SQLite - UPSERT * não * colocar ou substituir
 https://stackoverflow.com/questions/418898
https://stackoverflow.com/questions/418898
 italiano
italiano english
english français
français española
española 中国
中国 日本の
日本の العربية
العربية Deutsch
Deutsch 한국어
한국어 Português
Português Russian
RussianPergunta
http://en.wikipedia.org/wiki/Upsert
Inserir Atualização proc armazenado no SQL Server
Existe alguma maneira inteligente de fazer isso no SQLite que eu não tenha pensado?
Basicamente eu quero atualizar três em cada quatro colunas se existe o registro, Se ele não existe eu quero inserir o registro com o valor padrão (NUL) para a quarta coluna.
O ID é uma chave primária para que haja só vai ser um registro para UPSERT.
(Eu estou tentando evitar a sobrecarga de SELECT no fim de determin se eu precisar de atualização ou inserção obviamente)
Sugestões?
Não posso confirmar que a sintaxe no site SQLite para CREATE TABLE. Eu não construí uma demo para testá-lo, mas não parece ser suportado ..
Se fosse, eu tenho três colunas por isso seria realmente parecido com:
CREATE TABLE table1(
id INTEGER PRIMARY KEY ON CONFLICT REPLACE,
Blob1 BLOB ON CONFLICT REPLACE,
Blob2 BLOB ON CONFLICT REPLACE,
Blob3 BLOB
);
mas os dois primeiros blobs não irá causar um conflito, apenas o ID faria Então eu asusme Blob1 e Blob2 não seriam substituídos (como desejado)
UPDATEs em SQLite quando os dados de ligação são uma transação completa, ou seja, Cada linha enviada para ser atualizado requer: Preparar / Bind / STEP declarações / Finalize ao contrário da inserção que permite o uso da função de reset
A vida de um objeto de declaração é algo como isto:
- Criar o objeto usando sqlite3_prepare_v2 ()
- valores ligam a parâmetros de host usando sqlite3_bind_ interfaces.
- Execute o SQL chamando sqlite3_step ()
- Redefinir a instrução usando sqlite3_reset (), em seguida, voltar para o passo 2 e repita.
- Destruir o objeto instrução usando sqlite3_finalize ().
Atualização Eu estou supondo que é lento em comparação com INSERT, mas como ele se compara a selecionar usando a chave primária?
Talvez eu devesse usar o selecione para ler a quarta coluna (Blob3) e, em seguida, usar REPLACE para escrever um novo recorde misturando a quarta coluna original com os novos dados para os primeiros 3 colunas?
Solução
Assumindo 3 colunas na tabela .. ID, nome, a função
BAD: Isto irá inserir ou substituir todas as colunas com novos valores para ID = 1:
INSERT OR REPLACE INTO Employee (id, name, role)
VALUES (1, 'John Foo', 'CEO');
BAD: Isto irá inserir ou substituir 2 das colunas ... a coluna NOME será definido como NULL ou o valor padrão:
INSERT OR REPLACE INTO Employee (id, role)
VALUES (1, 'code monkey');
BOA: Isto irá atualizar 2 das colunas. Quando ID = 1 existe, o nome será afectada. Quando ID = 1 não existe, o nome será padrão (NULL).
INSERT OR REPLACE INTO Employee (id, role, name)
VALUES ( 1,
'code monkey',
(SELECT name FROM Employee WHERE id = 1)
);
Isto irá atualizar 2 das colunas. Quando ID = 1 existe, o papel não será afectada. Quando ID = 1 não existe, o papel será definido como 'Benchwarmer' em vez do valor padrão.
INSERT OR REPLACE INTO Employee (id, name, role)
VALUES ( 1,
'Susan Bar',
COALESCE((SELECT role FROM Employee WHERE id = 1), 'Benchwarmer')
);
Outras dicas
introduzir ou substituir é não equivalente a "UPSERT".
Say I têm o empregado de mesa com os campos id, nome e função:
INSERT OR REPLACE INTO Employee ("id", "name", "role") VALUES (1, "John Foo", "CEO")
INSERT OR REPLACE INTO Employee ("id", "role") VALUES (1, "code monkey")
Boom, você perdeu o nome do funcionário número 1. SQLite substituiu-o com um valor padrão.
A saída esperada de um UPSERT seria mudar o papel e manter o nome.
