What is the semantic web? [closed]
 https://stackoverflow.com/questions/725261
https://stackoverflow.com/questions/725261
-
05-09-2019 - |
 italiano
italiano english
english français
français española
española 中国
中国 日本の
日本の العربية
العربية Deutsch
Deutsch 한국어
한국어 Português
Português Russian
RussianQuestion
I've heard a lot about the semantic web but I'm still not exactly sure what it is. How will it be different to the web we know now?
Solution
How will it be different to the web we know now?
Right now the HTML+CSS is centered more on structure and presentation. Semantics is about the meaning of the information. In semantic web you use shared ontologies to establish meaning (semantic) of the object and meaning of relations between the objects. Best known ontologies are: FOAF and Dublin Core.
Typically semantics would be expressed in specialized language, such as RDF or OWL. RDF can be embedded within XHTML using eRDF or W3C's RDFa.
Less structured alternative to eRDF/RDFa are microformats.
Read more at: http://en.wikipedia.org/wiki/Semantic_web
OTHER TIPS
The best explanation is by example. Try googling for all cars advertised on the web with engines smaller than 2.0 litres that run unleaded, and have an mp3 connection and can been seen in a showroom conveniently accessible by public transport from my house.
Google just won't be able to help you with that query, not really. You have to make several searches and correlate the results yourself. On the Semantic web, you'd be able to express an interest in products for sale that are cars, and add the constraints. Every result would be useful. One or more UIs might enable you to do that, some may be specialized, others entirely generic.
An other example, creating a chart of things not normally stored in one place, say the popularity of diet coke, or country walks in a population versus the levels of clinical obesity in the same population. For these you may not use a web browser at all, but might use something more like Excel - but the semantic web gives you tools (SPARQL, RDF) for finding and manipulating the data that is out there and is accessible via HTTP.
So the point made by Bravax is not entirely true, not a lot may change - you may merely get some more useful and better mashup web sites. Or you may find yourself doing a whole lot of stuff you never thought of as being related to the web before today.
The current web has lots of alternatives for doing the same thing, say Animated GIFs, Flash, Silverlight, DHTML etc. For putting data on the semantic web there will be a range of tools and formats. RDFa is a good one, a more general type of microformat, but you could provide a dump of the whole database, expose a SPARQL endpoint, use a microformat or a proprietary HTML structure and add a transformation, there will be many tools to suit different cases.
So Vartec is also partially right, you may use RDFa and eRDF but you could also use a whole lot of other things for publishing data.
Note that there is a lot over overlap between the semantic web and another simper concept called Linked Data. How they relate to each other isn't clear, but my perception of it is that the Linked Data web is what you need before Semantic Web tools and techniques have anything to do. Linked Data is about data, the semantic web is more about processing the data, reasoning over it and handling issues like trust reliability and such like. Essentially the bottom few layers of the technology stack.
The Semantic Web is at heart a really simple idea. (Like all the good ones.)
The Web at present consists of documents with links between them. Google have made a pretty good business out of using context, and anchor text within the links, to work out what the links mean and build an engine for retrieving data based on that. In other words, Google guesstimate what the semantic meaning of a link is.
The Semantic Web idea is "what if these links were typed?" Every fact on the Web gets an address - a URI - and is linked to other facts (also URIs) by relations (also URIs). Groups of relations are called "ontologies".
So instead of page A links to page B, like on the current web, links on the Semantic Web are more like:
URI A links to URI B with a link of type URI C.
Anything can have a URI. People can have URIs; usually we use a set of relations called FOAF to describe them. So let's say the URI for Jeff Atwood is http://codinghorror.com/foaf.xml; then you could say:
<http://codinghorror.com> <http://xmlns.com/foaf/0.1/homepage> <http://codinghorror.com/foaf.xml>
ie, http://codinghorror.com is the homepage of the person represented by the contents of http://codinghorror.com/foaf.xml.
Now machines can read, and query, these relationships - so you turn the Web into a database that computers can immediately do something with. The Semantic Web query language is SPARQL, and it's worth checking out.
