https://stackoverflow.com/questions/19738977
https://stackoverflow.com/questions/19738977
 italiano
italiano english
english français
français española
española 中国
中国 日本の
日本の العربية
العربية Deutsch
Deutsch 한국어
한국어 Português
Português Russian
RussianSo, it has an array of
Entryobjects.
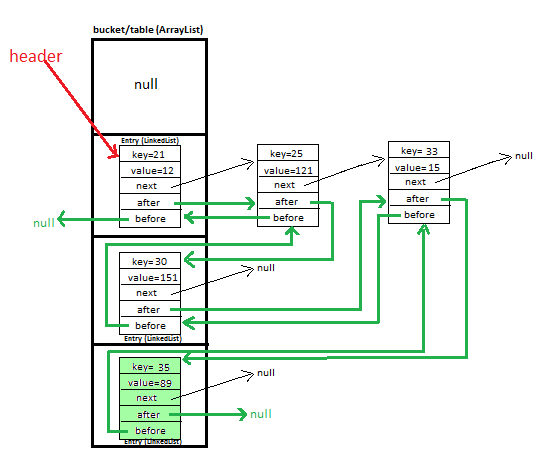
Not exactly. It has an array of Entry object chains. A HashMap.Entry object has a next field allowing the Entry objects to be chained as a linked list.
I was wondering how can an index of this array store multiple
Entryobjects in case of same hashCode but different objects.
Because (as the picture in your question shows) the Entry objects are chained.
How is this different from
LinkedHashMapimplementation? Its doubly linked list implementation of map but does it maintain an array like the above and how does it store pointers to the next and previous element?
In the LinkedHashMap implementation, the LinkedHashMap.Entry class extends the HashMap.Entry class, by adding before and after fields. These fields are used to assemble the LinkedHashMap.Entry objects into an independent doubly-linked list that records the insertion order. So, in the LinkedHashMap class, each entry object is in two distinct chains:
There are a number of singly linked hash chains that is accessed via the main hash array. This is used for (regular) hashmap lookups.
There is a separate doubly linked list that contains all of the entry objects. It is kept in entry insertion order, and is used when you iterate the entries, keys or values in the hashmap.