O Eric B resposta é OK, se você quiser preservar apenas uma ou talvez duas colunas do existente linha. Se você quiser preservar um monte de colunas, torna-se demasiado pesado rápido.
Aqui está uma abordagem que vai ser bem dimensionada para qualquer quantidade de colunas de cada lado. Para ilustrar isso vou assumir o seguinte esquema:
CREATE TABLE page (
id INTEGER PRIMARY KEY,
name TEXT UNIQUE,
title TEXT,
content TEXT,
author INTEGER NOT NULL REFERENCES user (id),
ts TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
Nota, em particular, que name é a chave natural da linha - id é usado apenas para chaves estrangeiras, por isso, o ponto é para SQLite para escolher o próprio valor de ID ao inserir uma nova linha. Mas ao atualizar uma linha existente com base na sua name, eu quero que ele continue a ter o valor ID de idade (obviamente!).
I alcançar uma verdadeira UPSERT com a seguinte construção:
WITH new (name, title, author) AS ( VALUES('about', 'About this site', 42) )
INSERT OR REPLACE INTO page (id, name, title, content, author)
SELECT old.id, new.name, new.title, old.content, new.author
FROM new LEFT JOIN page AS old ON new.name = old.name;
A forma exata desta consulta pode variar um pouco. A chave é o uso de INSERT SELECT com uma junção externa esquerda, para se juntar a uma linha existente para os novos valores.
Aqui, se uma linha não existia anteriormente, old.id será NULL e SQLite, então, atribuir um ID automaticamente, mas se já havia uma tal linha, old.id terá um valor real e isso vai ser reutilizados. Que é exatamente o que eu queria.
Na verdade, esta é muito flexível. Observe como a coluna ts está completamente ausente em todos os lados -. Porque tem um valor DEFAULT, SQLite só vai fazer a coisa certa, em qualquer caso, então eu não tenho que cuidar dele me
Você também pode incluir uma coluna em ambos os new e old lados e, em seguida, usar por exemplo COALESCE(new.content, old.content) na SELECT exterior para dizer “inserir o novo conteúdo se havia alguma, caso contrário, manter o conteúdo antigo” - por exemplo, se você estiver usando uma consulta fixo e são vinculativos os novos valores com espaços reservados.
Se você está geralmente fazendo atualizações que eu faria ..
- Inicie uma transação
- Faça o update
- Verifique o número de linhas
- Se for 0 fazer a inserção
- Commit
Se você está geralmente fazendo inserções eu faria
- Inicie uma transação
- Tente uma inserção
- Verifique se há erro de chave violação primária
- se temos um erro fazer a atualização
- Commit
Desta forma você evita o seleto e você está transactionally soar em SQLite.
Esta resposta tem ser atualizado e assim os comentários abaixo não se aplicam mais.
2018/05/18 Parar Prima.
UPSERT apoio em SQLite! UPSERT sintaxe foi adicionado em SQLite com versão 3.24. 0 (pendente)!
UPSERT é uma adição sintaxe especial para INSERT que faz com que o INSERT para se comportar como uma atualização ou um não-op se o INSERT violaria uma restrição de exclusividade. UPSERT não é SQL padrão. UPSERT em SQLite segue a sintaxe criada pelo PostgreSQL.

Como alternativa:
Outra maneira completamente diferente de fazer isso é: Na minha aplicação eu definir a minha memória no RowId ser long.MaxValue quando eu criar a linha na memória. (MaxValue nunca vai ser usado como um ID que você não vai viver o suficiente .... Então, se rowID não é esse valor, então ele deve já estar no banco de dados de modo precisa de uma atualização se é MaxValue, em seguida, ele precisa de uma inserção. Isto só é útil se você pode acompanhar as ROWIDs em seu aplicativo.
Sei que esta é uma discussão antiga, mas eu tenho trabalhado em sqlite3 como de tarde e veio com este método que melhor adequados meu necessidades de gerar dinamicamente consultas parametrizadas:
insert or ignore into <table>(<primaryKey>, <column1>, <column2>, ...) values(<primaryKeyValue>, <value1>, <value2>, ...);
update <table> set <column1>=<value1>, <column2>=<value2>, ... where changes()=0 and <primaryKey>=<primaryKeyValue>;
É ainda 2 consultas com uma cláusula WHERE na atualização, mas parece estar a fazer o truque. Eu também tenho esta visão na minha cabeça que sqlite pode otimizar afastado a instrução de atualização completo, se a chamada para mudanças () é maior do que zero. Se é ou não verdade é que isso está além do meu conhecimento, mas um homem pode sonhar não pode? ;)
Para pontos de bônus você pode acrescentar esta linha que retorna o ID da linha seja uma linha recém-inserida ou uma linha existente.
select case changes() WHEN 0 THEN last_insert_rowid() else <primaryKeyValue> end;
Aqui está uma solução que realmente é um UPSERT (UPDATE ou INSERT) em vez de um INSERT ou REPLACE (que funciona de maneira diferente em muitas situações).
