pythonic Implementierung von Bayes-Netzwerken für eine bestimmte Anwendung
 https://stackoverflow.com/questions/3783708
https://stackoverflow.com/questions/3783708
-
05-10-2019 - |
 italiano
italiano english
english français
français española
española 中国
中国 日本の
日本の العربية
العربية Deutsch
Deutsch 한국어
한국어 Português
Português Russian
RussianFrage
Das ist, warum ich diese Frage bin gefragt: Im vergangenen Jahr habe ich einige C ++ Code posterior Wahrscheinlichkeiten für eine bestimmte Art von Modell zu berechnen (durch ein Bayes-Netzwerk beschrieben). Das Modell funktionierte ziemlich gut und ein paar andere Leute begann meine Software zu nutzen. Jetzt möchte ich mein Modell verbessern. Da ich schon etwas anders Inferenzalgorithmen für das neue Modell Codierung, entschied ich Python zu verwenden, da die Laufzeit nicht von entscheidenden Bedeutung, und Python war lassen Sie mir eleganten und überschaubar Code zu machen.
In der Regel in dieser Situation, die ich für ein bestehendes Bayes-Netzwerk-Paket in Python suchen würde, aber die Inferenzalgorithmen Ich benutze sind meine eigenen, und ich dachte, auch dies eine große Gelegenheit sein würde, mehr über gutes Design in Python zu lernen .
Ich habe bereits eine große Python-Modul für Netzwerk-Diagramme (NetworkX) gefunden, die Sie ein Wörterbuch zu jedem Knoten und jede Kante befestigen kann. Im wesentlichen Eigenschaften, dies würde lassen Sie mich Knoten und Kanten geben.
Für ein bestimmtes Netz und die beobachteten Daten, ich brauche eine Funktion zu schreiben, die die Wahrscheinlichkeit der nicht zugeordneten Variablen im Modell berechnet.
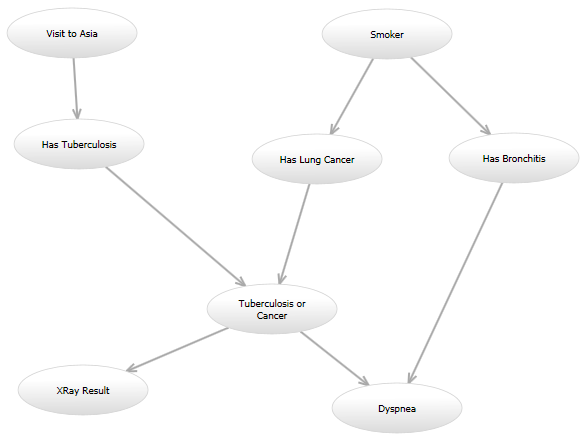
Zum Beispiel in dem klassischen "Asia" Netzwerk ( http: //www.bayesserver .com / Resources / Bilder / AsiaNetwork.png ), mit den Zuständen „XRay Ergebnis“ und „Dyspnoe“ bekannt ist, muss ich, dass die anderen Variablen bestimmte Werte eine Funktion schreiben, um die Wahrscheinlichkeit zu berechnen (nach einige Modelle).
Hier ist meine Programmierung Frage: Ich werde eine Handvoll Modelle, um zu versuchen, und in der Zukunft ist es möglich, möchte ich werde ein anderes Modell danach versuchen. Zum Beispiel könnte ein Modell aussieht genau wie das Asien-Netzwerk. In einem anderen Modell könnte eine gerichtete Kante von „Visit to Asia“ hinzugefügt werden: „Hat Lungenkrebs.“ Ein weiteres Modell könne die ursprünglichen gerichteten Graphen verwenden, aber das Wahrscheinlichkeitsmodell für den „Dyspnoe“ Knoten der „Tuberkulose oder Krebs“ gegeben und „Hat Bronchitis“ Knoten könnte anders sein. All diese Modelle die Wahrscheinlichkeit, in einer anderen Art und Weise berechnen.
Alle Modelle werden wesentliche Überlappung haben; zum Beispiel, gehen mehrere Kanten in einen „Oder“ Knoten wird immer ein „0“ machen, wenn alle Eingänge sonst „0“ und „1“ sind. Aber einige Modelle werden Knoten, die in einem gewissen Bereich auf ganzzahlige Werte annehmen, während andere sein boolean.
