I've had this question for months. It seems like we just cleverly guessed the softmax as an output function and then interpret the input to the softmax as log-probabilities. As you said, why not simply normalize all outputs by dividing by their sum? I found the answer in the Deep Learning book by Goodfellow, Bengio and Courville (2016) in section 6.2.2.
Let's say our last hidden layer gives us z as an activation. Then the softmax is defined as

Very Short Explanation
The exp in the softmax function roughly cancels out the log in the cross-entropy loss causing the loss to be roughly linear in z_i. This leads to a roughly constant gradient, when the model is wrong, allowing it to correct itself quickly. Thus, a wrong saturated softmax does not cause a vanishing gradient.
Short Explanation
The most popular method to train a neural network is Maximum Likelihood Estimation. We estimate the parameters theta in a way that maximizes the likelihood of the training data (of size m). Because the likelihood of the whole training dataset is a product of the likelihoods of each sample, it is easier to maximize the log-likelihood of the dataset and thus the sum of the log-likelihood of each sample indexed by k:
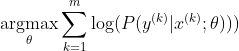
Now, we only focus on the softmax here with z already given, so we can replace
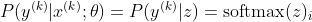
with i being the correct class of the kth sample. Now, we see that when we take the logarithm of the softmax, to calculate the sample's log-likelihood, we get:
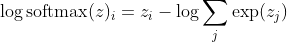
, which for large differences in z roughly approximates to
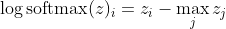
First, we see the linear component z_i here. Secondly, we can examine the behavior of max(z) for two cases:
- If the model is correct, then max(z) will be z_i. Thus, the log-likelihood asymptotes zero (i.e. a likelihood of 1) with a growing difference between z_i and the other entries in z.
- If the model is incorrect, then max(z) will be some other z_j > z_i. So, the addition of z_i does not fully cancel out -z_j and the log-likelihood is roughly (z_i - z_j). This clearly tells the model what to do to increase the log-likelihood: increase z_i and decrease z_j.
We see that the overall log-likelihood will be dominated by samples, where the model is incorrect. Also, even if the model is really incorrect, which leads to a saturated softmax, the loss function does not saturate. It is approximately linear in z_j, meaning that we have a roughly constant gradient. This allows the model to correct itself quickly. Note that this is not the case for the Mean Squared Error for example.
Long Explanation
If the softmax still seems like an arbitrary choice to you, you can take a look at the justification for using the sigmoid in logistic regression:
Why sigmoid function instead of anything else?
The softmax is the generalization of the sigmoid for multi-class problems justified analogously.
 https://stackoverflow.com/questions/17187507
https://stackoverflow.com/questions/17187507
 italiano
italiano english
english français
français española
española 中国
中国 日本の
日本の العربية
العربية Deutsch
Deutsch 한국어
한국어 Português
Português Russian
Russian



