la mise en œuvre pythonique des réseaux bayésiens pour une application spécifique
 https://stackoverflow.com/questions/3783708
https://stackoverflow.com/questions/3783708
-
05-10-2019 - |
 italiano
italiano english
english français
français española
española 中国
中国 日本の
日本の العربية
العربية Deutsch
Deutsch 한국어
한국어 Português
Português Russian
RussianQuestion
Voilà pourquoi je pose cette question: L'année dernière, j'ai fait un peu de code C ++ pour calculer des probabilités a posteriori pour un type particulier de modèle (décrit par un réseau bayésien). Le modèle fonctionnait assez bien et d'autres gens ont commencé à utiliser mon logiciel. Maintenant, je veux améliorer mon modèle. Depuis que je suis le codage déjà des algorithmes d'inférence légèrement différentes pour le nouveau modèle, j'ai décidé d'utiliser python parce que l'exécution n'a pas été très important et python peut me laisser rendre le code plus élégant et facile à gérer.
En général, dans cette situation, je recherche d'un paquet réseau bayésien existant en python, mais les algorithmes d'inférence que je utilise sont les miennes, et je pensais aussi que ce serait une excellente occasion d'en savoir plus sur un bon design en python .
Je l'ai déjà trouvé un module python pour les graphiques de réseau (NetworkX), qui vous permet de joindre un dictionnaire à chaque nœud et à chaque bord. Essentiellement, cela me laisserait donner des propriétés des noeuds et des arêtes.
Pour un réseau particulier et ses données observées, je dois écrire une fonction qui calcule la probabilité des variables non affectées dans le modèle.
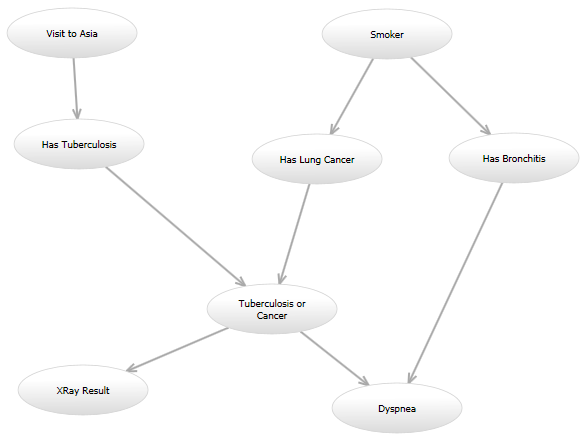
Par exemple, dans le réseau "Asie" classique ( http: //www.bayesserver .com / Ressources / Images / AsiaNetwork.png ), avec les états de « XRay Résultat » et « Dyspnée » connu, je dois écrire une fonction pour calculer la probabilité que les autres variables ont certaines valeurs (selon certains modèles).
Voici ma question de programmation: Je vais essayer une poignée de modèles, et dans l'avenir, il est possible que je vais essayer un autre envie modèle après. Par exemple, un modèle pourrait ressembler exactement comme le réseau Asie. Dans un autre modèle, un bord dirigé peut être ajouté de « Visite à l'Asie » à « A cancer du poumon. » Un autre modèle pourrait utiliser le graphique dirigé d'origine, mais le modèle de probabilité pour le noeud « Dyspnée » étant donné les noeuds « La tuberculose ou le cancer » et « A Bronchite » peuvent être différents. Tous ces modèles calculera la probabilité d'une manière différente.
Tous les modèles auront un chevauchement important; par exemple, plusieurs arêtes d'entrer dans un « Ou » noeud sera toujours faire un « 0 » si toutes les entrées sont « 0 » et « 1 » autrement. Mais certains modèles ont des noeuds qui prennent des valeurs entières dans une certaine gamme, tandis que d'autres seront booléen.
Dans le passé, je l'ai eu du mal avec la façon dont les choses du programme comme celui-ci. Je ne vais pas mentir; il y a eu une quantité juste code copié et collé et parfois j'ai besoin pour propager les modifications dans une seule méthode pour plusieurs fichiers. Cette fois, je vraiment veulent passer le temps de le faire de la bonne façon.
Certaines options:
- je faisais déjà ce la bonne voie. Code d'abord, poser des questions plus tard. Il est plus rapide de copier et coller le code et ont une classe pour chaque modèle. Le monde est un endroit sombre et lieu désorganisé ...
- Chaque modèle est sa propre classe, mais aussi une sous-classe d'un modèle de BayesianNetwork général. Ce modèle général utilisera certaines fonctions qui vont être surchargée. Stroustrup serait fier.
- Faire plusieurs fonctions dans la même classe que les différents calculent vraisemblances.
