https://stackoverflow.com/questions/17306273
https://stackoverflow.com/questions/17306273
 italiano
italiano english
english français
français española
española 中国
中国 日本の
日本の العربية
العربية Deutsch
Deutsch 한국어
한국어 Português
Português Russian
RussianHere is a very good tutorial on regular expressions you might want to check out. The article on quantifiers has two sections "Laziness instead of Greediness" and "An Alternative to Laziness", that should explain this particular example really well.
Anyway, here is my explanation. First, you need to realize that there are two compilation steps in Java. One compiles the string literal in your code to an actual string. This step already interprets some of the backslashes, so that the string Java receives looks like
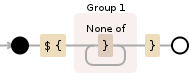
\$\{([^}]+)\}
Now let's pick that apart in free-spacing mode:
\$ # match a literal $
\{ # match a literal {
( # start capturing group 1
[^}] # match any single character except } - note the negation by ^
+ # repeat one or more times
) # end of capturing group 1
\} # match a literal }
So this really matches all occurrences of ${...}, where ... can be anything except closing }. The contents of the braces (i.e. the ...) can later be accessed via m.group(1), as it's the first set of parentheses in the expression.
Here are some more relevant articles of the above tutorial (but you should really read it in its entirety - it's definite worth it):
- Character classes (including how to negate them with
^) - Repetition/quantifiers
- Grouping and capturing
- Java's regex peculiarities