SQLite - UPSERT * not * INSERT o REPLACE
 https://stackoverflow.com/questions/418898
https://stackoverflow.com/questions/418898
 italiano
italiano english
english français
français española
española 中国
中国 日本の
日本の العربية
العربية Deutsch
Deutsch 한국어
한국어 Português
Português Russian
RussianDomanda
http://en.wikipedia.org/wiki/Upsert
Inserisci aggiornamento processo memorizzato su SQL Server
Esiste un modo intelligente per farlo in SQLite a cui non ho pensato?
Fondamentalmente voglio aggiornare tre colonne su quattro se il record esiste, Se non esiste, voglio INSERIRE il record con il valore predefinito (NUL) per la quarta colonna.
L'ID è una chiave primaria, quindi su UPSERT sarà registrato un solo record.
(Sto cercando di evitare il sovraccarico di SELECT per determinare se devo ovviamente AGGIORNARE o INSERIRE)
Suggerimenti?
Non riesco a confermare che la sintassi sul sito SQLite per TABLE CREATE. Non ho creato una demo per testarlo, ma non sembra essere supportato ..
Se lo fosse, ho tre colonne in modo che sembrerebbe effettivamente:
CREATE TABLE table1(
id INTEGER PRIMARY KEY ON CONFLICT REPLACE,
Blob1 BLOB ON CONFLICT REPLACE,
Blob2 BLOB ON CONFLICT REPLACE,
Blob3 BLOB
);
ma i primi due BLOB non causeranno un conflitto, solo l'ID lo farebbe Quindi suppongo che Blob1 e Blob2 non vengano sostituiti (come desiderato)
AGGIORNAMENTI in SQLite quando i dati di associazione sono una transazione completa, vale a dire Ogni riga inviata per essere aggiornata richiede: istruzioni Preparare / Bind / Step / Finalize a differenza di INSERT che consente l'uso della funzione di ripristino
La vita di un oggetto statement va in questo modo:
- Crea l'oggetto usando sqlite3_prepare_v2 ()
- Associa i valori ai parametri host utilizzando le interfacce sqlite3_bind_.
- Esegui l'SQL chiamando sqlite3_step ()
- Reimposta l'istruzione usando sqlite3_reset () quindi torna al passaggio 2 e ripeti.
- Distruggi l'oggetto istruzione usando sqlite3_finalize ().
AGGIORNAMENTO Immagino sia lento rispetto a INSERT, ma come si confronta con SELECT usando la chiave primaria?
Forse dovrei usare la selezione per leggere la quarta colonna (Blob3) e quindi usare REPLACE per scrivere un nuovo record mescolando la quarta colonna originale con i nuovi dati per le prime 3 colonne?
Soluzione
Supponendo 3 colonne nella tabella .. ID, NAME, ROLE
BAD: questo inserirà o sostituirà tutte le colonne con nuovi valori per ID = 1:
INSERT OR REPLACE INTO Employee (id, name, role)
VALUES (1, 'John Foo', 'CEO');
BAD: questo inserirà o sostituirà 2 delle colonne ... la colonna NAME verrà impostata su NULL o il valore predefinito:
INSERT OR REPLACE INTO Employee (id, role)
VALUES (1, 'code monkey');
BUONO: questo aggiornerà 2 delle colonne. Quando esiste ID = 1, il NAME non sarà interessato. Quando ID = 1 non esiste, il nome sarà predefinito (NULL).
INSERT OR REPLACE INTO Employee (id, role, name)
VALUES ( 1,
'code monkey',
(SELECT name FROM Employee WHERE id = 1)
);
Questo aggiornerà 2 delle colonne. Quando esiste ID = 1, il RUOLO non sarà interessato. Quando ID = 1 non esiste, il ruolo verrà impostato su "Benchwarmer" anziché sul valore predefinito.
INSERT OR REPLACE INTO Employee (id, name, role)
VALUES ( 1,
'Susan Bar',
COALESCE((SELECT role FROM Employee WHERE id = 1), 'Benchwarmer')
);
Altri suggerimenti
INSERIRE O SOSTITUIRE è NON equivalente a " UPSERT " ;.
Dire che ho la tabella Employee con i campi id, nome e ruolo:
INSERT OR REPLACE INTO Employee ("id", "name", "role") VALUES (1, "John Foo", "CEO")
INSERT OR REPLACE INTO Employee ("id", "role") VALUES (1, "code monkey")
Boom, hai perso il nome del numero di dipendente 1. SQLite lo ha sostituito con un valore predefinito.
