How to: pow(real, real) in x86
 https://stackoverflow.com/questions/4638473
https://stackoverflow.com/questions/4638473
 italiano
italiano english
english français
français española
española 中国
中国 日本の
日本の العربية
العربية Deutsch
Deutsch 한국어
한국어 Português
Português Russian
RussianQuestion
I'm looking for the implementation of pow(real, real) in x86 Assembly. Also I'd like to understand how the algorithm works.
Solution
Just compute it as 2^(y*log2(x)).
There is a x86 instruction FYL2X to compute y*log2(x) and a x86 instruction F2XM1 to do exponentiation. F2XM1 requires an argument in [-1,1] range, so you'd have to add some code in between to extract the integer part and the remainder, exponentiate the remainder, use FSCALE to scale the result by an appropriate power of 2.
OTHER TIPS
OK, I implemented power(double a, double b, double * result); in x86 just as you recommended.
Code: http://pastebin.com/VWfE9CZT
%define a QWORD [ebp+8]
%define b QWORD [ebp+16]
%define result DWORD [ebp+24]
%define ctrlWord WORD [ebp-2]
%define tmp DWORD [ebp-6]
segment .text
global power
power:
push ebp
mov ebp, esp
sub esp, 6
push ebx
fstcw ctrlWord
or ctrlWord, 110000000000b
fldcw ctrlWord
fld b
fld a
fyl2x
fist tmp
fild tmp
fsub
f2xm1
fld1
fadd
fild tmp
fxch
fscale
mov ebx, result
fst QWORD [ebx]
pop ebx
mov esp, ebp
pop ebp
ret
Here's my function using the main algorithm by 'The Svin'. I wrapped it in __fastcall & __declspec(naked) decorations, and added the code to make sure the base/x is positive. If x is negative, the FPU will totally fail. You need to check the 'x' sign bit, plus consider odd/even bit of 'y', and apply the sign after it's finished! Lemme know what you think to any random reader. Looking for even better versions with x87 FPU code if possible. It compiles/works with Microsoft VC++ 2005 what I always stick with for various reasons.
Compatibility v. ANSI pow(x,y): Very good! Faster, predictable results, negative values are handled, just no error feedback for invalid input. But, if you know 'y' can always be an INT/LONG, do NOT use this version; I posted Agner Fog's version with some tweaks which avoids the very slow FSCALE, search my profile for it! His is the fastest x87/FPU way under those limited circumstances!
extern double __fastcall fs_Power(double x, double y);
// Main Source: The Svin
// pow(x,y) is equivalent to exp(y * ln(x))
// Version: 1.00
__declspec(naked) double __fastcall fs_Power(double x, double y) { __asm {
LEA EAX, [ESP+12] ;// Save 'y' index in EAX
FLD QWORD PTR [EAX] ;// Load 'y' (exponent) (works positive OR negative!)
FIST DWORD PTR [EAX] ;// Round 'y' back to INT form to test for odd/even bit
MOVZX EAX, WORD PTR [EAX-1] ;// Get x's left sign bit AND y's right odd/even bit!
FLD QWORD PTR [ESP+4] ;// Load 'x' (base) (make positive next!)
FABS ;// 'x' MUST be positive, BUT check sign/odd bits pre-exit!
AND AX, 0180h ;// AND off all bits except right 'y' odd bit AND left 'x' sign bit!
FYL2X ;// 'y' * log2 'x' - (ST(0) = ST(1) * log2 ST(0)), pop
FLD1 ;// Load 1.0f: 2 uses, mantissa extract, add 1.0 back post-F2XM1
FLD ST(1) ;// Duplicate current result
FPREM1 ;// Extract mantissa via partial ST0/ST1 remainder with 80387+ IEEE cmd
F2XM1 ;// Compute (2 ^ ST(0) - 1)
FADDP ST(1), ST ;// ADD 1.0f back! We want (2 ^ X), NOT (2 ^ X - 1)!
FSCALE ;// ST(0) = ST(0) * 2 ^ ST(1) (Scale by factor of 2)
FFREE ST(1) ;// Maintain FPU stack balance
;// Final task, make result negative if needed!
CMP AX, 0180h ;// Combo-test: Is 'y' odd bit AND 'x' sign bit set?
JNE EXIT_RETURN ;// If positive, exit; if not, add '-' sign!
FCHS ;// 'x' is negative, 'y' is ~odd, final result = negative! :)
EXIT_RETURN:
;// For __fastcall/__declspec(naked), gotta clean stack here (2 x 8-byte doubles)!
