Is there anything wrong with this Google App Engine url-fetching code that I have here?
 https://stackoverflow.com/questions/1894279
https://stackoverflow.com/questions/1894279
-
19-09-2019 - |
 italiano
italiano english
english français
français española
española 中国
中国 日本の
日本の العربية
العربية Deutsch
Deutsch 한국어
한국어 Português
Português Russian
RussianQuestion
When I view the source of the page in my browser (FireFox) (View->Page Source), copy it and paste it into my HTML editor, I view almost the same page (In this example it is www.google.com) as it appears in my browser. But when I get the HTML source through this code (through Googles App Engines)
from google.appengine.api import urlfetch
url = "http://www.google.com/"
result = urlfetch.fetch(url)
if result.status_code == 200:
print result.content
copy it and paste it into my HTML editor, the page then looks quite different. Why is it so? Is there something wrong with the code?
++++++++++++++++++++++++++++++
Follow-up:
By this moment (Sunday, December 13th, 2009, 1:01 PM, GMT, to be precise) I have received two comments-questions (from Aaron and Christian P.) and one answer from Alex Martelli.
Both Aaron and Christian P. are asking about what actually is different between the Fire-Fox-obtained source and Google-App-Engine-obtained source when they are both displayed through the same HTML editor.
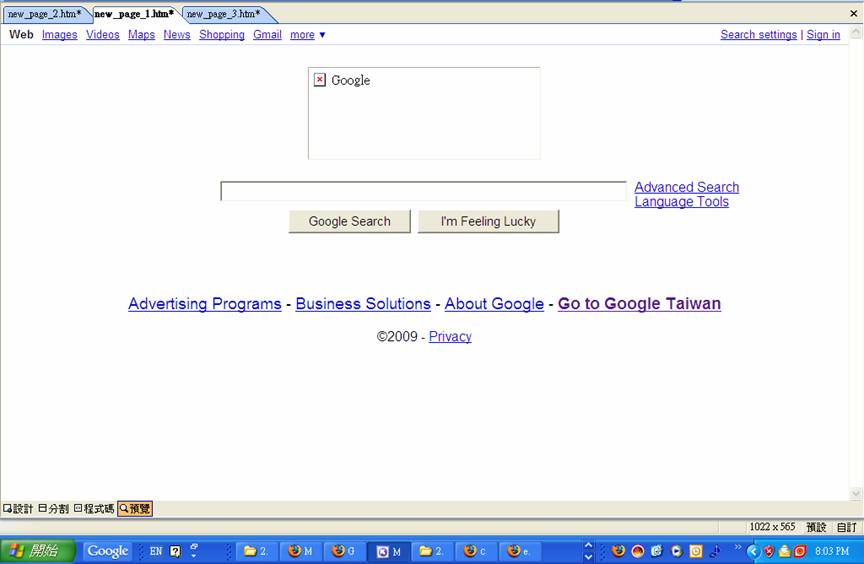
Here I have uploaded too screen shots:
One shows the Fire-Fox-obtained source
And the other one shows Google-App-Engine-obtained source
when they are both displayed through “MS Front Page” editor.
One difference, which is quite obvious, is different encoding: In Fire-Fox code everything is displayed in English, while in the Google-App-Engine code I get a lot of various symbols, instead.
Another difference is some additional lines at the top of the page in the Google App Engine code. I think, this is what Alex Martelli was talking about in his answer (“…the fetch-and-print approach is going to have metadata around it as well…”).
One more minor difference is that the box for the Google image is split into several boxes in one code, while it remains whole in the other one.
Alex Martelli suggested that I use this code (if I understood him correctly):
from google.appengine.api import urlfetch
url = "http://www.google.com/"
result = urlfetch.fetch(url)
if result.status_code == 200:
print "content-type: text/plain"
print
I’ve tried it, but in this case nothing is displayed at all.
Thank you all for your responses and, please, continue responding – I really want to see this issue finally resolved.
++++++++++++++++++++++++++++++
Follow-up:
Okay, the issue has been resolved.
I failed to pay my full attention to Alex Martelli's instructions and, therefore, came up with a wrong code. Here is he right one:
from google.appengine.api import urlfetch
url = "http://www.google.com/"
result = urlfetch.fetch(url)
if result.status_code == 200:
print "content-type: text/plain"
print
print result.content
This code displays exactly what is needed - no additional lines at the top of the page.
Well, I still get the strange symbols, but I discovered that it's probably Google's problem. The thing is I am currently in Taiwan, and Google seems to be aware of that and automatically switches from www.google.com (which is in English) to www.google.com.tw (which is in Chinese), but this one, I guess, is already another topic.
Thanks to everyone who has responded here.
Solution
You have not explicitly emitted a "content type" header, and an end-of-headers empty line, so the first few lines are probably going to be lost; try adding before the final print something like
print "content-type: text/plain"
print
Beyond this, what you're getting in either case is essentially a big <script> with a little extra HTML around it -- that's all that Firefox is going to give you in the "view source" page, while the fetch-and-print approach is going to have metadata around it as well, e.g., the "doctype" (depending on what HTML editor you're targeting, this may or may not be an issue).

{kind=link}
{kind=link}