L'output atteso di un UPSERT sarebbe quello di cambiare il ruolo e mantenere il nome.
Eric B & # 8217; s risposta è OK se vuoi preservarne solo uno o forse due colonne dalla riga esistente. Se vuoi conservare molte colonne, diventa troppo ingombrante velocemente.
Qui & # 8217; s un approccio che si adatta bene a qualsiasi quantità di colonne su entrambi i lati. Per illustrarlo, assumerò il seguente schema:
CREATE TABLE page (
id INTEGER PRIMARY KEY,
name TEXT UNIQUE,
title TEXT,
content TEXT,
author INTEGER NOT NULL REFERENCES user (id),
ts TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
Nota in particolare che name è la chiave naturale della riga & # 8211; id viene utilizzato solo per le chiavi esterne, quindi il punto è che SQLite scelga il valore ID stesso quando si inserisce una nuova riga. Ma quando aggiorno una riga esistente in base al suo UPSERT, voglio che continui ad avere il vecchio valore ID (ovviamente!).
Ottengo un vero INSERT SELECT con il seguente costrutto:
WITH new (name, title, author) AS ( VALUES('about', 'About this site', 42) )
INSERT OR REPLACE INTO page (id, name, title, content, author)
SELECT old.id, new.name, new.title, old.content, new.author
FROM new LEFT JOIN page AS old ON new.name = old.name;
La forma esatta di questa query può variare leggermente. La chiave è l'uso di old.id con un join esterno sinistro, per unire una riga esistente ai nuovi valori.
Qui, se in precedenza non esisteva una riga, NULL sarà ts e SQLite assegnerà quindi un ID automaticamente, ma se esiste già tale riga, DEFAULT avrà un valore effettivo e questo sarà essere riutilizzato. È esattamente quello che volevo.
In realtà questo è molto flessibile. Nota come la colonna new è completamente mancante su tutti i lati & # 8211; poiché ha un valore old, SQLite farà semplicemente la cosa giusta in ogni caso, quindi non & # 8217; non devo occuparmene da solo.
Puoi anche includere una colonna su entrambi i lati COALESCE(new.content, old.content) e SELECT e quindi utilizzare ad es. <=> nella parte esterna <=> per dire & # 8220; inserisci il nuovo contenuto, se presente, altrimenti mantieni il vecchio contenuto & # 8221; & # 8211; per esempio. se stai utilizzando una query fissa e stai vincolando i nuovi valori con i segnaposto.
Se in genere stai facendo aggiornamenti, vorrei ...
- Inizia una transazione
- Esegui l'aggiornamento
- Controlla il conteggio delle righe
- Se è 0 fai l'inserimento
- Commit
Se in genere stai inserendo, lo farei
- Inizia una transazione
- Prova un inserto
- Verifica errore di violazione chiave primaria
- se si è verificato un errore, eseguire l'aggiornamento
- Commit
In questo modo si evita la selezione e si è transazionali su Sqlite.
Questa risposta è stata aggiornata e quindi i seguenti commenti non si applicano più.
18/05/2018 FERMA STAMPA.
Supporto UPSERT in SQLite! La sintassi UPSERT è stata aggiunta a SQLite con la versione 3.24. 0 (in sospeso)!
UPSERT è un'aggiunta speciale di sintassi a INSERT che fa sì che INSERT si comporti come AGGIORNAMENTO o no-op se INSERT violerebbe un vincolo di unicità. UPSERT non è SQL standard. UPSERT in SQLite segue la sintassi stabilita da PostgreSQL.

In alternativa:
Un altro modo completamente diverso di farlo è: Nella mia applicazione ho impostato il mio ID riga in memoria su long.MaxValue quando creo la riga in memoria. (MaxValue non verrà mai utilizzato come ID e non vivrai abbastanza a lungo .... Quindi se rowID non è quel valore, allora deve già essere nel database, quindi ha bisogno di un AGGIORNAMENTO se è MaxValue, quindi ha bisogno di un inserimento. Ciò è utile solo se è possibile tenere traccia dei rowID nella tua app.
