Qu'est-ce que le web sémantique? [fermé]
 https://stackoverflow.com/questions/725261
https://stackoverflow.com/questions/725261
-
05-09-2019 - |
 italiano
italiano english
english français
français española
española 中国
中国 日本の
日本の العربية
العربية Deutsch
Deutsch 한국어
한국어 Português
Português Russian
RussianQuestion
J'ai entendu beaucoup de choses sur le web sémantique mais je ne suis toujours pas sûr de ce qu'il est. Comment sera-ce différent du web que nous savons maintenant?
La solution
Comment sera-ce différent du web que nous savons maintenant?
En ce moment le HTML + CSS est centrée plus sur la structure et la présentation. Sémantique est sur le sens de l'information. Dans le web sémantique vous commun ontologies pour établir sens (sémantique) de l'objet et la signification des relations entre les objets. ontologies les plus connus sont: FOAF et Dublin Core .
Typiquement sémantique seraient exprimés en langage spécialisé, comme RDF ou OWL . RDF peut être intégré dans XHTML en utilisant eRDF ou W3C RDFa .
alternative moins structuré à ERDF / RDFa sont microformats .
En savoir plus: http://en.wikipedia.org/wiki/Semantic_web
Autres conseils
La meilleure explication est par exemple. Essayez googler pour toutes les voitures annoncés sur le web avec des moteurs plus petits que 2,0 litres qui exécutent sans plomb, et qui ont une connexion mp3 et peut être vu dans une salle d'exposition facilement accessible par les transports en commun de ma maison.
Google juste ne sera pas en mesure de vous aider à cette requête, pas vraiment. Vous devez effectuer plusieurs recherches et établir une corrélation entre les résultats vous. Sur le web sémantique, vous seriez en mesure d'exprimer un intérêt pour les produits à vendre qui sont les voitures, et ajouter les contraintes. Chaque résultat serait utile. Un ou plusieurs UIs pourraient vous permettre de faire cela, certains peuvent être spécialisés, d'autres tout à fait générique.
Un autre exemple, la création d'un tableau des choses normalement stockées dans un seul endroit, par exemple la popularité de coke de régime, ou de longues balades dans une population par rapport aux niveaux de l'obésité clinique dans la même population. Pour ceux-ci, vous ne pouvez pas utiliser un navigateur Web du tout, mais peut-être utiliser quelque chose comme Excel - mais le web sémantique vous fournit des outils (SPARQL, RDF) pour rechercher et manipuler les données qui sont là-bas et est accessible via HTTP.
Ainsi, le point fait par Bravax est pas tout à fait vrai, pas beaucoup peut changer - vous pouvez simplement obtenir des plus utiles et de meilleurs sites web mashup. Ou vous pouvez vous retrouver à faire un tas de choses que vous jamais pensé comme étant lié à la bande avant aujourd'hui.
Le Web actuel a beaucoup d'alternatives pour faire la même chose, dire Gifs animés, Flash, Silverlight, etc. DHTML Pour mettre les données sur le web sémantique, il y aura une gamme d'outils et formats. RDFa est un bon, un type plus général de microformat, mais vous pouvez fournir une décharge de la base de données entière, exposer une SPARQL point final , utilisez un microformat ou structure HTML exclusive et ajouter un de transformation, il y aura de nombreux outils pour convenir à différents cas.
Vartec est également partiellement raison, vous pouvez utiliser RDFa et eRDF mais vous pouvez aussi utiliser beaucoup d'autres choses pour la publication des données.
Notez qu'il ya beaucoup plus de chevauchement entre le web sémantique et un autre concept Simper appelé Lié données. Comment ils se rapportent les uns aux autres ne sont pas claires, mais ma perception est que le Web Linked Data est ce que vous avez besoin avant les outils du Web sémantique et techniques ont rien à faire. Les données liées est de données, le web sémantique est plus sur le traitement des données, le raisonnement et sur le traitement des questions comme la fiabilité de la confiance et autres. Essentiellement, les couches inférieures de quelques la pile de technologie .
