SQLite - UPSERT * nicht * INSERT oder REPLACE
 https://stackoverflow.com/questions/418898
https://stackoverflow.com/questions/418898
 italiano
italiano english
english français
français española
española 中国
中国 日本の
日本の العربية
العربية Deutsch
Deutsch 한국어
한국어 Português
Português Russian
RussianFrage
http://en.wikipedia.org/wiki/Upsert
Insert-Update gespeicherte Prozedur auf SQL Server
Gibt es eine clevere Möglichkeit, dies in SQLite zu tun, dass ich nicht gedacht habe?
Grundsätzlich möchte ich drei von vier Spalten aktualisieren, wenn der Datensatz vorhanden ist, Wenn es nicht existiert ich die Platte mit dem Standard (NUL) Wert für die vierte Spalte eingefügt werden soll.
Die ID ist ein Primärschlüssel so wird es immer nur ein Datensatz zu UPSERT sein.
(Ich versuche, den Overhead von SELECT, um zu determin zu vermeiden, wenn ich brauche offensichtlich zu aktualisieren oder einfügen)
Verbesserungsvorschläge?
Ich kann nicht bestätigen, dass Syntax auf der SQLite Website für CREATE TABLE. Ich habe nicht eine Demo gebaut, es zu testen, aber es tut unterstützt zu werden scheint ..
Wenn es ist, ich habe drei Spalten, so dass es tatsächlich aussehen würde:
CREATE TABLE table1(
id INTEGER PRIMARY KEY ON CONFLICT REPLACE,
Blob1 BLOB ON CONFLICT REPLACE,
Blob2 BLOB ON CONFLICT REPLACE,
Blob3 BLOB
);
aber die ersten beiden Blobs keinen Konflikt verursachen, nur die ID würde So asusme ich Blob1 und Blob2 würde nicht ersetzt werden (wie gewünscht)
UPDATEs in SQLite, wenn Bindungsdaten sind eine komplette Transaktion, was bedeutet, Jede Zeile gesendet aktualisiert werden muss: Vorbereiten / Heftung / Step / finalisieren Aussagen im Gegensatz zu dem INSERT, die die Verwendung der Reset-Funktion
erlaubtDas Leben eines Statement-Objekt geht in etwa so:
- Erstellen Sie das Objekt mit sqlite3_prepare_v2 ()
- Bind Werte Parameter mit sqlite3_bind_ Schnittstellen hosten.
- Führen Sie den SQL durch den Aufruf sqlite3_step ()
- Setzen Sie die Anweisung sqlite3_reset (), dann gehen Sie zurück zu Schritt 2 und wiederholen.
- Zerstört die Anweisung Objekt mit sqlite3_finalize ().
UPDATE ich raten bin, ist langsam im Vergleich zu INSERT, aber wie es mit dem Primärschlüssel SELECT nicht zu vergleichen?
Vielleicht soll ich die select verwenden, um die vierte Spalte (Blob3) zu lesen und ersetzen Sie dann verwenden, um einen neuen Datensatz Mischen die ursprüngliche 4. Spalte mit den neuen Daten für die ersten 3 Spalten zu schreiben?
Lösung
Unter der Annahme, 3 Spalten in der Tabelle .. ID, Name, Rolle
BAD: Es werden alle Spalten mit neuen Werten für ID einfügen oder ersetzen = 1:
INSERT OR REPLACE INTO Employee (id, name, role)
VALUES (1, 'John Foo', 'CEO');
BAD: Dies wird 2 der Spalten einfügen oder ersetzen ... die Spalte NAME eingestellt wird auf NULL oder den Standardwert:
INSERT OR REPLACE INTO Employee (id, role)
VALUES (1, 'code monkey');
GUT: Dies wird 2 der Spalten aktualisieren. Wenn ID = 1 existiert, wird der Name nicht betroffen. Wenn ID = 1 nicht vorhanden ist, wird der Name default (NULL) sein.
INSERT OR REPLACE INTO Employee (id, role, name)
VALUES ( 1,
'code monkey',
(SELECT name FROM Employee WHERE id = 1)
);
Dies wird 2 der Spalten aktualisieren. Wenn ID = 1 vorhanden ist, wird die Rolle nicht betroffen. Wenn ID = 1 nicht vorhanden ist, wird die Rolle zu ‚Benchwarmer‘ anstelle des Standardwerts eingestellt werden.