Mi rendo conto che si tratta di un vecchio thread, ma ho lavorato su sqlite3 negli ultimi tempi e ho escogitato questo metodo che si adattava meglio alle mie esigenze di generazione dinamica di query con parametri:
insert or ignore into <table>(<primaryKey>, <column1>, <column2>, ...) values(<primaryKeyValue>, <value1>, <value2>, ...);
update <table> set <column1>=<value1>, <column2>=<value2>, ... where changes()=0 and <primaryKey>=<primaryKeyValue>;
Sono ancora 2 query con una clausola where sull'aggiornamento ma sembra fare il trucco. Ho anche questa visione nella mia testa che sqlite può ottimizzare completamente l'istruzione update se la chiamata a changes () è maggiore di zero. Che ciò avvenga o meno al di là delle mie conoscenze, ma un uomo può sognare, no? ;)
Per i punti bonus puoi aggiungere questa riga che ti restituisce l'id della riga sia che si tratti di una riga appena inserita o di una riga esistente.
select case changes() WHEN 0 THEN last_insert_rowid() else <primaryKeyValue> end;
Ecco una soluzione che in realtà è un UPSERT (AGGIORNAMENTO o INSERT) invece di un INSERT O REPLACE (che funziona in modo diverso in molte situazioni).
Funziona così:
1. Prova ad aggiornare se esiste un record con lo stesso ID.
2. Se l'aggiornamento non ha modificato alcuna riga (NOT EXISTS(SELECT changes() AS change FROM Contact WHERE change <> 0)), inserire il record.
Quindi è stato aggiornato un record esistente o verrà eseguito un inserimento.
Il dettaglio importante consiste nell'utilizzare la funzione change () SQL per verificare se l'istruzione update ha raggiunto qualsiasi record esistente ed eseguire l'istruzione insert solo se non ha raggiunto alcun record.
Una cosa da menzionare è che la funzione change () non restituisce le modifiche eseguite dai trigger di livello inferiore (vedi http://sqlite.org/lang_corefunc.html#changes ), quindi assicurati di tenerne conto.
Ecco l'SQL ...
Aggiornamento di prova:
--Create sample table and records (and drop the table if it already exists)
DROP TABLE IF EXISTS Contact;
CREATE TABLE [Contact] (
[Id] INTEGER PRIMARY KEY,
[Name] TEXT
);
INSERT INTO Contact (Id, Name) VALUES (1, 'Mike');
INSERT INTO Contact (Id, Name) VALUES (2, 'John');
-- Try to update an existing record
UPDATE Contact
SET Name = 'Bob'
WHERE Id = 2;
-- If no record was changed by the update (meaning no record with the same Id existed), insert the record
INSERT INTO Contact (Id, Name)
SELECT 2, 'Bob'
WHERE NOT EXISTS(SELECT changes() AS change FROM Contact WHERE change <> 0);
--See the result
SELECT * FROM Contact;
Test insert:
--Create sample table and records (and drop the table if it already exists)
DROP TABLE IF EXISTS Contact;
CREATE TABLE [Contact] (
[Id] INTEGER PRIMARY KEY,
[Name] TEXT
);
INSERT INTO Contact (Id, Name) VALUES (1, 'Mike');
INSERT INTO Contact (Id, Name) VALUES (2, 'John');
-- Try to update an existing record
UPDATE Contact
SET Name = 'Bob'
WHERE Id = 3;
-- If no record was changed by the update (meaning no record with the same Id existed), insert the record
INSERT INTO Contact (Id, Name)
SELECT 3, 'Bob'
WHERE NOT EXISTS(SELECT changes() AS change FROM Contact WHERE change <> 0);
--See the result
SELECT * FROM Contact;
Puoi davvero fare un upsert in SQLite, sembra solo un po 'diverso da quello a cui sei abituato. Sembrerebbe qualcosa del genere:
INSERT INTO table name (column1, column2)
VALUES ("value12", "value2") WHERE id = 123
ON CONFLICT DO UPDATE
SET column1 = "value1", column2 = "value2" WHERE id = 123
Espandendosi su Aristotele & # 8217; s risposta puoi SELEZIONARE da una tabella fittizia "singleton" (una tabella di la tua creazione con una sola riga). Questo evita duplicazioni.
Ho anche tenuto l'esempio portatile su MySQL e SQLite e ho usato una colonna 'date_added' come esempio di come è possibile impostare una colonna solo la prima volta.
REPLACE INTO page (
id,
name,
title,
content,
author,
date_added)
SELECT
old.id,
"about",
"About this site",
old.content,
42,
IFNULL(old.date_added,"21/05/2013")
FROM singleton
LEFT JOIN page AS old ON old.name = "about";
A partire dalla versione 3.24.0 UPSERT è supportato da SQLite.
Dalla documentazione :
UPSERT è un'aggiunta di sintassi speciale a INSERT che fa sì che INSERT si comporti come AGGIORNAMENTO o non operativo se INSERT violerebbe un vincolo di unicità. UPSERT non è SQL standard. UPSERT in SQLite segue la sintassi stabilita da PostgreSQL. La sintassi UPSERT è stata aggiunta a SQLite con la versione 3.24.0 (in sospeso).
