 https://stackoverflow.com/questions/17719341
https://stackoverflow.com/questions/17719341
 italiano
italiano english
english français
français española
española 中国
中国 日本の
日本の العربية
العربية Deutsch
Deutsch 한국어
한국어 Português
Português Russian
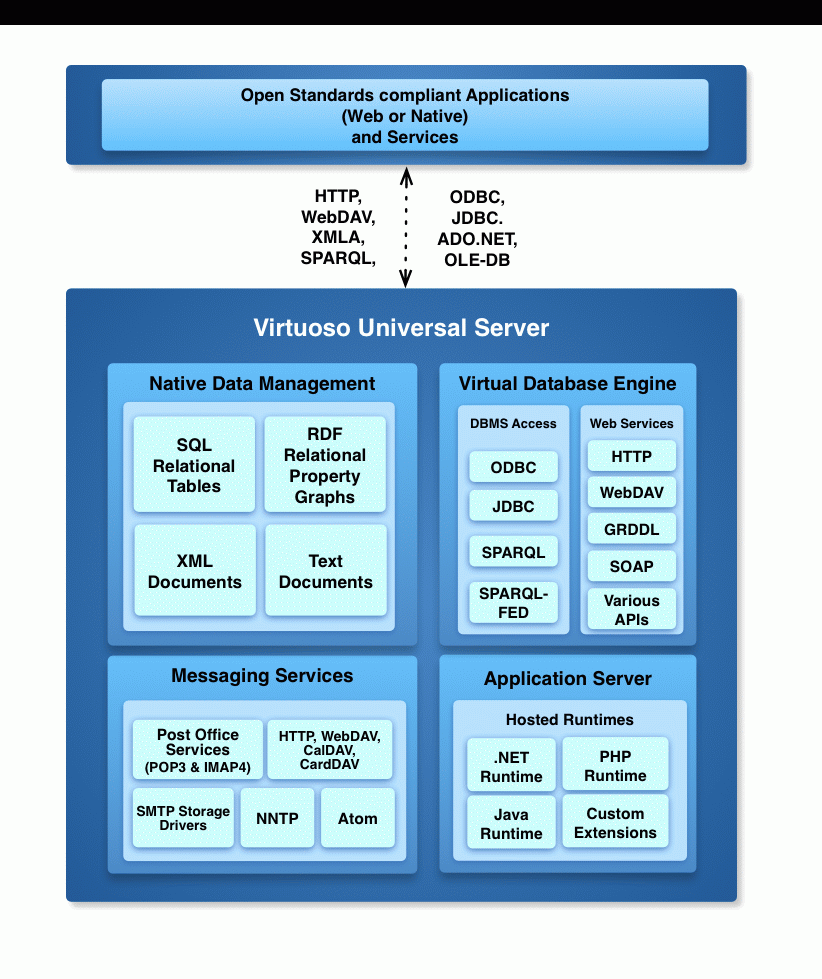
RussianVirtuoso is in fact a whole suite of applications and service layers built on top of their own SQL database hence the understandable confusion.
The Native RDF Quad Store is Virtuoso's own quad store implementation which ironically enough as you point out is actually SQL based. This is stored and implemented entirely within Virtuoso's own SQL database implementation. Thus although it is SQL based it has a fixed table layout and makes use of custom data types to store the data.
The SQL Based RDF Triple Store refers to a feature of commercial versions of Virtuoso which allows you to define mapping rules to treat arbitrary normal relational databases (both Virtuoso based and other backend based e.g. MySql, PostgreSQL) as an RDF store.
Performance Differences
The performance difference comes from the fact that the Native Quad store has a known layout, custom RDF data types and lots of software optimizations specific to it within Virtuoso's stack. Therefore when Virtuoso takes in SPARQL and compiles it to an equivalent SQL query it runs extremely efficiently on their database. The use of custom RDF data types allows them to push all the SPARQL logic down into the query engine layer which also makes evaluation faster.
For the SQL Based Triple store there is a mapping layer involved, they have to call out to the SQL database (which may be external) and translate its content into RDF form in order to then do the computations necessary to answer the SPARQL queries. The mapping step can be extremely costly and it makes queries harder to optimize because they have access to less up front information about the RDF data.
Plus since the data is often just in standard SQL types they can't push down certain logic to the underlying query engine because the SQL and SPARQL type semantics don't align in many cases. Therefore the values have to be extracted, converted appropriately and then expression results computed above the query engine layer and then fed back in as necessary. This reduces performance because the engine has to switch between different processing contexts and potentially make many SQL queries to answer the same SPARQL query.

{kind=link}