Le Web sémantique est au cœur d'une idée très simple. (Comme tous les bons.)
Le Web à l'heure actuelle se compose de documents avec des liens entre eux. Google a fait une très bonne affaire sur utilisant le contexte et le texte d'ancrage dans les liens, de comprendre ce que les liens signifient et construire un moteur pour récupérer des données sur cette base. En d'autres termes, Google ce que le sens essayer de calculer sémantique d'un lien est.
L'idée du Web sémantique est « si ces liens ont été typés? » Chaque fait sur le Web obtient une adresse - un URI - et est lié à d'autres faits (également URIs) par les relations ( aussi URIs). Des groupes de relations sont appelés "ontologies".
Ainsi, au lieu de la page A des liens vers la page B, comme sur le Web en cours, des liens sur le Web sémantique sont plus comme:
A URI URI liens vers B avec un lien du type d'URI C.
Tout peut avoir un URI. Les gens peuvent avoir URIs; En général, nous utilisons un ensemble de relations appelé FOAF pour les décrire. Alors disons que l'URI de Jeff Atwood est http://codinghorror.com/foaf.xml ; vous pourriez dire:
<< a href = "http://codinghorror.com" rel = "noreferrer"> http://codinghorror.com > << a href = "http://xmlns.com/foaf /0.1/homepage "rel = "noreferrer"> http://xmlns.com/foaf/0.1/homepage > << a href = "http://codinghorror.com/foaf.xml" rel =" noreferrer "> http://codinghorror.com/foaf.xml >
par exemple, http://codinghorror.com est la page d'accueil de la personne représentée par le contenu de http://codinghorror.com/foaf.xml .
machines peuvent lire et requête, ces relations - donc vous tournez le Web dans une base de données que les ordinateurs peuvent immédiatement faire quelque chose avec. Le langage de requête Web sémantique est SPARQL, et il vaut la peine de vérifier.
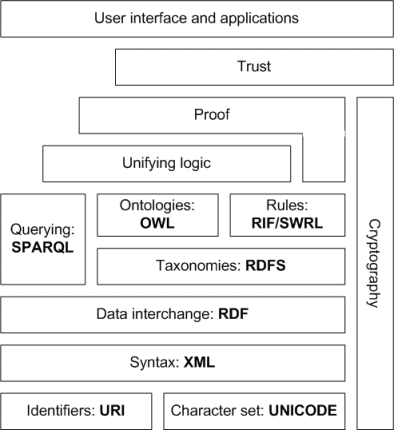
Le Web sémantique est juste que - une couche sémantique (sens) au-dessus du WWW. Il est semi structuré (RDF), il est autodescriptifs (ontologies OWL) à l'aide, et permet la découverte de ressources (SPARQL).
Le Web sémantique fonctionne sur le principe de l'hypothèse « Open World »; juste parce que quelque chose ne dit ne veut pas dire qu'il n'existe pas, il est tout simplement « inconnu ». Ceci est une logique fondamentalement différente de celle utilisée dans un SGBDR comme al MySQL et. - si quelque chose manque, il n'existe pas - hypothèse « Fermé monde ». Prolog et DATALOG sont de bons exemples de Fermer logiques du monde.
Si vous voulez vraiment apprendre ce qui se passe en dessous, vous aurez besoin de regarder ses fondations, qui se trouvent dans la description logique. Un bon aperçu de la description logique se trouve ici: http: // www. inf.unibz.it/~franconi/dl/course/
Si vous voulez en savoir plus sur RDF, consultez le RDF Primer . Sémantique RDF est une autre lecture de rugissante.
Les chercheurs ont essentiellement renoncé à la « sémantique » partie du Web et a décidé de se concentrer sur les données liées sémantique - comment triplets RDF peut naviguer afin que nous puissions perdre plus de bande passante Internet; -)
À l'heure actuelle avec des pages HTML, nous avons des balises balises qui décrivent la façon dont le contenu doit être affiché, <b>, « <pre>, etc. Ces balises impliquent aucune signification sur leur contenu.