INSERT OR REPLACE INTO Employee (id, name, role)
VALUES ( 1,
'Susan Bar',
COALESCE((SELECT role FROM Employee WHERE id = 1), 'Benchwarmer')
);
Andere Tipps
INSERT OR REPLACE ist nicht äquivalent zu "UPSERT".
Sagen, dass ich die Tabelle Mitarbeiter mit den Feldern ID, Namen, und Rolle:
INSERT OR REPLACE INTO Employee ("id", "name", "role") VALUES (1, "John Foo", "CEO")
INSERT OR REPLACE INTO Employee ("id", "role") VALUES (1, "code monkey")
Boom, haben Sie den Namen des Mitarbeiters Nummer verloren 1. SQLite es mit einem Standardwert ersetzt.
Die erwartete Ausgabe eines UPSERT wäre, die Rolle zu ändern und den Namen zu halten.
Eric B Antwort ist OK, wenn Sie nur ein oder vielleicht zwei Spalten aus dem bestehenden bewahren wollen Reihe. Wenn Sie eine Menge von Spalten erhalten wollen, wird es zu umständlich schnell.
Hier ist ein Ansatz, der auch auf jede Menge von Spalten auf jeder Seite skaliert. Zur Veranschaulichung wird es ich folgendes Schema übernehmen:
CREATE TABLE page (
id INTEGER PRIMARY KEY,
name TEXT UNIQUE,
title TEXT,
content TEXT,
author INTEGER NOT NULL REFERENCES user (id),
ts TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
Beachten Sie insbesondere, dass name ist der natürliche Schlüssel der Zeile - id nur für Fremdschlüssel verwendet wird, so ist der Punkt für SQLite den ID-Wert selbst zu wählen, wenn eine neue Zeile einzufügen. Aber wenn eine bestehende Reihe Aktualisierung auf der Grundlage seiner name, ich will es den alten ID-Wert zu haben, fortzusetzen (natürlich!).
ich eine wahre UPSERT mit dem folgende Konstrukt erreicht werden:
WITH new (name, title, author) AS ( VALUES('about', 'About this site', 42) )
INSERT OR REPLACE INTO page (id, name, title, content, author)
SELECT old.id, new.name, new.title, old.content, new.author
FROM new LEFT JOIN page AS old ON new.name = old.name;
Die genaue Form dieser Abfrage kann ein wenig variieren. Der Schlüssel ist die Verwendung von INSERT SELECT mit einem linken äußeren Verknüpfung, eine bestehende Reihe auf die neuen Werte zu verbinden.
Wenn hier eine Reihe vorher nicht vorhanden ist, wird old.id werden NULL und SQLite wird dann automatisch eine ID zuweisen, aber wenn es bereits eine solche Reihe war, old.id wird einen tatsächlichen Wert haben und diese wiederverwendet werden. Das ist genau das, was ich wollte.
In der Tat ist dies sehr flexibel. Beachten Sie, wie die ts Säule ist auf allen Seiten vollständig fehlt -. Weil es einen DEFAULT Wert hat, wird SQLite tun genau das Richtige in jedem Fall, so dass ich nicht kümmern muß es selbst
Sie können auch eine Spalte auf beiden new und old Seiten und verwenden Sie dann z.B. COALESCE(new.content, old.content) im äußeren SELECT zu sagen, „die neuen Inhalte einfügen, wenn es eine ist, sonst den alten Inhalt halten“ - z.B. wenn Sie eine feste Abfrage verwenden und binden die neuen Werte mit Platzhalter.
Wenn Sie in der Regel Updates tun würde ich ..
- Starten Sie eine Transaktion
- Sie das Update
- Überprüfen Sie die rowcount
- Wenn es 0 ist tun, den Einsatz
- Commit
Wenn Sie in der Regel Einsätze tun würde ich
- Starten Sie eine Transaktion
- Versuchen Sie, einen Einsatz
- Überprüfen Sie für die Primärschlüsselverletzung Fehler
- , wenn wir haben einen Fehler machen das Update
- Commit
Auf diese Weise vermeiden Sie die Auswahl und Sie sind transaktions Sound auf SQLite.
