 https://stackoverflow.com/questions/23684844
https://stackoverflow.com/questions/23684844
 italiano
italiano english
english français
français española
española 中国
中国 日本の
日本の العربية
العربية Deutsch
Deutsch 한국어
한국어 Português
Português Russian
RussianBased on what i understood from the comments underneath the question, the example data given in the question should be transformed into two text lines like this:
Zoning Letter;4/16/2014;355211;712826;102;367;0;261711;0;1;0;0;16;0;2;0;0;\V367\2855\1558564.PDF
Zoning Letter;4/16/2014;355211;712825;102;367;0;19441;0;1;0;0;16;0;2;0;0;\V367\2855\1558563.pdf
To achieve this result while avoiding a loop (although i wonder why you would want to avoid loops - they are basic and omni-present constructs), i would suggest applying two (or three, see section 3. below) regex substitutions.
1. Removal of "Label:" and replacement of line breaks with ";"
The first regular expression will remove a label in front of ":" including ":" and any preceding line break with a semicolon. However, it will not remove or replace a line break in front of "BEGIN:", and neither will it touch the "BEGIN:" itself.
@"(([\r\n]+\s*Ad\sHoc:.*?[\r\n]+)|([\r\n]+(?!\s*BEGIN))).*?:\s*"
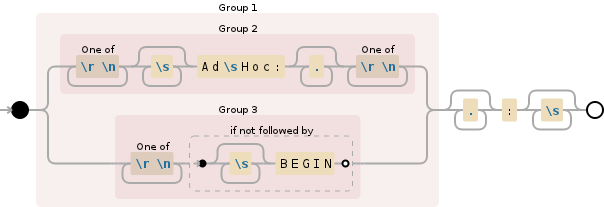
This regex is an OR-combination of two regex (which is easy to see in the visualization above):
[\r\n]+\s*Ad\sHoc:.*?[\r\n]+.*?:\s*
which will match Ad Hoc:" lines including any "Label:" string in the following line, and
([\r\n]+(?!\s*BEGIN)).*?:\s*
which will match any "Label:" including the line break in front of it, except for the "BEGIN:" label.
Applying this regex to your example and replacing all matches with ";" will result in the following:
BEGIN:;Zoning Letter;4/16/2014;355211;712826;102;367;0;261711;0;1;0;0;16;0;2;0;0;\V367\2855\1558564.PDF
BEGIN:;Zoning Letter;4/16/2014;355211;712825;102;367;0;19441;0;1;0;0;16;0;2;0;0;\V367\2855\1558563.pdf
Note the "BEGIN:;" which we will take care of now.
2. Elimination of the "BEGIN:" labels
This is rather simple pattern when looking at the result of the first regex substitution.
"(?m)^BEGIN:;"
You might think that you can do this through a string replacement - and so did i when writing the first version of my answer. However, a mere string replacement would become a problem when "BEGIN:;" could be part of the content of any other text field. Better to be correct and safe by specifying a regex which matches only at the beginning of a line.
3. Code example, including elimination of empty lines in the source text
If you have empty lines containing white-spaces in the source text, the regular expression displayed above might not work properly. The solution is to do another regex substitution beforehand, which reduces empty lines (including white-spaces) to a single line break (if you are certain that your source data does not contain empty lines, you can omit this step).
A complete code example, which would produce the result as mentioned at the beginning of my answer, could look like this:
string sourceData = ... your text with the source data ...
Regex reEmptyLines = new Regex(@"[\s\r\n]+[\r\n]", RegexOptions.Compiled);
Regex reSemicolons = new Regex(@"(([\r\n]+\s*Ad\sHoc:.*?[\r\n]+)|([\r\n]+(?!\s*BEGIN))).*?:\s*", RegexOptions.Compiled);
Regex reBegin = new Regex("(?m)^BEGIN:;", RegexOptions.Compiled);
string processed =
reBegin.Replace(
reSemicolons.Replace(
reEmptyLines.Replace(sourceData, "\r\n"),
";"
),
string.Empty
);

