C'è qualcosa di sbagliato in questo Codice motore url-fetching Google App che ho qui?
 https://stackoverflow.com/questions/1894279
https://stackoverflow.com/questions/1894279
-
19-09-2019 - |
 italiano
italiano english
english français
français española
española 中国
中国 日本の
日本の العربية
العربية Deutsch
Deutsch 한국어
한국어 Português
Português Russian
RussianDomanda
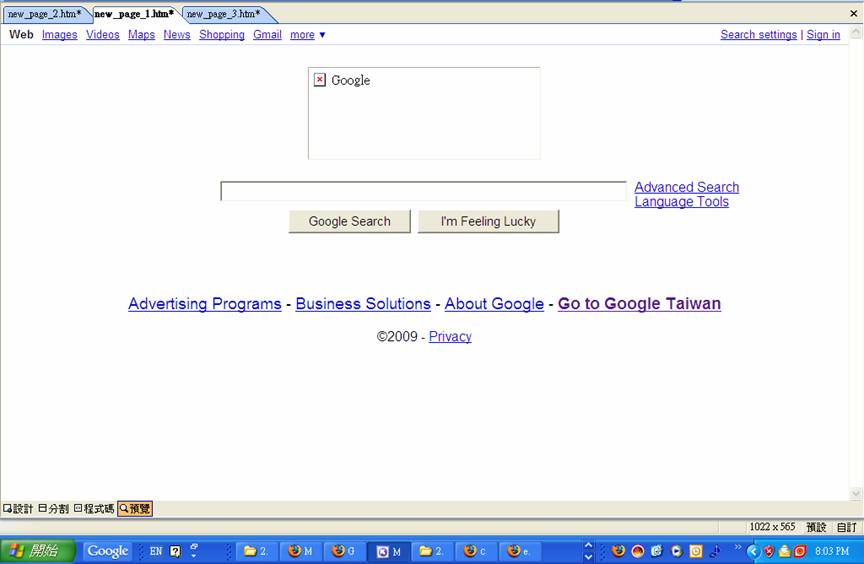
Quando osservo la fonte della pagina nel browser (FireFox) (Visualizza-> Sorgente pagina), copiarlo e incollarlo nel mio editor HTML, ho vista quasi la stessa pagina (in questo esempio è www.google .com) come appare nel mio browser. Ma quando ho la sorgente HTML tramite questo codice (attraverso i motori di Googles App)
from google.appengine.api import urlfetch
url = "http://www.google.com/"
result = urlfetch.fetch(url)
if result.status_code == 200:
print result.content
copiarlo e incollarlo nel mio editor HTML, la pagina sembra poi molto diverso. Perché è così? C'è qualcosa di sbagliato con il codice?
++++++++++++++++++++++++++++++
Follow-up:
Con questo momento (Domenica, 13 dicembre 2009, 01:01, GMT, per essere precisi) Ho ricevuto due commenti-domande (da Aaron e Christian P. ) e una risposta da Alex Martelli .
Entrambi Aaron e Christian P. si chiedono su ciò che in realtà è diverso tra la fonte Fuoco-Fox-ottenuto e la fonte di Google-App-motore-ottiene quando sono sia visualizzata attraverso lo stesso editor HTML.
Qui ho caricato troppo colpi di schermo:
una mostra la fonte Fuoco-Fox-ottenuto
l'altra mostra fonte Google-App-motore-ottenuto
quando sono entrambe visualizzate attraverso “MS Front Page” editore.
Una differenza, che è abbastanza ovvio, è la codifica diversa:. Nel codice di Fuoco-Fox tutto viene visualizzato in inglese, mentre nel codice di Google-App-Engine ho un sacco di vari simboli, anziché
Un'altra differenza è alcune linee aggiuntive nella parte superiore della pagina nel codice Google App Engine. Penso, questo è ciò che Alex Martelli di cui parlava nella sua risposta ( “... l'approccio fetch-and-print sta per avere metadati intorno esso pure ...”).
Ancora una piccola differenza è che la casella per l'immagine di Google è suddivisa in diverse scatole in un codice, mentre resta tutta nell'altro.
Alex Martelli ha suggerito che io uso questo codice (se lo ho capito bene):
from google.appengine.api import urlfetch
url = "http://www.google.com/"
result = urlfetch.fetch(url)
if result.status_code == 200:
print "content-type: text/plain"
print
Lo ho provato, ma in questo caso non viene visualizzato nulla a tutti.
Grazie a tutti per le vostre risposte e, per favore, continuare a rispondere - Voglio davvero vedere questo problema finalmente risolto
.++++++++++++++++++++++++++++++
Follow-up:
D'accordo, il problema è stato risolto.
non sono riuscito a pagare la mia piena attenzione alla Alex Martelli s 'istruzioni e, di conseguenza, si avvicinò con un codice errato. Ecco che giusta:
from google.appengine.api import urlfetch
url = "http://www.google.com/"
result = urlfetch.fetch(url)
if result.status_code == 200:
print "content-type: text/plain"
print
print result.content
Questo codice visualizza esattamente ciò che è necessario - senza linee aggiuntive nella parte superiore della pagina
.Beh, ho ancora gli strani simboli, ma ho scoperto che è probabilmente il problema di Google. Il fatto è che io sono attualmente a Taiwan, e Google sembra essere consapevoli di questo e passa automaticamente da www.google.com (che è in inglese) per www.google.com.tw (che è in cinese), ma questo , immagino, è già un altro argomento.
Grazie a tutti coloro che hanno risposto qui.
Soluzione
Non hai emesso esplicitamente un "tipo di contenuto" intestazione e una riga vuota end-of-header, in modo che le prime righe sono probabilmente da perdere; provare ad aggiungere qualcosa prima della print finale come
print "content-type: text/plain"
print
Al di là di questo, quello che stai ricevendo in entrambi i casi è essenzialmente un grande <script> con un po 'di HTML in più intorno ad esso - che è tutto ciò che Firefox sta per darvi nella pagina "visualizza sorgente", mentre il fetch-e approccio -print sta per avere metadati intorno esso pure, ad esempio, il "DOCTYPE" (a seconda di ciò editor HTML sei targeting, questo può o non può essere un problema).

{kind=link}
{kind=link}