Diese Antwort aktualisiert hat und so die Kommentare unten nicht mehr gelten.
2018.05.18 MELDUNG.
UPSERT Unterstützung in SQLite! UPSERT Syntax wurde hinzugefügt mit der Version 3.24 auf SQLite. 0 (pending)!
UPSERT ist eine spezielle Syntax zusätzlich zu INSERT, die die INSERT bewirkt als UPDATE oder einen No-op verhalten, wenn die INSERT eine Eindeutigkeitsbedingung verletzen würde. UPSERT ist nicht Standard-SQL. UPSERT in SQLite folgt die Syntax von PostgreSQL etabliert.

alternativ:
Eine weitere ganz andere Art und Weise, dies zu tun ist: In meiner Anwendung ich im Speicher gesetzt rowID long.MaxValue zu sein, wenn ich die Zeile im Speicher erstellen. (MaxValue wird nie als ID verwendet werden, werden Sie nicht lange genug leben .... Dann, wenn rowID ist nicht dieser Wert dann muss es schon in der Datenbank vorhanden sein muss, um eine UPDATE wenn es MaxValue dann braucht es einen Einsatz. Dies ist nur dann sinnvoll, wenn Sie die ROWIDs in Ihrer App verfolgen können.
Ich weiß, das ein alter Thread, aber ich habe in sqlite3 als in der letzten Zeit gearbeitet und kam mit dieser Methode auf, die besser meine Bedürfnisse der dynamischen Generierung parametrisierte Abfragen geeignet:
insert or ignore into <table>(<primaryKey>, <column1>, <column2>, ...) values(<primaryKeyValue>, <value1>, <value2>, ...);
update <table> set <column1>=<value1>, <column2>=<value2>, ... where changes()=0 and <primaryKey>=<primaryKeyValue>;
Es ist immer noch 2 Abfragen mit einer where-Klausel auf dem Update aber scheint den Trick zu tun. Ich habe auch diese Vision in meinem Kopf, dass die Update-Anweisung vollständig, wenn der Anruf zu Änderungen () größer als Null sqlite kann optimieren entfernt. Unabhängig davon, ob es funktioniert tatsächlich, dass entzieht sich meiner Kenntnis, aber ein Mann träumen kann, kann er nicht? ;)
Für Bonuspunkte können Sie diese Zeile anhängen, die Sie die ID der Zeile zurückgibt, ob es sich um eine neu eingefügte Zeile oder eine bestehende Reihe sein.
select case changes() WHEN 0 THEN last_insert_rowid() else <primaryKeyValue> end;
Hier ist eine Lösung, die wirklich ein UPSERT ist (UPDATE oder INSERT) anstelle eine INSERT OR REPLACE (die unterschiedlich in vielen Situationen funktionieren).
Es funktioniert wie folgt:
1. Versuchen Sie, ob ein Datensatz mit der gleichen ID existiert zu aktualisieren.
2. Wenn das Update (NOT EXISTS(SELECT changes() AS change FROM Contact WHERE change <> 0)) brachte keine Zeilen ändern, dann den Datensatz eingefügt werden.
Also entweder ein vorhandener Datensatz aktualisiert wurde oder ein Einsatz wird durchgeführt werden.
Das wichtige Detail ist es, die Änderungen () SQL-Funktion zu verwenden, um zu überprüfen, ob die Update-Anweisung alle vorhandenen Datensätze getroffen und nur die Insert-Anweisung ausführen, wenn es keinen Datensatz getroffen hat.
Eine Sache zu erwähnen ist, dass die Änderungen () Funktion nicht Änderungen von untergeordneten Trigger ausgeführt zurückkehrt (siehe http://sqlite.org/lang_corefunc.html#changes ), so sicher sein, dass zu berücksichtigen.
Hier ist die SQL ...
