 https://stackoverflow.com/questions/23221483
https://stackoverflow.com/questions/23221483
 italiano
italiano english
english français
français española
española 中国
中国 日本の
日本の العربية
العربية Deutsch
Deutsch 한국어
한국어 Português
Português Russian
RussianA regular expression like this may work for you?
In my test it worked with the text example you gave however it is not very advanced. It will simple select all characters after http:// or https:// until a white-space character occures (space, new line, tab, etc).
/(https?\:\/\/(?:[^\s]+))/gi
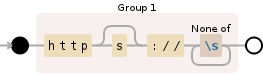
Here is a visual example of what would be matched from your sample string:
http://regex101.com/r/bR0yE9