In der Vergangenheit habe ich kämpfte mit, wie man Programm Dinge wie diese. Ich werde nicht zu liegen; Es gab Code eine ganze Menge kopiert und eingefügt und manchmal habe ich die erforderlichen Änderungen in einer einzigen Methode, um mehrere Dateien zu verbreiten. Dieses Mal habe ich wirklich wollen die Zeit verbringen, dies ist der richtige Weg zu tun.
Einige Optionen:
- Ich war schon tue dies dem richtigen Weg. Code zuerst fragen später Fragen. Es ist schneller, um den Code zu kopieren und einzufügen und eine Klasse für jedes Modell. Die Welt ist eine dunkle und desorganisiert Ort ...
- Jedes Modell ist eine eigene Klasse, sondern auch eine Unterklasse eines allgemeinen BayesianNetwork Modells. Dieses allgemeine Modell sind einige Funktionen verwenden, die außer Kraft gesetzt werden. Stroustrup würde stolz sein.
- Machen Sie mehrere Funktionen in der gleichen Klasse, die die verschiedenen Wahrscheinlichkeiten berechnen.
- -Code eine allgemeine BayesianNetwork Bibliothek und meine Inferenzprobleme implementieren als spezifische grafische Darstellungen in dieser Bibliothek lesen. Die Knoten und Kanten sollten Eigenschaften wie „Boolean“ und „OrFunction“ gegeben werden, die bei bekannten Zustände des Elternknotens, verwendet werden können, um die Wahrscheinlichkeiten der unterschiedlichen Ergebnissen zu berechnen. Diese Eigenschaft Strings wie „OrFunction“ könnte auch verwendet werden, um nachzuschlagen und rufen Sie die richtige Funktion. Vielleicht in ein paar Jahren werde ich etwas ähnliches wie die 1988-Version von Mathematica machen!
Vielen Dank für Ihre Hilfe.
Update: Objektorientierte Ideen helfen, eine Menge hier (jeder Knoten einen bestimmten Satz von Vorgängerknoten eines bestimmten KnotensSubtyp, und jeder Knoten hat eine Wahrscheinlichkeitsfunktion, die seine Wahrscheinlichkeit einer anderen Ergebnis Staaten angesichts der Zustände der Vorgängerknoten berechnet, etc.). OOP FTW!
Lösung
Ich habe schon eine ganze Weile in meiner Freizeit auf dieser Art der Sache gearbeitet. Ich glaube, ich bin auf dem dritten oder vierten Version dieses gleiche Problem jetzt. Ich bin eigentlich immer bereit, eine andere Version von Fathom freizugeben (https://github.com/davidrichards/fathom/wiki) mit dynamischer Bayes-Modelle enthalten und eine andere Persistenz-Schicht.
Als ich versucht habe, meine Antwort klar zu machen, ist es ziemlich lang geworden. Ich entschuldige mich dafür. Hier ist, wie ich habe das Problem angegriffen, die einige Ihrer Fragen (etwas indirekt) zu beantworten scheint:
Ich habe mit Judea Pearl Zusammenbruch des Glaubens Ausbreitung in einem Bayes-Netzwerk gestartet. Das heißt, es ist ein Diagramm mit vorheriger odds (kausale Unterstützung), die von Eltern und Wahrscheinlichkeiten (Diagnoseunterstützung) von Kindern kommen. Auf diese Weise ist die Basisklasse nur ein BeliefNode, viel wie das, was Sie mit einem zusätzlichen Knoten zwischen BeliefNodes beschrieben, ein LinkMatrix. Auf diese Weise wähle ich ausdrücklich die Art der Wahrscheinlichkeit durch die Art der LinkMatrix I Verwendung Ich verwende. Es macht es einfacher zu erklären, was der Glaube Netzwerk danach sowie hält die Berechnung einfacher macht.
Jede Subklassifizieren oder Änderungen, die ich an der Grund BeliefNode für kontinuierliche Variablen Binning wäre machen würde, anstatt Propagierungsregeln oder Knotenzuordnungen zu ändern.