- code une bibliothèque BayesianNetwork générale et mettre en œuvre mes problèmes d'inférence sous forme de graphiques spécifiques lus par cette bibliothèque. Les noeuds et les arêtes doivent être donnés propriétés comme « booléen » et « OrFunction » qui, étant donné les états connus du noeud parent, peut être utilisé pour calculer les probabilités des résultats différents. Ces chaînes de propriété, comme « OrFunction » pourraient même être utilisés pour rechercher et appeler la fonction droite. Peut-être que dans quelques années, je vais faire quelque chose de similaire à la version 1988 de Mathematica!
Merci beaucoup pour votre aide.
Mise à jour: idées orienté objet d'une grande aide ici (chaque noeud a un ensemble désigné de nœuds prédécesseurs d'un certain noeudsous-type, et chaque noeud a une fonction de vraisemblance qui calcule la probabilité de différents états de résultats étant donné les états des noeuds prédécesseurs, etc.). POO FTW!
La solution
Je travaille sur ce genre de chose dans mon temps libre pendant un certain temps. Je pense que je suis à mon troisième ou quatrième version de ce même problème en ce moment. Je suis en fait le point de sortir une autre version de Fathom (https://github.com/davidrichards/fathom/wiki) avec des modèles bayésiens dynamiques inclus et une couche de persistance différente.
Comme je l'ai essayé de faire ma réponse claire, il est obtenu assez long. Je m'excuse pour cela. Voilà comment j'ai attaquer le problème, qui semble répondre à certaines de vos questions (un peu indirectement):
Je l'ai commencé avec la rupture de la propagation de la croyance en un réseau bayésien de Judea Pearl. Autrement dit, il est un graphique avec des cotes avant (soutien de cause à effet) provenant de parents et vraisemblances (soutien de diagnostic) provenant d'enfants. De cette façon, la classe de base est juste un BeliefNode, un peu comme ce que vous avez décrit avec un nœud supplémentaire entre BeliefNodes, un LinkMatrix. De cette façon, je choisis de façon explicite le type de risque que je utilise le type d'utilisation LinkMatrix I. Il est plus facile d'expliquer ce que le réseau de croyance fait par la suite, ainsi que le calcul tient plus simple.
Tout ou subclassing changements que je ferais au BeliefNode de base serait pour binning variables continues, plutôt que de changer les règles de propagation ou d'associations de noeuds.
Je l'ai décidé à garder toutes les données à l'intérieur du BeliefNode, et seules les données fixes dans le LinkedMatrix. Cela a à voir avec veiller à ce que je maintiens des mises à jour de croyances propres à l'activité du réseau minimale. Cela signifie que mes magasins BeliefNode:
- un tableau de références pour les enfants, ainsi que les vraisemblances filtrés provenant de chaque enfant et la matrice de liaison qui fait le filtrage pour cet enfant
- un tableau de références mères, ainsi que les probabilités antérieures filtrés provenant de chaque parent et la matrice de liaison qui est en train de faire le filtrage pour que parent
- la probabilité combinée du noeud
- les probabilités antérieures combinées du noeud
- la croyance calculée, ou la probabilité postérieure
- une liste ordonnée des attributs que toutes les chances avant et vraisemblances adhérer à
Le LinkMatrix peut être construit avec un certain nombre d'algorithmes différents, en fonction de la nature de la relation entre les nœuds. Tous les modèles que vous décrivez serait juste différentes classes que vous souhaitez employez. Probablement la meilleure chose à faire est par défaut à une ou porte, puis choisissez d'autres façons de gérer l'LinkMatrix si nous avons une relation spéciale entre les nœuds.
J'utilise MongoDB pour la persistance et la mise en cache. J'accéder à cet intérieur de données d'un modèle evented pour la vitesse et l'accès asynchrone. Cela rend le réseau assez performant tout en ayant la possibilité d'être très grand si elle a besoin d'être. En outre, depuis que je suis en utilisant Mongo de cette façon, je peux facilement créer un nouveau contexte pour la même base de connaissances. Ainsi, par exemple, si j'ai un arbre de diagnostic, une partie du soutien de diagnostic pour un diagnostic proviendra des symptômes et des tests d'un patient. Ce que je fais est de créer un contexte pour le patient et propager mes croyances fondées sur les preuves de ce patient particulier. De même, si un médecin a dit qu'un patient connaissait probablement deux maladies ou plus, alors je pourrais changer certaines de mes matrices de liens pour propager les croyances différentes mises à jour.
Si vous ne voulez pas utiliser quelque chose comme Mongo pour votre système, mais vous prévoyez d'avoir plus d'un consommateur travaillant sur la base de connaissances, vous aurez besoin d'adopter une sorte de système de mise en cache pour vous assurer que vous êtes travaillant sur des noeuds fraîchement mis à jour à tout moment.