Un UPSERT è una normale istruzione INSERT seguita dalla speciale clausola ON CONFLICT
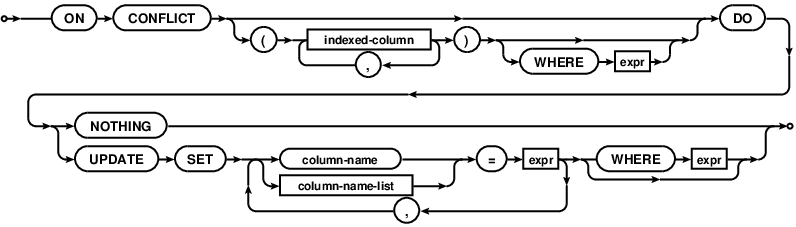
Fonte immagine: https://www.sqlite.org /images/syntax/upsert-clause.gif
L'approccio migliore che conosco è quello di fare un aggiornamento, seguito da un inserimento. Il & Quot; overhead di una selezione & Quot; è necessario, ma non è un peso terribile poiché stai cercando la chiave primaria, che è veloce.
Dovresti essere in grado di modificare le seguenti istruzioni con la tua tabella & amp; nomi dei campi per fare quello che vuoi.
--first, update any matches
UPDATE DESTINATION_TABLE DT
SET
MY_FIELD1 = (
SELECT MY_FIELD1
FROM SOURCE_TABLE ST
WHERE ST.PRIMARY_KEY = DT.PRIMARY_KEY
)
,MY_FIELD2 = (
SELECT MY_FIELD2
FROM SOURCE_TABLE ST
WHERE ST.PRIMARY_KEY = DT.PRIMARY_KEY
)
WHERE EXISTS(
SELECT ST2.PRIMARY_KEY
FROM
SOURCE_TABLE ST2
,DESTINATION_TABLE DT2
WHERE ST2.PRIMARY_KEY = DT2.PRIMARY_KEY
);
--second, insert any non-matches
INSERT INTO DESTINATION_TABLE(
MY_FIELD1
,MY_FIELD2
)
SELECT
ST.MY_FIELD1
,NULL AS MY_FIELD2 --insert NULL into this field
FROM
SOURCE_TABLE ST
WHERE NOT EXISTS(
SELECT DT2.PRIMARY_KEY
FROM DESTINATION_TABLE DT2
WHERE DT2.PRIMARY_KEY = ST.PRIMARY_KEY
);
Se qualcuno vuole leggere la mia soluzione per SQLite in Cordova, ho ottenuto questo metodo js generico grazie alla risposta @david sopra.
function addOrUpdateRecords(tableName, values, callback) {
get_columnNames(tableName, function (data) {
var columnNames = data;
myDb.transaction(function (transaction) {
var query_update = "";
var query_insert = "";
var update_string = "UPDATE " + tableName + " SET ";
var insert_string = "INSERT INTO " + tableName + " SELECT ";
myDb.transaction(function (transaction) {
// Data from the array [[data1, ... datan],[()],[()]...]:
$.each(values, function (index1, value1) {
var sel_str = "";
var upd_str = "";
var remoteid = "";
$.each(value1, function (index2, value2) {
if (index2 == 0) remoteid = value2;
upd_str = upd_str + columnNames[index2] + "='" + value2 + "', ";
sel_str = sel_str + "'" + value2 + "', ";
});
sel_str = sel_str.substr(0, sel_str.length - 2);
sel_str = sel_str + " WHERE NOT EXISTS(SELECT changes() AS change FROM "+tableName+" WHERE change <> 0);";
upd_str = upd_str.substr(0, upd_str.length - 2);
upd_str = upd_str + " WHERE remoteid = '" + remoteid + "';";
query_update = update_string + upd_str;
query_insert = insert_string + sel_str;
// Start transaction:
transaction.executeSql(query_update);
transaction.executeSql(query_insert);
});
}, function (error) {
callback("Error: " + error);
}, function () {
callback("Success");
});
});
});
}
Quindi, prima prendi i nomi delle colonne con questa funzione:
function get_columnNames(tableName, callback) {
myDb.transaction(function (transaction) {
var query_exec = "SELECT name, sql FROM sqlite_master WHERE type='table' AND name ='" + tableName + "'";
transaction.executeSql(query_exec, [], function (tx, results) {
var columnParts = results.rows.item(0).sql.replace(/^[^\(]+\(([^\)]+)\)/g, '$1').split(','); ///// RegEx
var columnNames = [];
for (i in columnParts) {
if (typeof columnParts[i] === 'string')
columnNames.push(columnParts[i].split(" ")[0]);
};
callback(columnNames);
});
});
}
Quindi compilare le transazioni a livello di codice.
