is_string_like)
858 0.002 0.000 0.006 0.000 cbook.py:565(is_scalar_or_string)
1453/595 0.001 0.000 0.007 0.000 cbook.py:605(flatten)
858 0.000 0.000 0.001 0.000 core.py:5641(isMaskedArray)
1716 0.001 0.000 0.001 0.000 {isinstance}
858 0.000 0.000 0.000 0.000 {iter}
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
l=[[1,2,3],[4,5,6], [7], [8,9]]*99
run("list(flatten(l))")
11190 function calls (9903 primitive calls) in 0.010 seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
1 0.000 0.000 0.010 0.010 <string>:1(<module>)
1287 0.002 0.000 0.002 0.000 cbook.py:475(iterable)
1287 0.003 0.000 0.004 0.000 cbook.py:484(is_string_like)
1287 0.002 0.000 0.009 0.000 cbook.py:565(is_scalar_or_string)
2179/892 0.001 0.000 0.010 0.000 cbook.py:605(flatten)
1287 0.001 0.000 0.001 0.000 core.py:5641(isMaskedArray)
2574 0.001 0.000 0.001 0.000 {isinstance}
1287 0.000 0.000 0.000 0.000 {iter}
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
l=[[1,2,3],[4,5,6], [7], [8,9]]*132
run("list(flatten(l))")
14919 function calls (13203 primitive calls) in 0.013 seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
1 0.000 0.000 0.013 0.013 <string>:1(<module>)
1716 0.002 0.000 0.002 0.000 cbook.py:475(iterable)
1716 0.004 0.000 0.006 0.000 cbook.py:484(is_string_like)
1716 0.003 0.000 0.011 0.000 cbook.py:565(is_scalar_or_string)
2905/1189 0.002 0.000 0.013 0.000 cbook.py:605(flatten)
1716 0.001 0.000 0.001 0.000 core.py:5641(isMaskedArray)
3432 0.001 0.000 0.001 0.000 {isinstance}
1716 0.001 0.000 0.001 0.000 {iter}
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler'
UPDATE Welche gab mir eine andere Idee:
l=[[1,2,3],[4,5,6], [7], [8,9]]*33
run("flattenlist(l)")
564 function calls (432 primitive calls) in 0.000 seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
133/1 0.000 0.000 0.000 0.000 <ipython-input-55-39b139bad497>:4(flattenlist)
1 0.000 0.000 0.000 0.000 <string>:1(<module>)
429 0.000 0.000 0.000 0.000 {isinstance}
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
l=[[1,2,3],[4,5,6], [7], [8,9]]*66
run("flattenlist(l)")
1125 function calls (861 primitive calls) in 0.001 seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
265/1 0.001 0.000 0.001 0.001 <ipython-input-55-39b139bad497>:4(flattenlist)
1 0.000 0.000 0.001 0.001 <string>:1(<module>)
858 0.000 0.000 0.000 0.000 {isinstance}
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
l=[[1,2,3],[4,5,6], [7], [8,9]]*99
run("flattenlist(l)")
1686 function calls (1290 primitive calls) in 0.001 seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
397/1 0.001 0.000 0.001 0.001 <ipython-input-55-39b139bad497>:4(flattenlist)
1 0.000 0.000 0.001 0.001 <string>:1(<module>)
1287 0.000 0.000 0.000 0.000 {isinstance}
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
l=[[1,2,3],[4,5,6], [7], [8,9]]*132
run("flattenlist(l)")
2247 function calls (1719 primitive calls) in 0.002 seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
529/1 0.001 0.000 0.002 0.002 <ipython-input-55-39b139bad497>:4(flattenlist)
1 0.000 0.000 0.002 0.002 <string>:1(<module>)
1716 0.001 0.000 0.001 0.000 {isinstance}
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
l=[[1,2,3],[4,5,6], [7], [8,9]]*1320
run("flattenlist(l)")
22443 function calls (17163 primitive calls) in 0.016 seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
5281/1 0.011 0.000 0.016 0.016 <ipython-input-55-39b139bad497>:4(flattenlist)
1 0.000 0.000 0.016 0.016 <string>:1(<module>)
17160 0.005 0.000 0.005 0.000 {isinstance}
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