Ich habe auf der Beibehaltung aller Daten innerhalb des BeliefNode entschieden, und nur Daten in der LinkedMatrix fixiert. Dies hat damit zu tun, um sicherzustellen, dass ich sauber Glauben Updates mit minimaler Netzwerkaktivität aufrechtzuerhalten. Das bedeutet, dass mein BeliefNode speichert:
- eine Reihe von Kindern Referenzen sowie die gefilterten Wahrscheinlichkeiten von jedem Kind kommen und die Verbindungsmatrix, die die Filterung für das Kind tut
- ein Feld von Mutterreferenzen, zusammen mit dem gefilterten vorherigen odds von jedem Elternteil kommen und der Verbindungsmatrix, die die Filterung für das Mutter tut
- die kombinierte Wahrscheinlichkeit des Knotens
- die vereinigten vor Chancen des Knotens
- der berechnete Glaube oder posterior Wahrscheinlichkeit
- eine geordnete Liste von Attributen, dass alle vor Chancen und Wahrscheinlichkeiten, um sie an
Die LinkMatrix kann mit einer Reihe von verschiedenen Algorithmen konstruiert werden, abhängig von der Art der Beziehung zwischen den Knoten. Alle Modelle, dass Sie beschreiben nur verschiedene Klassen sein würde, dass Sie beschäftigen würde. Wahrscheinlich ist die einfachste Sache zu tun Standard auf ein Oder-Gatter, und dann andere Wege wählen, um den LinkMatrix handhaben, wenn wir eine besondere Beziehung zwischen den Knoten haben.
Ich verwende MongoDB für die Persistenz und Caching. I Zugriff auf diese Daten innerhalb eines evented Modell für die Geschwindigkeit und asynchronen Zugriff. Dies macht das Netzwerk recht performant, während auch die Möglichkeit haben, sehr groß sein, wenn es sein muss. Auch, weil ich auf diese Weise Mongo ich verwende, kann ich einfach einen neuen Kontext für die gleiche Wissensbasis schaffen. So zum Beispiel, wenn ich einen Diagnosebaum haben, einige der diagnostische Unterstützung für eine Diagnose kommt von den Symptomen eines Patienten und Tests. Was ich tue, ist es, einen Kontext für die Patienten zu schaffen und dann meinen Glauben verbreitet auf der Grundlage der Beweise von diesen bestimmten Patienten. Ebenso, wenn ein Arzt sagte, dass ein Patient wahrscheinlich zwei oder mehr Krankheiten erlebte, dann könnte ich einige meiner Link Matrizen ändern unterschiedlich die Überzeugung Updates zu propagieren.
Wenn Sie nicht für Ihr System so etwas wie Mongo verwenden möchten, aber Sie sind Planung auf, die mehr als ein Verbraucher auf der Wissensbasis arbeiten, müssen Sie irgendeine Art von Caching-System zu übernehmen, um sicherzustellen, dass Sie arbeiten an frisch aktualisierten Knoten zu allen Zeiten.
Meine Arbeit ist Open Source, so dass Sie folgen zusammen können, wenn Sie möchten. Es ist alles Rubin, so würde es zu einem Python ähnlich sein, aber nicht unbedingt ein Drop-in-Ersatz. Eine Sache, die ich über mein Design mag, ist, dass alle Informationen für die Menschen notwendig, um die Ergebnisse zu interpretieren kann in t gefunden werdener Knoten selbst, anstatt im Code. Dies kann in den qualitativen Beschreibungen oder in der Struktur des Netzes erfolgen.
So, hier sind einige wichtige Unterschiede, die ich mit Ihrem Design haben:
- Ich berechnen nicht die Wahrscheinlichkeit Modell innerhalb der Klasse, sondern zwischen den Knoten innerhalb der Link-Matrix. Auf diese Weise habe ich nicht das Problem innerhalb der gleichen Klasse mehr Wahrscheinlichkeitsfunktionen kombiniert. Ich habe auch nicht das Problem eines Modells gegenüber einem anderen, kann ich für die gleiche Wissensbasis verwenden zwei unterschiedlichen Kontexten nur und vergleichen Sie die Ergebnisse.
- Ich füge viel Transparenz durch die menschliche Entscheidungen offensichtlich zu machen. Das heißt, wenn ich ein Standard-oder-Gatter zwischen zwei Knoten verwenden entscheiden, weiß ich, wenn ich fügte hinzu, dass und dass es nur eine Standard-Entscheidung war. Wenn ich später wieder kommen und die Link-Matrix ändern und neu zu berechnen, um die Wissensbasis, habe ich eine Notiz, warum ich das tat, und nicht nur eine Anwendung, die ein Verfahren gegenüber einem anderen gewählt hat. Sie könnten Ihre Verbraucher machen sich Notizen über diese Art der Sache haben. Jedoch, dass Sie zu lösen, ist es wahrscheinlich eine gute Idee, den stufenweisen Dialog aus dem Analytiker zu bekommen, warum sie die Dinge einen Weg über eine andere setzen.