Le concept de web sémantique est que les documents contiendraient des balises XML qui ne signifie impliquent sur leur contenu. Par exemple <person><firstname>. La grande idée est que le CSS serait en mesure de formater des documents tels que ceux-ci, mais il serait également possible d'extraire les informations utiles facilement à partir de ces documents.
Le Web sémantique est ce que Tim Berners-Lee, l'inventeur du World Wide Web, le Web avait vraiment l'intention d'être qui est, un graphique global de données liées entre elles. Il est une généralisation d'un graphe social , où vous pouvez utiliser des données sociales (avec vocabulaires comme FOAF ) ainsi que tout autre type de données par les machines et les relier les uns aux autres. Les formats standard pour décrire ce infortmation aux machines est le format (Resource Description RDF ) et le Web Ontology Language ( OWL ). Il y a déjà beaucoup de données codées sur le Web, y compris une version RDF de Wikipédia, appelé DBPedia .
Le Web sémantique sera différente de celle Web d'aujourd'hui en ce que les ordinateurs ainsi que les humains comprendront quels documents contiennent aussi bien que ce que l'importance des liens entre les documents sont. Cela facilitera l'automatisation des tâches de traitement de l'information, y compris la recherche d'informations provenant de sources fiables. La pleine pile de SemWeb comprend la cryptographie, la preuve systèmes et réseaux de confiance.
Tim Berners-Lee il décrit dans son blog Graphique géant mondial (de 2007-11-21):
Trois mouvements mentaux:
- Internet : "Ce ne sont pas les câbles, ce sont les ordinateurs qui sont intéressants"
- ( World Wide ) Web : "Ce ne sont pas les ordinateurs, mais les documents qui sont intéressants"
- géant mondial Graphique : « Ce ne sont pas les documents, ce sont les choses qu'ils sont sur le point qui sont importants »
À propos du terme "géant mondial Graphique":
On peut utiliser le mot graphique, maintenant, à distinguer du Web.
J'ai appelé ce graphique le Web sémantique, mais peut-être qu'il aurait dû être géant mondial graphique! Pire que WWWW? ;-) Pas le terme « Web sémantique » a été mis en place depuis longtemps, je ne propose pas de le changer. Mais nous allons réfléchir sur le graphique qui est. (Note:.. « Graph » se trouve être également le mot les spécifications RDF utilisent, mais qui est par la voie Alors qu'un analyseur XML crée un arbre DOM, un analyseur RDF crée un graphe RDF en mémoire)
Web sémantique est la seule solution pragmatique proposée jusqu'à présent pour réparer des failles inhérentes à la conception de World Wide Web. Parce que les concepteurs de l'Internet, comme nous le savons aujourd'hui, ne fournissaient pas des mécanismes qui répondraient les phénomènes linguistiques fondamentaux qui régissent les humains façon de penser et de communiquer tels que homonymie, synonymie, etc. recherche d'informations sur les résultats de l'Internet dans un flot de faux positifs. L'idée du web sémantique se résume à attribuer des identificateurs sans équivoque aux ressources Web qui aideront à identifier leur sens correctement. Si elle réussit un jour, nous pouvons oublier ce que la recherche habituelle de Google ressemblait, si elle échoue tout restera comme il est maintenant.
Il est un mot buzz pour attirer l'intérêt des gens, Web 2.0 similiar à
i.e.. Dans le futur contenu sera divisé de la présentation permettant de bonté.
En réalité Les faits seront subjective, en fonction du realibility et de l'autorité de l'hôte.
En d'autres termes, les utilisateurs ne verront pas beaucoup de différence à partir de maintenant.
Le Web sémantique est un système d'information distribué où les données liées entre elles sont publiées comme triplets RDF sur HTTP. triplets RDF se composent de sujet, prédicat et objet, mais peuvent avoir d'autres choses qui leur sont rattachés tels que des annotations et des types de données sur la langue naturelle des objets. Sur le Web sémantique, URIs sont utilisés à la fois comme des identifiants et les adresses des ressources du réseau.
Il est différent du Web, parce que le Web est un système d'information distribué des documents et des interfaces d'application.

{kind=link}