Test Update:
--Create sample table and records (and drop the table if it already exists)
DROP TABLE IF EXISTS Contact;
CREATE TABLE [Contact] (
[Id] INTEGER PRIMARY KEY,
[Name] TEXT
);
INSERT INTO Contact (Id, Name) VALUES (1, 'Mike');
INSERT INTO Contact (Id, Name) VALUES (2, 'John');
-- Try to update an existing record
UPDATE Contact
SET Name = 'Bob'
WHERE Id = 2;
-- If no record was changed by the update (meaning no record with the same Id existed), insert the record
INSERT INTO Contact (Id, Name)
SELECT 2, 'Bob'
WHERE NOT EXISTS(SELECT changes() AS change FROM Contact WHERE change <> 0);
--See the result
SELECT * FROM Contact;
Testeinsatz:
--Create sample table and records (and drop the table if it already exists)
DROP TABLE IF EXISTS Contact;
CREATE TABLE [Contact] (
[Id] INTEGER PRIMARY KEY,
[Name] TEXT
);
INSERT INTO Contact (Id, Name) VALUES (1, 'Mike');
INSERT INTO Contact (Id, Name) VALUES (2, 'John');
-- Try to update an existing record
UPDATE Contact
SET Name = 'Bob'
WHERE Id = 3;
-- If no record was changed by the update (meaning no record with the same Id existed), insert the record
INSERT INTO Contact (Id, Name)
SELECT 3, 'Bob'
WHERE NOT EXISTS(SELECT changes() AS change FROM Contact WHERE change <> 0);
--See the result
SELECT * FROM Contact;
Sie können in der Tat eine Upsert in SQLite tun, es sieht nur ein wenig anders, als Sie es gewohnt sind. Es wäre in etwa so aussehen:
INSERT INTO table name (column1, column2)
VALUES ("value12", "value2") WHERE id = 123
ON CONFLICT DO UPDATE
SET column1 = "value1", column2 = "value2" WHERE id = 123
Die Erweiterung auf Aristoteles Antwort Sie können von einem Dummy-SELECT ‚Singleton‘ Tabelle (eine Tabelle von Ihrer eigenen Kreation mit einer einzigen Reihe ). Dies vermeidet einige Überschneidungen.
Ich habe immer auch das Beispiel tragbare über MySQL und SQLite und verwendet, um eine ‚DATE_ADDED‘ Säule als ein Beispiel dafür, wie Sie eine Spalte nur das erste Mal einstellen könnten.
REPLACE INTO page (
id,
name,
title,
content,
author,
date_added)
SELECT
old.id,
"about",
"About this site",
old.content,
42,
IFNULL(old.date_added,"21/05/2013")
FROM singleton
LEFT JOIN page AS old ON old.name = "about";
Ab Version 3.24.0 UPSERT wird von SQLite unterstützt.
Von den Dokumentation :
UPSERT ist eine spezielle Syntax zusätzlich zu INSERT, die die INSERT bewirkt als UPDATE oder einen No-op verhalten, wenn die INSERT eine Eindeutigkeitsbedingung verletzen würde. UPSERT ist nicht Standard-SQL. UPSERT in SQLite folgt die Syntax von PostgreSQL etabliert. UPSERT Syntax mit Version 3.24.0 SQLite wurde hinzugefügt (in Vorbereitung).
Ein UPSERT ist eine ganz normale INSERT-Anweisung, die durch die spezielle ON CONFLICT-Klausel
folgt
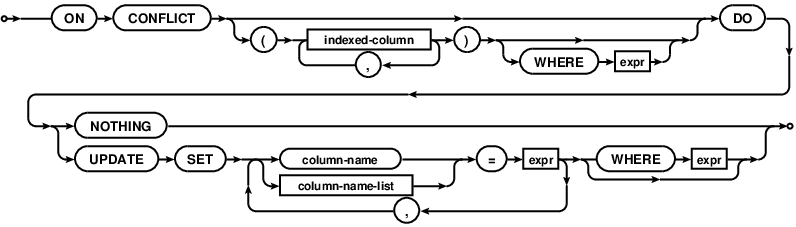
Bildquelle: https://www.sqlite.org /images/syntax/upsert-clause.gif
Der beste Ansatz, den ich weiß, ist ein Update zu tun, durch einen Einsatz gefolgt. Die „Overhead eines select“ ist notwendig, aber es ist nicht eine schreckliche Last, da Sie auf dem Primärschlüssel suchen, das schnell ist.