RET 16 ;// Return & pop 16 bytes off stack
}}
Alright, to wrap this experiment up, I ran a benchmark test using the RDTSC CPU time stamp/clocks counter instruction. I followed the advice of also setting the process to High priority with "SetPriorityClass(GetCurrentProcess(), HIGH_PRIORITY_CLASS);" and I closed out all other apps.
Results: Our retro x87 FPU Math function "fs_Power(x,y)" is 50-60% faster than the MSCRT2005 pow(x,y) version which uses a pretty long SSE branch of code labeled '_pow_pentium4:' if it detects a 64-bit >Pentium4+ CPU. So yaaaaay!! :-)
Notes: (1) The CRT pow() has a ~33 microsecond initialization branch it appears which shows us 46,000 in this test. It operates at a normal average after that of 1200 to 3000 cycles. Our hand-crafted x87 FPU beauty runs consistent, no init penalty on the first call!
(2) While CRT pow() lost every test, it DID win in ONE area: If you entered wild, huge, out-of-range/overflow values, it quickly returned an error. Since most apps don't need error checks for typical/normal use, it's irrelevant.
https://i.postimg.cc/QNbB7ZVz/FPUv-SSEMath-Power-Proc-Test.png
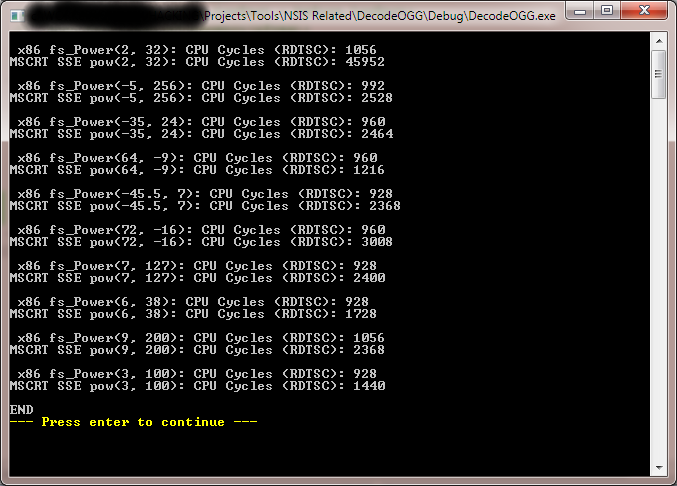
2nd Test (I had to run it again to copy/paste text after the image snap):
x86 fs_Power(2, 32): CPU Cycles (RDTSC): 1248
MSCRT SSE pow(2, 32): CPU Cycles (RDTSC): 50112
x86 fs_Power(-5, 256): CPU Cycles (RDTSC): 1120
MSCRT SSE pow(-5, 256): CPU Cycles (RDTSC): 2560
x86 fs_Power(-35, 24): CPU Cycles (RDTSC): 1120
MSCRT SSE pow(-35, 24): CPU Cycles (RDTSC): 2528
x86 fs_Power(64, -9): CPU Cycles (RDTSC): 1120
MSCRT SSE pow(64, -9): CPU Cycles (RDTSC): 1280
x86 fs_Power(-45.5, 7): CPU Cycles (RDTSC): 1312
MSCRT SSE pow(-45.5, 7): CPU Cycles (RDTSC): 1632
x86 fs_Power(72, -16): CPU Cycles (RDTSC): 1120
MSCRT SSE pow(72, -16): CPU Cycles (RDTSC): 1632
x86 fs_Power(7, 127): CPU Cycles (RDTSC): 1056
MSCRT SSE pow(7, 127): CPU Cycles (RDTSC): 2016
x86 fs_Power(6, 38): CPU Cycles (RDTSC): 1024
MSCRT SSE pow(6, 38): CPU Cycles (RDTSC): 2048
x86 fs_Power(9, 200): CPU Cycles (RDTSC): 1152
MSCRT SSE pow(9, 200): CPU Cycles (RDTSC): 7168
x86 fs_Power(3, 100): CPU Cycles (RDTSC): 1984
MSCRT SSE pow(3, 100): CPU Cycles (RDTSC): 2784
Any real world applications? YES! Pow(x,y) is used heavily to help encode/decode a CD's WAVE format to OGG and vice versa! When you're encoding a full 60 minutes of WAVE data, that's where the time-saving payoff would be significant! Many Math functions are used in OGG/libvorbis also like acos(), cos(), sin(), atan(), sqrt(), ldexp() (very important), etc. So fine-tuned versions like this, which don't bother/need error checks, can save lots of time!!
My experiment is the result of building an OGG decoder for the NSIS installer system which led to me replacing all the Math "C" library functions the algorithm needs with what you see above. Well, ALMOST, I need acos() in x86, but I STILL can't find anything for that...
Regards, and hope this is useful to anyone else that likes to tinker!

{kind=link}