Ele funciona assim:
1. Tente atualização se um registro com o mesmo Id existe.
2. Se a atualização não mudou nenhuma linha (NOT EXISTS(SELECT changes() AS change FROM Contact WHERE change <> 0)), em seguida, insira o registro.
Assim, ou um registro existente foi atualizado ou uma inserção será executada.
O detalhe importante é usar as mudanças () função de SQL para verificar se a instrução de atualização bateu todos os registros existentes e só executar a instrução de inserção se não bater qualquer registro.
Uma coisa a mencionar é que as mudanças function () não retorna alterações realizadas por disparadores de nível inferior (ver http://sqlite.org/lang_corefunc.html#changes ), por isso não deixe de levar isso em conta.
Aqui está o SQL ...
atualização de teste:
--Create sample table and records (and drop the table if it already exists)
DROP TABLE IF EXISTS Contact;
CREATE TABLE [Contact] (
[Id] INTEGER PRIMARY KEY,
[Name] TEXT
);
INSERT INTO Contact (Id, Name) VALUES (1, 'Mike');
INSERT INTO Contact (Id, Name) VALUES (2, 'John');
-- Try to update an existing record
UPDATE Contact
SET Name = 'Bob'
WHERE Id = 2;
-- If no record was changed by the update (meaning no record with the same Id existed), insert the record
INSERT INTO Contact (Id, Name)
SELECT 2, 'Bob'
WHERE NOT EXISTS(SELECT changes() AS change FROM Contact WHERE change <> 0);
--See the result
SELECT * FROM Contact;
inserção de teste:
--Create sample table and records (and drop the table if it already exists)
DROP TABLE IF EXISTS Contact;
CREATE TABLE [Contact] (
[Id] INTEGER PRIMARY KEY,
[Name] TEXT
);
INSERT INTO Contact (Id, Name) VALUES (1, 'Mike');
INSERT INTO Contact (Id, Name) VALUES (2, 'John');
-- Try to update an existing record
UPDATE Contact
SET Name = 'Bob'
WHERE Id = 3;
-- If no record was changed by the update (meaning no record with the same Id existed), insert the record
INSERT INTO Contact (Id, Name)
SELECT 3, 'Bob'
WHERE NOT EXISTS(SELECT changes() AS change FROM Contact WHERE change <> 0);
--See the result
SELECT * FROM Contact;
Você pode realmente fazer um upsert em SQLite, ele só parece um pouco diferente do que você está acostumado. Seria algo como:
INSERT INTO table name (column1, column2)
VALUES ("value12", "value2") WHERE id = 123
ON CONFLICT DO UPDATE
SET column1 = "value1", column2 = "value2" WHERE id = 123
Expandindo resposta de Aristóteles você pode selecionar a partir de um manequim tabela 'solteirão' (uma mesa de sua própria criação, com uma única linha ). Isso evita alguma duplicação.
Eu também tenho mantido o exemplo portátil através de MySQL e SQLite e utilizou uma coluna 'DATE_ADDED' como um exemplo de como você poderia definir uma coluna somente na primeira vez.
REPLACE INTO page (
id,
name,
title,
content,
author,
date_added)
SELECT
old.id,
"about",
"About this site",
old.content,
42,
IFNULL(old.date_added,"21/05/2013")
FROM singleton
LEFT JOIN page AS old ON old.name = "about";
A partir da versão 3.24.0 UPSERT é suportado pelo SQLite.
A partir da documentação :
UPSERT é uma adição sintaxe especial para INSERT que faz com que o INSERT para se comportar como uma atualização ou um não-op se o INSERT violaria uma restrição de exclusividade. UPSERT não é SQL padrão. UPSERT em SQLite segue a sintaxe criada pelo PostgreSQL. UPSERT sintaxe foi adicionado em SQLite com a versão 3.24.0 (pendente).