Mon travail est open source, afin que vous puissiez suivre si vous le souhaitez. Il est tout Ruby, donc il serait semblable à votre Python, mais pas nécessairement un remplacement sans rendez-vous. Une chose que j'aime ma conception est que toutes les informations nécessaires à l'homme pour interpréter les résultats peuvent être trouvés dans til se nœuds, plutôt que dans le code. Cela peut se faire dans les descriptions qualitatives, ou dans la structure du réseau.
Alors, voici quelques différences importantes que j'ai avec votre conception:
- Je ne calcule pas le modèle de vraisemblance dans la classe, mais plutôt entre les nœuds, à l'intérieur de la matrice de lien. De cette façon, je n'ai pas le problème de combiner plusieurs fonctions de vraisemblance dans la même classe. Je n'ai pas aussi le problème d'un modèle par rapport à une autre, je peux utiliser deux contextes différents pour la même base de connaissances et comparer les résultats.
- J'ajoute beaucoup de transparence en rendant les décisions humaines apparente. À savoir, si je décide d'utiliser une valeur par défaut ou la porte entre deux nœuds, je sais quand j'ajouté que et qu'il était juste une décision par défaut. Si je reviens plus tard et changer la matrice de lien et recalcule la base de connaissances, j'ai une note sur la raison pour laquelle je l'ai fait, plutôt que de simplement une application qui a choisi une méthode sur une autre. Vous pourriez avoir vos consommateurs de prendre des notes sur ce genre de chose. Cependant, vous résoudre cela, il est probablement une bonne idée d'obtenir la boîte de dialogue étape par étape de l'analyste pourquoi ils mettent les choses d'une manière sur une autre.
- Je peux être plus explicite sur les chances avant et vraisemblances. Je ne suis pas sûr à ce sujet, je viens de voir que vous utilisiez différents modèles pour changer vos numéros de vraisemblance. Une grande partie de ce que je dis peut être complètement hors de propos si votre modèle pour le calcul des croyances postérieures ne se dégrade pas de cette façon. J'ai l'avantage d'être en mesure de faire trois étapes asynchrones qui peuvent être appelées dans l'ordre: passer changé vraisemblances le réseau, passer changé odds avant sur le réseau, et recalcule la croyance combinée (probabilité postérieure) du nœud lui-même .
Une grande mise en garde: une partie de ce dont je parle est de ne pas encore été publié. Je travaillais sur les choses dont je parle jusqu'à environ 02h00 ce matin, donc il est certainement en cours et obtenir certainement une attention régulière de moi, mais ne sont pas tous disponibles au public pour l'instant. Puisque c'est ma passion, je serais heureux de répondre à vos questions ou de travailler ensemble sur un projet si vous le souhaitez.
Autres conseils
Je ne suis pas trop familier avec Bayesian Networks, donc j'espère que ce qui suit est utile:
Dans le passé, j'ai eu un problème apparemment similaire avec un régresseur Process gaussienne, au lieu d'un classificateur bayésien.
Je fini par utiliser l'héritage, qui a bien fonctionné. Tous paremeters modèle spécifiques sont définis avec le constructeur. Les fonctions calculate () sont virtuels. Cascadant différentes méthodes (par exemple une somme méthode qui combine un nombre arbitraire d'autres méthodes) fonctionne aussi bien de cette façon.
Je pense que vous devez vous poser deux ou trois questions qui influencent la conception.
- Combien de fois allez-vous ajouter des modèles?
- Les consommateurs sont de votre bibliothèque devraient ajouter de nouveaux modèles?
- Qu'est-ce que pour cent des utilisateurs sera l'ajout de modèles vs ce que pour cent utiliseront ceux qui existent déjà?
Si la plupart du temps sera consacré à des modèles et de nouveaux modèles existants seront moins fréquents, alors l'héritage est probablement la conception que j'utiliserais. Il rend la documentation facile à la structure et le code qui l'utilise sera facile à comprendre.
Si le but principal de la bibliothèque est de fournir une plate-forme d'expérimentation avec des modèles différents, alors je prendrais le graphique avec des propriétés qui correspondent à foncteurs pour les choses de calcul basées sur les parents. La bibliothèque serait plus complexe et la création graphique serait plus complexe, mais il serait beaucoup plus puissant car il vous permettra de faire des graphiques hybrides qui changent le foncteur de calcul basé sur les nœuds.
Quelle que soit la conception finale vous travaillez vers, je voudrais commencer par une simple conception de la mise en œuvre de classe un. Obtenez faisant passer une série de tests automatisés, factoriser puis dans la conception plus complète après cela est fait. En outre, ne pas oublier le contrôle de version; -)

{kind=link}