- kann ich vor Odds und Wahrscheinlichkeiten deutlicher sein. Ich weiß es nicht genau auf das, ich sehe nur, dass man verschiedene Modelle wurden mit Ihrer Wahrscheinlichkeit Zahlen zu ändern. Vieles von dem, was ich sage sein kann, völlig irrelevant, ob Ihr Modell zur Berechnung posterior Überzeugungen nicht auf diese Weise brechen. I haben den Vorteil, in der Lage, drei asynchrone Schritte zu machen, die in beliebiger Reihenfolge aufgerufen werden können: verändert Likelihoods bis das Netzwerk passieren, passiert geändert vor odds unten im Netzwerk und neu zu berechnen, das kombinierte Glauben (posterior Wahrscheinlichkeits) des Knotens selbst .
Ein großer Nachteil: einige von dem, was ich rede ist über noch nicht freigegeben. Ich arbeitete an dem Zeug ich spreche, bis etwa 02.00 Uhr an diesem Morgen, so ist es auf jeden Fall Strom und auf jeden Fall regelmäßig die Aufmerksamkeit von mir bekommen, ist aber nicht alle der Öffentlichkeit zugänglich nur noch. Da dies eine Leidenschaft von mir ist, würde ich an einem Projekt Frage oder zusammenarbeiten, um zu beantworten, glücklich sein, wenn Sie möchten.
Andere Tipps
Die Mozart / OZ3 Constraints-basierten Deduktionssystems löst ein ähnliches Problem: Sie beschreiben Ihr Problem in hinsichtlich der Einschränkungen für endlichen Bereich Variablen, Constraint Verbreiter und Händler, Kostenfunktionen. Wenn nicht mehr Folgerung möglich ist, aber es gibt noch ungebundene Variablen, verwendet es Funktionen, um Ihre Kosten das Problem Raum auf der ungebundene Variable aufteilen, die am wahrscheinlichsten Suchkosten reduziert: das heißt, wenn X zwischen [a, c] ist eine solche Variable und c (a numpy verwenden verschiedene Strategien zu kopieren, zu minimieren, wenn Sie Ihre Diagrammdarstellung auf sie stützen, können Sie copy-on-write Semantik erhalten für:
Sie können sicher ein Copy-on-Write-Schema in einer Grafik-basierte Bibliothek (Spitze implementieren frei) und Ihre Ziele erreichen.
Ich bin nicht allzu vertraut mit Bayesian Networks, so dass ich folgende hoffen ist nützlich:
In der Vergangenheit hatte ich ein scheinbar ähnliches Problem mit einem Gauß-Prozess Regressor, anstelle einer Bayes-Klassifikator.
beenden ich mit Vererbung auf, die schön ausgearbeitet. Alle modellspezifischen paremeters werden mit dem Konstruktor festgelegt. Die calculate () Funktionen sind virtuell. Kaskadieren verschiedene Methoden (beispielsweise ein Summe-Methode, die eine beliebige Anzahl von anderen Verfahren kombiniert) auch gut auf diese Weise funktioniert.
Ich glaube, Sie brauchen ein paar Fragen zu stellen, die den Entwurf beeinflussen.
- Wie oft werden Sie fügen Modelle?
- Sind die Verbraucher Ihrer Bibliothek erwartet neue Modelle hinzufügen?
- Was Prozent der Anwender das Hinzufügen werden Modelle vs wie viel Prozent wird bestehende verwenden?
Wenn die meiste Zeit mit bestehenden Modelle und neue Modelle ausgegeben werden weniger häufig, dann Vererbung ist wahrscheinlich der Entwurf, den ich verwenden würde. Es macht die Dokumentation einfach zu Struktur und den Code, der verwendet es einfach sein wird, zu verstehen.
Wenn der Hauptzweck der Bibliothek, eine Plattform zu schaffen, ist mit verschiedenen Modellen für das Experimentieren, dann würde ich die Grafik mit Eigenschaften nehmen, die für die Berechnung Dinge functors Karte basierend auf Eltern. Die Bibliothek wäre komplexer und Diagrammerstellung wäre komplizierter, aber es wäre viel mächtiger sein, wie es Ihnen Hybrid-Graphen zu tun erlauben würde, die die Berechnung Funktors ändern den Knoten basiert.
Unabhängig davon, was endgültiges Design Sie zu arbeiten, würde ich mit einem einfachen Klasse-one Implementierung Design starten. Holen Sie sich eine Reihe von automatisierten Tests vorbei, dann Refactoring in die weitere vollständige Design danach erfolgt. Auch nicht vergessen, Versionskontrolle; -)

{kind=link}