Um UPSERT é uma instrução INSERT comum, que é seguido pela cláusula ON CONFLICT especial
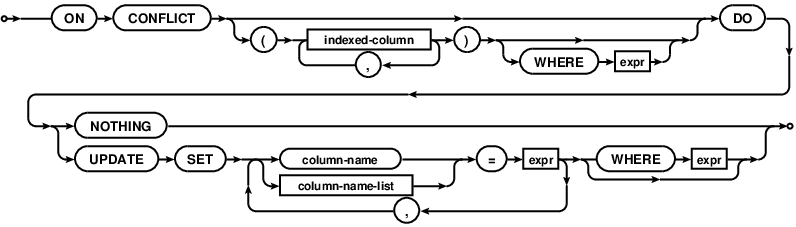
Fonte da imagem: https://www.sqlite.org /images/syntax/upsert-clause.gif
A melhor abordagem que eu sei é fazer uma atualização, seguido de uma inserção. A "sobrecarga de um seleto" é necessário, mas não é um fardo terrível desde que você está pesquisando na chave primária, que é rápido.
Você deve ser capaz de modificar o abaixo declarações com sua tabela e nomes de campo para fazer o que quiser.
--first, update any matches
UPDATE DESTINATION_TABLE DT
SET
MY_FIELD1 = (
SELECT MY_FIELD1
FROM SOURCE_TABLE ST
WHERE ST.PRIMARY_KEY = DT.PRIMARY_KEY
)
,MY_FIELD2 = (
SELECT MY_FIELD2
FROM SOURCE_TABLE ST
WHERE ST.PRIMARY_KEY = DT.PRIMARY_KEY
)
WHERE EXISTS(
SELECT ST2.PRIMARY_KEY
FROM
SOURCE_TABLE ST2
,DESTINATION_TABLE DT2
WHERE ST2.PRIMARY_KEY = DT2.PRIMARY_KEY
);
--second, insert any non-matches
INSERT INTO DESTINATION_TABLE(
MY_FIELD1
,MY_FIELD2
)
SELECT
ST.MY_FIELD1
,NULL AS MY_FIELD2 --insert NULL into this field
FROM
SOURCE_TABLE ST
WHERE NOT EXISTS(
SELECT DT2.PRIMARY_KEY
FROM DESTINATION_TABLE DT2
WHERE DT2.PRIMARY_KEY = ST.PRIMARY_KEY
);
Se alguém quiser ler a minha solução para SQLite em Cordova, eu tenho esse método js genérica graças à resposta @ David acima.
function addOrUpdateRecords(tableName, values, callback) {
get_columnNames(tableName, function (data) {
var columnNames = data;
myDb.transaction(function (transaction) {
var query_update = "";
var query_insert = "";
var update_string = "UPDATE " + tableName + " SET ";
var insert_string = "INSERT INTO " + tableName + " SELECT ";
myDb.transaction(function (transaction) {
// Data from the array [[data1, ... datan],[()],[()]...]:
$.each(values, function (index1, value1) {
var sel_str = "";
var upd_str = "";
var remoteid = "";
$.each(value1, function (index2, value2) {
if (index2 == 0) remoteid = value2;
upd_str = upd_str + columnNames[index2] + "='" + value2 + "', ";
sel_str = sel_str + "'" + value2 + "', ";
});
sel_str = sel_str.substr(0, sel_str.length - 2);
sel_str = sel_str + " WHERE NOT EXISTS(SELECT changes() AS change FROM "+tableName+" WHERE change <> 0);";
upd_str = upd_str.substr(0, upd_str.length - 2);
upd_str = upd_str + " WHERE remoteid = '" + remoteid + "';";
query_update = update_string + upd_str;
query_insert = insert_string + sel_str;
// Start transaction:
transaction.executeSql(query_update);
transaction.executeSql(query_insert);
});
}, function (error) {
callback("Error: " + error);
}, function () {
callback("Success");
});
});
});
}
Então, primeiro pegar os nomes das colunas com esta função:
function get_columnNames(tableName, callback) {
myDb.transaction(function (transaction) {
var query_exec = "SELECT name, sql FROM sqlite_master WHERE type='table' AND name ='" + tableName + "'";
transaction.executeSql(query_exec, [], function (tx, results) {
var columnParts = results.rows.item(0).sql.replace(/^[^\(]+\(([^\)]+)\)/g, '$1').split(','); ///// RegEx
var columnNames = [];
for (i in columnParts) {
if (typeof columnParts[i] === 'string')
columnNames.push(columnParts[i].split(" ")[0]);
};
callback(columnNames);
});
});
}
Em seguida, construir as transações programaticamente.