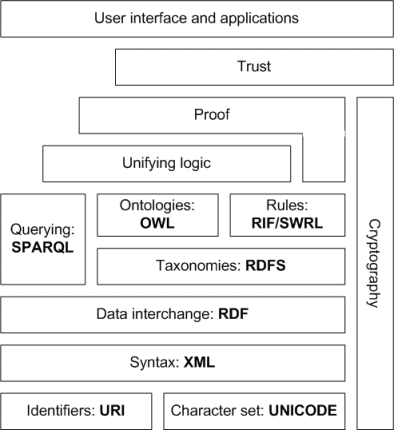
The Semantic Web is just that - a Semantic (meaningful) layer on top of the WWW. It is semi structured (RDF), it is self-describing (ontologies using OWL), and allows resource discovery (SPARQL).
The Semantic Web works on the premise of the "Open World" assumption; just because something is not stated doesn't mean it doesn't exist, it is simply "unknown". This is a fundamentally different logic to that used in an RDBMS like MySQL et al. - if something is missing it doesn't exist - "Closed World" assumption. Prolog and DATALOG are good examples of Close World logics.
If you want to really learn what is happening underneath, you'll need to look at its foundations, which lie in Description Logic. A good overview of the Description Logic can be found here: http://www.inf.unibz.it/~franconi/dl/course/
If you want to learn more about RDF, read the RDF Primer. RDF Semantics is another rip-roaring read.
Researchers have basically given up on the "Semantic" part of the Semantic Web and decided to focus on Linked Data - how RDF triples can be navigated so that we can waste more Internet bandwidth ;-)
Currently with HTML pages we have markup tags which describe how content should be displayed, <b>, '<pre>, etc. These tags imply no meaning about their content.
The concept of a semantic web is that documents would contain XML tags that do imply meaning about their content. For example <person><firstname>. The grand idea is that CSS would be able to format documents such as these but it would also be possible to extract meaningful info easily from these documents.
The Semantic Web is what Tim Berners-Lee, the inventor of the World Wide Web, really intended the Web to be—that is, a global graph of interlinked data. It is a generalization of a social graph, where you can use social data (with vocabularies like FOAF) as well as any other kind of machine-understandable data and connect them to each other. The standard formats for describing this infortmation to machines is the Resource Description Format (RDF) and the Web Ontology Language (OWL). There's already a lot of encoded data on the Web, including an RDF version of Wikipedia, called DBPedia.
The Semantic Web will be different than today's Web in that computers as well as humans will understand what documents contain as well as what the significance of the links between documents are. This will facilitate automation of information-processing tasks, including researching information from trustworthy sources. The full SemWeb stack includes cryptography, proof systems, and trust networks.
Tim Berners-Lee describes it in his blog post Giant Global Graph (from 2007-11-21):
Three mental moves:
- Internet: "It isn't the cables, it is the computers which are interesting"
- (World Wide) Web: "It isn't the computers, but the documents which are interesting"
- Giant Global Graph: "It's not the documents, it is the things they are about which are important"
About the term "Giant Global Graph":
We can use the word Graph, now, to distinguish from Web.
I called this graph the Semantic Web, but maybe it should have been Giant Global Graph! Any worse than WWWW? ;-) Not the "Semantic Web" term has been established for a long time, I'm not proposing to change it. But let's think about the graph which it is. (Footnote: "Graph" also happens to be the word the RDF specifications use, but that is by the way. While an XML parser creates a DOM tree, an RDF parser creates an RDF graph in memory.)
Semantic web is the only pragmatic solution proposed so far to repair inherent design flaws of World Wide Web. Because the designers of the internet, as we know it today, did not provide mechanisms which would address fundamental linguistic phenomenons which govern the way humans think and communicate such as homonymy, synonymy etc. searching for information on the internet results in a flood of false positives. The idea of semantic web boils down to assigning unequivocal identifiers to web resources which will help identify their meaning correctly. If it succeeds one day we may forget what the usual google search looked like, if it fails all will remain as it is now.
It's a buzz word to attract people's interest, Similiar to Web 2.0
I.e. In the future content will be split from presentation allowing much goodness.
In reality Facts will be subjective, depending on the realibility and authority of the host.
In other words, users won't see much difference from now.
The Semantic Web is a distributed information system where interlinked data is published as RDF triples over HTTP. RDF triples consist of subject, predicate and object but can have other things attached to them such as datatypes and annotations about the natural language of objects. On the Semantic Web, URIs are used both as identifiers and as addresses of network resources.
It’s different from the Web, because the Web is a distributed information system of documents and application interfaces.

{kind=link}