" & Valori quot; è un array che dovresti creare prima e rappresenta le righe che desideri inserire o aggiornare nella tabella.
quot &; & Remoteid quot; è l'id che ho usato come riferimento, poiché mi sto sincronizzando con il mio server remoto.
Per l'uso del plug-in SQLite Cordova, consultare il link ufficiale
Penso che questo potrebbe essere quello che stai cercando: sulla clausola ON CONFLICT .
Se definisci la tua tabella in questo modo:
CREATE TABLE table1(
id INTEGER PRIMARY KEY ON CONFLICT REPLACE,
field1 TEXT
);
Ora, se si esegue un INSERT con un ID già esistente, SQLite esegue automaticamente AGGIORNAMENTO anziché INSERT.
Hth ...
Questo metodo remixa alcuni degli altri metodi per rispondere a questa domanda e incorpora l'uso di CTE (Common Table Expressions). Presenterò la domanda e spiegherò perché ho fatto quello che ho fatto.
Vorrei cambiare il cognome del dipendente 300 in DAVIS se c'è un dipendente 300. Altrimenti, aggiungerò un nuovo dipendente.
Nome tabella: dipendenti Colonne: id, first_name, last_name
La query è:
INSERT OR REPLACE INTO employees (employee_id, first_name, last_name)
WITH registered_employees AS ( --CTE for checking if the row exists or not
SELECT --this is needed to ensure that the null row comes second
*
FROM (
SELECT --an existing row
*
FROM
employees
WHERE
employee_id = '300'
UNION
SELECT --a dummy row if the original cannot be found
NULL AS employee_id,
NULL AS first_name,
NULL AS last_name
)
ORDER BY
employee_id IS NULL --we want nulls to be last
LIMIT 1 --we only want one row from this statement
)
SELECT --this is where you provide defaults for what you would like to insert
registered_employees.employee_id, --if this is null the SQLite default will be used
COALESCE(registered_employees.first_name, 'SALLY'),
'DAVIS'
FROM
registered_employees
;
Fondamentalmente, ho usato il CTE per ridurre il numero di volte che l'istruzione select deve essere usata per determinare i valori predefiniti. Poiché si tratta di un CTE, selezioniamo semplicemente le colonne desiderate dalla tabella e l'istruzione INSERT lo utilizza.
Ora puoi decidere quali valori predefiniti vuoi usare sostituendo i null, nella funzione COALESCE con quali dovrebbero essere i valori.
Seguendo Aristotele Pagaltzis e l'idea di COALESCE da Eric B & # 8217; s risposta , qui è un'opzione di aggiornamento per aggiornare solo poche colonne o inserire una riga intera se non esiste.
In questo caso, immagina che titolo e contenuto debbano essere aggiornati, mantenendo gli altri vecchi valori quando esistenti e inserendo quelli forniti quando il nome non è stato trovato:
NOTA id è costretto a essere NULL quando INSERT poiché dovrebbe essere un incremento automatico. Se è solo una chiave primaria generata, è possibile utilizzare anche new.fieldname (vedere Commento di Aristotele Pagaltzis ).
WITH new (id, name, title, content, author)
AS ( VALUES(100, 'about', 'About this site', 'Whatever new content here', 42) )
INSERT OR REPLACE INTO page (id, name, title, content, author)
SELECT
old.id, COALESCE(old.name, new.name),
new.title, new.content,
COALESCE(old.author, new.author)
FROM new LEFT JOIN page AS old ON new.name = old.name;
Quindi la regola generale sarebbe, se vuoi mantenere i vecchi valori, usa <=>, quando vuoi aggiornare i valori, usa <=>
Dopo aver appena letto questa discussione ed essere rimasto deluso dal fatto che non è stato facile solo per questo " UPSERT " ing, ho studiato ulteriormente ...
Puoi effettivamente farlo direttamente e facilmente in SQLITE.
Invece di usare: INSERT INTO
Usa: INSERT OR REPLACE INTO
Questo fa esattamente quello che vuoi che faccia!
SELECT COUNT(*) FROM table1 WHERE id = 1;
se COUNT(*) = 0
INSERT INTO table1(col1, col2, cole) VALUES(var1,var2,var3);
altrimenti se COUNT(*) > 0
UPDATE table1 SET col1 = var4, col2 = var5, col3 = var6 WHERE id = 1;