Sie sollten die folgenden Aussagen mit Ihrer Tabelle und Feldnamen zu ändern, in der Lage zu tun, was Sie wollen.
--first, update any matches
UPDATE DESTINATION_TABLE DT
SET
MY_FIELD1 = (
SELECT MY_FIELD1
FROM SOURCE_TABLE ST
WHERE ST.PRIMARY_KEY = DT.PRIMARY_KEY
)
,MY_FIELD2 = (
SELECT MY_FIELD2
FROM SOURCE_TABLE ST
WHERE ST.PRIMARY_KEY = DT.PRIMARY_KEY
)
WHERE EXISTS(
SELECT ST2.PRIMARY_KEY
FROM
SOURCE_TABLE ST2
,DESTINATION_TABLE DT2
WHERE ST2.PRIMARY_KEY = DT2.PRIMARY_KEY
);
--second, insert any non-matches
INSERT INTO DESTINATION_TABLE(
MY_FIELD1
,MY_FIELD2
)
SELECT
ST.MY_FIELD1
,NULL AS MY_FIELD2 --insert NULL into this field
FROM
SOURCE_TABLE ST
WHERE NOT EXISTS(
SELECT DT2.PRIMARY_KEY
FROM DESTINATION_TABLE DT2
WHERE DT2.PRIMARY_KEY = ST.PRIMARY_KEY
);
Wenn jemand meine Lösung für SQLite in Cordova zu lesen, ich habe diese generische js Methode dank @ David oben beantworten.
function addOrUpdateRecords(tableName, values, callback) {
get_columnNames(tableName, function (data) {
var columnNames = data;
myDb.transaction(function (transaction) {
var query_update = "";
var query_insert = "";
var update_string = "UPDATE " + tableName + " SET ";
var insert_string = "INSERT INTO " + tableName + " SELECT ";
myDb.transaction(function (transaction) {
// Data from the array [[data1, ... datan],[()],[()]...]:
$.each(values, function (index1, value1) {
var sel_str = "";
var upd_str = "";
var remoteid = "";
$.each(value1, function (index2, value2) {
if (index2 == 0) remoteid = value2;
upd_str = upd_str + columnNames[index2] + "='" + value2 + "', ";
sel_str = sel_str + "'" + value2 + "', ";
});
sel_str = sel_str.substr(0, sel_str.length - 2);
sel_str = sel_str + " WHERE NOT EXISTS(SELECT changes() AS change FROM "+tableName+" WHERE change <> 0);";
upd_str = upd_str.substr(0, upd_str.length - 2);
upd_str = upd_str + " WHERE remoteid = '" + remoteid + "';";
query_update = update_string + upd_str;
query_insert = insert_string + sel_str;
// Start transaction:
transaction.executeSql(query_update);
transaction.executeSql(query_insert);
});
}, function (error) {
callback("Error: " + error);
}, function () {
callback("Success");
});
});
});
}
Also, zuerst die Spaltennamen mit dieser Funktion aufheben:
function get_columnNames(tableName, callback) {
myDb.transaction(function (transaction) {
var query_exec = "SELECT name, sql FROM sqlite_master WHERE type='table' AND name ='" + tableName + "'";
transaction.executeSql(query_exec, [], function (tx, results) {
var columnParts = results.rows.item(0).sql.replace(/^[^\(]+\(([^\)]+)\)/g, '$1').split(','); ///// RegEx
var columnNames = [];
for (i in columnParts) {
if (typeof columnParts[i] === 'string')
columnNames.push(columnParts[i].split(" ")[0]);
};
callback(columnNames);
});
});
}
Dann die Transaktionen bauen programmatisch.
„Werte“ ist ein Array, das Sie vor aufbauen sollte und es stellt sich die Zeilen, die Sie wollen in der Tabelle einzufügen oder zu aktualisieren.
„RemoteID“ ist die ID ich als Referenz verwendet, da ich mit meinem Remote-Server bin synchronisieren.