So zu testen, wie effektiv es ist, wenn rekursive tiefer wird: Wie viel tiefer
l=[[1,2,3],[4,5,6], [7], [8,9]]*1320
new=[l]*33
run("flattenlist(new)")
740589 function calls (566316 primitive calls) in 0.418 seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
174274/1 0.281 0.000 0.417 0.417 <ipython-input-55-39b139bad497>:4(flattenlist)
1 0.001 0.001 0.418 0.418 <string>:1(<module>)
566313 0.136 0.000 0.136 0.000 {isinstance}
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
new=[l]*66
run("flattenlist(new)")
1481175 function calls (1132629 primitive calls) in 0.809 seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
348547/1 0.542 0.000 0.807 0.807 <ipython-input-55-39b139bad497>:4(flattenlist)
1 0.002 0.002 0.809 0.809 <string>:1(<module>)
1132626 0.266 0.000 0.266 0.000 {isinstance}
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
new=[l]*99
run("flattenlist(new)")
2221761 function calls (1698942 primitive calls) in 1.211 seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
522820/1 0.815 0.000 1.208 1.208 <ipython-input-55-39b139bad497>:4(flattenlist)
1 0.002 0.002 1.211 1.211 <string>:1(<module>)
1698939 0.393 0.000 0.393 0.000 {isinstance}
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
new=[l]*132
run("flattenlist(new)")
2962347 function calls (2265255 primitive calls) in 1.630 seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
697093/1 1.091 0.000 1.627 1.627 <ipython-input-55-39b139bad497>:4(flattenlist)
1 0.003 0.003 1.630 1.630 <string>:1(<module>)
2265252 0.536 0.000 0.536 0.000 {isinstance}
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
new=[l]*1320
run("flattenlist(new)")
29623443 function calls (22652523 primitive calls) in 16.103 seconds
Ordered by: standard name
ncalls tottime percall cumtime percall filename:lineno(function)
6970921/1 10.842 0.000 16.069 16.069 <ipython-input-55-39b139bad497>:4(flattenlist)
1 0.034 0.034 16.103 16.103 <string>:1(<module>)
22652520 5.227 0.000 5.227 0.000 {isinstance}
1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}
Ich wette „flattenlist“ ich dies eher als matploblib für eine lange lange Zeit nutzen werde, wenn ich einen Ertrag Generator und schnelles Ergebnis als „flach“ verwendet in matploblib.cbook
willDies ist schnell.
- Und hier ist der Code
typ=(list,tuple)
def flattenlist(d):
thelist = []
for x in d:
if not isinstance(x,typ):
thelist += [x]
else:
thelist += flattenlist(x)
return thelist
Diese Version ist ein generator.Tweak es, wenn Sie eine Liste aus.
def list_or_tuple(l):
return isinstance(l,(list,tuple))
## predicate will select the container to be flattened
## write your own as required
## this one flattens every list/tuple
def flatten(seq,predicate=list_or_tuple):
## recursive generator
for i in seq:
if predicate(seq):
for j in flatten(i):
yield j
else:
yield i
Sie können ein Prädikat hinzufügen, wenn diese glätten wollen, die eine Bedingung erfüllen
Entnommen aus Python Kochbuch
Aus meiner Erfahrung ist der effizienteste Weg, um eine Liste von Listen zu glätten ist:
flat_list = []
map(flat_list.extend, list_of_list)
Einige timeit Vergleiche mit den anderen vorgeschlagenen Methoden:
list_of_list = [range(10)]*1000
%timeit flat_list=[]; map(flat_list.extend, list_of_list)
#10000 loops, best of 3: 119 µs per loop
%timeit flat_list=list(itertools.chain.from_iterable(list_of_list))
#1000 loops, best of 3: 210 µs per loop
%timeit flat_list=[i for sublist in list_of_list for i in sublist]
#1000 loops, best of 3: 525 µs per loop
%timeit flat_list=reduce(list.__add__,list_of_list)
#100 loops, best of 3: 18.1 ms per loop
Nun erscheint der Effizienzgewinn besser, wenn mehr Sublisten Verarbeitung:
list_of_list = [range(1000)]*10
%timeit flat_list=[]; map(flat_list.extend, list_of_list)
#10000 loops, best of 3: 60.7 µs per loop
%timeit flat_list=list(itertools.chain.from_iterable(list_of_list))
#10000 loops, best of 3: 176 µs per loop
Und diese Methoden funktionieren auch mit jedem iterativen Objekt:
class SquaredRange(object):
def __init__(self, n):
self.range = range(n)
def __iter__(self):
for i in self.range:
yield i**2
list_of_list = [SquaredRange(5)]*3
flat_list = []
map(flat_list.extend, list_of_list)
print flat_list
#[0, 1, 4, 9, 16, 0, 1, 4, 9, 16, 0, 1, 4, 9, 16]
Hier ist eine Version arbeitet für mehrere Ebenen der Liste mit collectons.Iterable:
import collections
def flatten(o, flatten_condition=lambda i: isinstance(i,
collections.Iterable) and not isinstance(i, str)):
result = []
for i in o:
if flatten_condition(i):
result.extend(flatten(i, flatten_condition))
else:
result.append(i)
return result
Was ist mit:
from operator import add
reduce(add, map(lambda x: list(x.image_set.all()), [mi for mi in list_of_menuitems]))
Aber Guido empfiehlt gegen zu viel Durchführen in einer einzigen Codezeile, da es die Lesbarkeit verringert. Es ist minimal, wenn überhaupt, Leistungsgewinn durch die Durchführung, was Sie in einer einzigen Zeile gegen mehrere Zeilen mögen.
pylab einen Flatten: Link zu numpy Flatten
Wenn Sie suchen einen eingebauten, einfachen, Einzeiler können Sie:
a = [[1, 2, 3], [4, 5, 6]
b = [i[x] for i in a for x in range(len(i))]
print b
Rückkehr
[1, 2, 3, 4, 5, 6]
Wenn Sie zu Flach einer komplizierteren Liste mit nicht iterable Elementen oder mit einer Tiefe von mehr als 2 Sie folgenden Funktion verwenden können:
def flat_list(list_to_flat):
if not isinstance(list_to_flat, list):
yield list_to_flat
else:
for item in list_to_flat:
yield from flat_list(item)
Es wird ein Generator-Objekt zurück, das Sie auf eine Liste mit list() Funktion umwandeln kann. Beachten Sie, dass yield from Syntax von python3.3 verfügbar beginnen, aber Sie können stattdessen explizite Iteration verwenden.
Beispiel:
>>> a = [1, [2, 3], [1, [2, 3, [1, [2, 3]]]]]
>>> print(list(flat_list(a)))
[1, 2, 3, 1, 2, 3, 1, 2, 3]
def is_iterable(item):
return isinstance(item, list) or isinstance(item, tuple)
def flatten(items):
for i in items:
if is_iterable(item):
for m in flatten(i):
yield m
else:
yield i
Test:
print list(flatten2([1.0, 2, 'a', (4,), ((6,), (8,)), (((8,),(9,)), ((12,),(10)))]))
Wenn jedes Element in der Liste ist ein String (und alle Strings innerhalb dieser Zeichenfolge verwenden „“ und nicht als ' ‚), können Sie reguläre Ausdrücke verwenden (re Modul)
>>> flattener = re.compile("\'.*?\'")
>>> flattener
<_sre.SRE_Pattern object at 0x10d439ca8>
>>> stred = str(in_list)
>>> outed = flattener.findall(stred)
Der obige Code in_list in einen String konvertiert, verwendet die regex alle Teilstrings in Anführungszeichen zu finden (das heißt jedes Element der Liste) und spuckt sie als eine Liste aus.
Eine einfache Alternative zu benutzen numpy der concatenate aber es wandelt den Inhalt zu schweben:
import numpy as np
print np.concatenate([[1,2],[3],[5,89],[],[6]])
# array([ 1., 2., 3., 5., 89., 6.])
print list(np.concatenate([[1,2],[3],[5,89],[],[6]]))
# [ 1., 2., 3., 5., 89., 6.]
Der einfachste Weg, diese 2 oder 3 in entweder Python zu erreichen, ist die Morph Bibliothek zu verwenden, mit pip install morph .
Der Code lautet:
import morph
list = [[1,2],[3],[5,89],[],[6]]
flattened_list = morph.flatten(list) # returns [1, 2, 3, 5, 89, 6]
In Python 3.4 können Sie tun:
[*innerlist for innerlist in outer_list]