"Valores" é um array você deve construir antes e que representa as linhas que deseja inserir ou atualização na tabela.
"remoteid" é o id eu usei como referência, já que estou a sincronização com o meu servidor remoto.
Para o uso do plugin SQLite Cordova, consulte o oficial ligação
Eu acho que isso pode ser o que você está procurando:. ON CONFLICT cláusula
Se você definir sua tabela como esta:
CREATE TABLE table1(
id INTEGER PRIMARY KEY ON CONFLICT REPLACE,
field1 TEXT
);
Agora, se você fizer um INSERT com um ID que já existe, SQLite automagicamente faz Update em vez de INSERT.
Hth ...
Este método remistura alguns dos outros métodos de resposta em questão e para este incorpora o uso de CTE (Expressões tabela comum). Vou apresentar a consulta, em seguida, explicar por que eu fiz o que fiz.
Eu gostaria de mudar o último nome para o empregado 300 para DAVIS se houver um empregado 300. Caso contrário, vou adicionar um novo funcionário.
Nome da tabela: funcionários Colunas: id, first_name, last_name
A consulta é:
INSERT OR REPLACE INTO employees (employee_id, first_name, last_name)
WITH registered_employees AS ( --CTE for checking if the row exists or not
SELECT --this is needed to ensure that the null row comes second
*
FROM (
SELECT --an existing row
*
FROM
employees
WHERE
employee_id = '300'
UNION
SELECT --a dummy row if the original cannot be found
NULL AS employee_id,
NULL AS first_name,
NULL AS last_name
)
ORDER BY
employee_id IS NULL --we want nulls to be last
LIMIT 1 --we only want one row from this statement
)
SELECT --this is where you provide defaults for what you would like to insert
registered_employees.employee_id, --if this is null the SQLite default will be used
COALESCE(registered_employees.first_name, 'SALLY'),
'DAVIS'
FROM
registered_employees
;
Basicamente, eu usei o CTE para reduzir o número de vezes que a instrução select deve ser usado para determinar valores padrão. Como este é um CTE, nós apenas selecionar as colunas que queremos da mesa e a instrução INSERT usa isso.
Agora você pode decidir o padrão que deseja usar, substituindo os nulos, na função COALESCE com o que os valores devem ser.
A seguir Aristóteles Pagaltzis ea ideia de COALESCE de Eric B resposta , aqui está uma opção upsert para atualizar apenas algumas colunas ou inserir linha completa se ela não existe
Neste caso, imaginar que o título e conteúdo deve ser atualizado, mantendo os outros valores antigos, quando existente e inserir os fornecidos quando o nome não encontrado:
NOTA id é forçado a ser NULL quando INSERT como é suposto ser autoincrement. Se é apenas uma chave primária gerada depois COALESCE também pode ser usado (ver Aristotle Pagaltzis comentário ).
WITH new (id, name, title, content, author)
AS ( VALUES(100, 'about', 'About this site', 'Whatever new content here', 42) )
INSERT OR REPLACE INTO page (id, name, title, content, author)
SELECT
old.id, COALESCE(old.name, new.name),
new.title, new.content,
COALESCE(old.author, new.author)
FROM new LEFT JOIN page AS old ON new.name = old.name;
Assim, a regra geral seria, se você quiser manter os valores antigos, o uso COALESCE, quando você quer atualizar valores, uso new.fieldname
Tendo acabado de ler esta discussão e está desapontado que não era fácil apenas a este "UPSERT" ing, eu investigada ...
Você pode realmente fazer isso diretamente e facilmente em SQLITE.
Em vez de usar: INSERT INTO
Use: INSERT OR REPLACE INTO
Este faz exatamente o que você quer que ele faça!
SELECT COUNT(*) FROM table1 WHERE id = 1;
Se COUNT(*) = 0
INSERT INTO table1(col1, col2, cole) VALUES(var1,var2,var3);
else if COUNT(*) > 0
UPDATE table1 SET col1 = var4, col2 = var5, col3 = var6 WHERE id = 1;