Für die Verwendung der SQLite Cordova-Plugin finden Sie in dem offiziellen Link
ich denke, das kann sein, was Sie suchen. KONFLIKT Klausel
Wenn Sie definieren Ihre Tabelle wie folgt aus:
CREATE TABLE table1(
id INTEGER PRIMARY KEY ON CONFLICT REPLACE,
field1 TEXT
);
Nun, wenn Sie eine INSERT mit einer ID zu tun, die bereits vorhanden ist, SQLite automagically tut UPDATE statt INSERT.
HTH ...
Diese Methode remixt einige der anderen Methoden von Antwort zu dieser Frage und beinhaltet die Verwendung von CTE (Common Table Expressions). Ich werde die Abfrage vorstellen dann erklären, warum ich tat, was ich tat.
Ich möchte den Nachnamen für Mitarbeiter ändern 300 bis DAVIS, wenn Mitarbeiter 300. Andernfalls ist, werde ich einen neuen Mitarbeiter hinzufügen.
Tabellenname: Mitarbeiter Spalten: id, vorname, nachname
Die Abfrage ist:
INSERT OR REPLACE INTO employees (employee_id, first_name, last_name)
WITH registered_employees AS ( --CTE for checking if the row exists or not
SELECT --this is needed to ensure that the null row comes second
*
FROM (
SELECT --an existing row
*
FROM
employees
WHERE
employee_id = '300'
UNION
SELECT --a dummy row if the original cannot be found
NULL AS employee_id,
NULL AS first_name,
NULL AS last_name
)
ORDER BY
employee_id IS NULL --we want nulls to be last
LIMIT 1 --we only want one row from this statement
)
SELECT --this is where you provide defaults for what you would like to insert
registered_employees.employee_id, --if this is null the SQLite default will be used
COALESCE(registered_employees.first_name, 'SALLY'),
'DAVIS'
FROM
registered_employees
;
Im Grunde genommen habe ich den CTE die Anzahl der Male die select-Anweisung verwendet werden muss zu reduzieren, um die Standardwerte zu bestimmen. Da dies ein CTE ist, wählen wir nur die Spalten wir aus der Tabelle zu wollen und die INSERT-Anweisung verwendet diese.
Jetzt können Sie entscheiden, welche Vorgaben Sie mit durch Ersetzen der NULL-Werte in der COALESCE-Funktion verwenden möchten, was die Werte sein sollte.
Im Anschluss an Aristoteles Pagaltzis und die Idee der COALESCE von Antwort Eric B, hier ist es eine Upsert Option nur wenige Spalten zu aktualisieren oder vollständige Zeile einfügen, wenn es nicht existiert
In diesem Fall stellen sie sich diesen Titel und Inhalt aktualisiert werden sollte, die anderen alten Werte zu halten, wenn bestehende und Einfügen mitgelieferten sind, wenn der Name nicht gefunden:
Hinweis id gezwungen NULL sein, wenn INSERT wie es soll AUTOINCREMENT werden. Wenn es nur ein generierter Primärschlüssel ist, dann kann COALESCE auch verwendet werden (siehe Aristoteles Pagaltzis Kommentar ).
WITH new (id, name, title, content, author)
AS ( VALUES(100, 'about', 'About this site', 'Whatever new content here', 42) )
INSERT OR REPLACE INTO page (id, name, title, content, author)
SELECT
old.id, COALESCE(old.name, new.name),
new.title, new.content,
COALESCE(old.author, new.author)
FROM new LEFT JOIN page AS old ON new.name = old.name;
So die allgemeine Regel wäre, wenn Sie wollen die alten Werte zu halten, verwenden COALESCE, wenn Sie Werte aktualisieren möchten, verwenden Sie new.fieldname
Mit nur diesen Thread gelesen und enttäuscht, dass es nicht leicht war, nur auf diesen „UPSERT“ ing, untersuchte ich weiter ...
Sie können tatsächlich tun dies direkt und einfach in SQLITE.
Anstelle von: INSERT INTO
Verwendung: INSERT OR REPLACE INTO
Das ist genau das, was Sie wollen, es zu tun!
SELECT COUNT(*) FROM table1 WHERE id = 1;
Wenn COUNT(*) = 0
INSERT INTO table1(col1, col2, cole) VALUES(var1,var2,var3);
else if COUNT(*) > 0
UPDATE table1 SET col1 = var4, col2 = var5, col3 = var6 WHERE id = 1;
