Does AMD's OpenCL offer something similar to CUDA's GPUDirect?
 https://stackoverflow.com/questions/9287346
https://stackoverflow.com/questions/9287346
 italiano
italiano english
english français
français española
española 中国
中国 日本の
日本の العربية
العربية Deutsch
Deutsch 한국어
한국어 Português
Português Russian
Russian문제
NVIDIA offers GPUDirect to reduce memory transfer overheads. I'm wondering if there is a similar concept for AMD/ATI? Specifically:
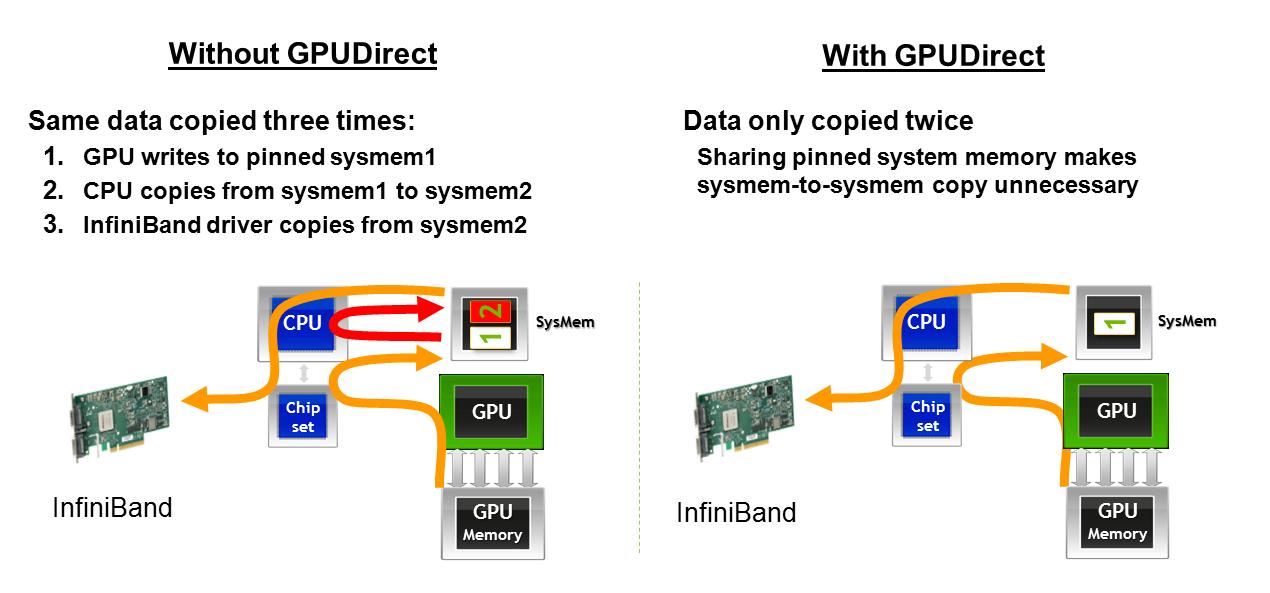
1) Do AMD GPUs avoid the second memory transfer when interfacing with network cards, as described here. In case the graphic is lost at some point, here is a description of the impact of GPUDirect on getting data from a GPU on one machine to be transferred across a network interface: With GPUDirect, GPU memory goes to Host memory then straight to the network interface card. Without GPUDirect, GPU memory goes to Host memory in one address space, then the CPU has to do a copy to get the memory into another Host memory address space, then it can go out to the network card.
2) Do AMD GPUs allow P2P memory transfers when two GPUs are shared on the same PCIe bus, as described here. In case the graphic is lost at some point, here is a description of the impact of GPUDirect on transferring data between GPUs on the same PCIe bus: With GPUDirect, data can move directly between GPUs on the same PCIe bus, without touching host memory. Without GPUDirect, data always has to go back to the host before it can get to another GPU, regardless of where that GPU is located.
Edit: BTW, I'm not entirely sure how much of GPUDirect is vaporware and how much of it is actually useful. I've never actually heard of a GPU programmer using it for something real. Thoughts on this are welcome too.
해결책
I think you may be looking for the CL_MEM_ALLOC_HOST_PTR flag in clCreateBuffer. While the OpenCL specification states that this flag "This flag specifies that the application wants the OpenCL implementation to allocate memory from host accessible memory", it is uncertain what AMD's implementation (or other implementations) might do with it.
Here's an informative thread on the topic http://www.khronos.org/message_boards/viewtopic.php?f=28&t=2440
Hope this helps.
Edit: I do know that nVidia's OpenCL SDK implements this as allocation in pinned/page-locked memory. I am fairly certain this is what AMD's OpenCL SDK does when running on the GPU.
다른 팁
Although this question is pretty old, I would like to add my answer as I believe the current information here is incomplete.
As stated in the answer by @Ani, you could allocate a host memory using CL_MEM_ALLOC_HOST_PTR and you will most likely get a pinned host memory that avoids the second copy depending on the implementation. For instance, NVidia OpenCL Best Practices Guide states:
OpenCL applications do not have direct control over whether memory objects are allocated in pinned memory or not, but they can create objects using the CL_MEM_ALLOC_HOST_PTR flag and such objects are likely to be allocated in pinned memory by the driver for best performance
The thing I find missing from previous answers is the fact that AMD offers DirectGMA technology. This technology enables you to transfer data between the GPU and any other peripheral on the PCI bus (including other GPUs) directly witout having to go through system memory. It is more similar to NVidia's RDMA (not available on all platforms).
In order to use this technology you must:
have a compatible AMD GPU (not all of them support DirectGMA). you can use either OpenCL, DirectX or OpenGL extentions provided by AMD.
have the peripheral driver (network card, video capture card etc) either expose a physical address to which the GPU DMA engine can read/write from/to. Or be able to program the peripheral DMA engine to transfer data to / from the GPU exposed memory.
I used this technology to transfer data directly from video capture devices to the GPU memory and from the GPU memory to a proprietary FPGA. Both cases were very efficent and did not involve any extra copying.
As pointed out by @ananthonline and @harrism, many of the features of GPUDirect have no direct equivalent in OpenCL. However, if you are trying to reduce memory transfer overhead, as mentioned in the first sentence of your question, zero copy memory might help. Normally, when an application creates a buffer on the GPU, the contents of the buffer are copied from CPU memory to GPU memory en masse. With zero copy memory, there is no upfront copy; instead, data is copied over as it is accessed by the GPU kernel.
Zero copy does not make sense for all applications. Here is advice from the AMD APP OpenCL Programming Guide on when to use it:
Zero copy host resident memory objects can boost performance when host memory is accessed by the device in a sparse manner or when a large host memory buffer is shared between multiple devices and the copies are too expensive. When choosing this, the cost of the transfer must be greater than the extra cost of the slower accesses.
Table 4.3 of the Programming Guide describes which flags to pass to clCreateBuffer to take advantage of zero copy (either CL_MEM_ALLOC_HOST_PTR or CL_MEM_USE_PERSISTENT_MEM_AMD, depending on whether you want device-accessible host memory or host-accessible device memory). Note that zero copy support is dependent on both the OS and the hardware; it appears to not be supported under Linux or older versions of Windows.
AMD APP OpenCL Programming Guide: http://developer.amd.com/sdks/AMDAPPSDK/assets/AMD_Accelerated_Parallel_Processing_OpenCL_Programming_Guide.pdf

{kind=link}
{kind=link}