 https://stackoverflow.com/questions/23082058
https://stackoverflow.com/questions/23082058
 italiano
italiano english
english français
français española
española 中国
中国 日本の
日本の العربية
العربية Deutsch
Deutsch 한국어
한국어 Português
Português Russian
Russian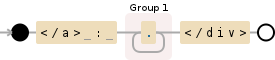
By default, the + quantifier is greedy, meaning (loosely) that it will match as much as it can while the regex returns a overall match.
For example, .+</div> will match abc</div>efg in abc</div>efg</div>: each character in the </div> string can be matched by the dot . and the greedy quantifier eats up as much as possible.
What you want to do is either make it lazy, so that it matches the least amount possible, with +?:
</a> : (.+?)</div>
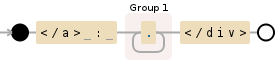
Or, if you know your text can't contain <, use [^<] (ie anything except a <) instead of a .: that way [^<]+ can't eat up </div>:
</a> : ([^<]+)</div>
Your regex was previously working because the dot . by default doesn't match newlines. On a side note, no need to escape everything in your regex...

