方法:x86のパウ(リアル、リアル)
 https://stackoverflow.com/questions/4638473
https://stackoverflow.com/questions/4638473
 italiano
italiano english
english français
français española
española 中国
中国 日本の
日本の العربية
العربية Deutsch
Deutsch 한국어
한국어 Português
Português Russian
Russian質問
の実装を探しています pow(real, real) X86アセンブリ。また、アルゴリズムがどのように機能するかを理解したいと思います。
解決
そのように計算してください 2^(y*log2(x)).
y*log2(x)を計算するx86命令fyl2xとx86命令f2xm1が発表されます。 F2XM1には[-1,1]範囲の引数が必要なため、整数部品と残りを抽出し、残りを指数化し、FSCALEを使用して適切なパワー2で拡大するコードを追加する必要があります。
他のヒント
わかりました、実装しました power(double a, double b, double * result); あなたが推奨したようにx86で。
コード: http://pastebin.com/vwfe9czt
%define a QWORD [ebp+8]
%define b QWORD [ebp+16]
%define result DWORD [ebp+24]
%define ctrlWord WORD [ebp-2]
%define tmp DWORD [ebp-6]
segment .text
global power
power:
push ebp
mov ebp, esp
sub esp, 6
push ebx
fstcw ctrlWord
or ctrlWord, 110000000000b
fldcw ctrlWord
fld b
fld a
fyl2x
fist tmp
fild tmp
fsub
f2xm1
fld1
fadd
fild tmp
fxch
fscale
mov ebx, result
fst QWORD [ebx]
pop ebx
mov esp, ebp
pop ebp
ret
「The Svin」によるメインアルゴリズムを使用した私の関数は次のとおりです。 __fastcall&__declspec(裸)装飾にラップし、ベース/xが正であることを確認するためにコードを追加しました。 Xが負の場合、FPUは完全に失敗します。 「X」サインビットを確認する必要があります。さらに、「Y」の奇数/ビットを検討し、終了後にサインを適用する必要があります。 Lemmeは、ランダムな読者にあなたがどう思うかを知っています。可能であれば、x87 FPUコードを備えたさらに良いバージョンを探しています。 Microsoft VC ++ 2005で編集/動作します。
互換性v。AnsiPow(X、Y):とても良い!より速く、予測可能な結果、負の値が処理され、無効な入力のエラーフィードバックはありません。ただし、「Y」が常にint/longであることがわかっている場合は、このバージョンを使用しないでください。 Agner Fogのバージョンをいくつかの微調整で投稿しました。彼は限られた状況下で最も速いX87/FPUの方法です!
extern double __fastcall fs_Power(double x, double y);
// Main Source: The Svin
// pow(x,y) is equivalent to exp(y * ln(x))
// Version: 1.00
__declspec(naked) double __fastcall fs_Power(double x, double y) { __asm {
LEA EAX, [ESP+12] ;// Save 'y' index in EAX
FLD QWORD PTR [EAX] ;// Load 'y' (exponent) (works positive OR negative!)
FIST DWORD PTR [EAX] ;// Round 'y' back to INT form to test for odd/even bit
MOVZX EAX, WORD PTR [EAX-1] ;// Get x's left sign bit AND y's right odd/even bit!
FLD QWORD PTR [ESP+4] ;// Load 'x' (base) (make positive next!)
FABS ;// 'x' MUST be positive, BUT check sign/odd bits pre-exit!
AND AX, 0180h ;// AND off all bits except right 'y' odd bit AND left 'x' sign bit!
FYL2X ;// 'y' * log2 'x' - (ST(0) = ST(1) * log2 ST(0)), pop
FLD1 ;// Load 1.0f: 2 uses, mantissa extract, add 1.0 back post-F2XM1
FLD ST(1) ;// Duplicate current result
FPREM1 ;// Extract mantissa via partial ST0/ST1 remainder with 80387+ IEEE cmd
F2XM1 ;// Compute (2 ^ ST(0) - 1)
FADDP ST(1), ST ;// ADD 1.0f back! We want (2 ^ X), NOT (2 ^ X - 1)!
FSCALE ;// ST(0) = ST(0) * 2 ^ ST(1) (Scale by factor of 2)
FFREE ST(1) ;// Maintain FPU stack balance
;// Final task, make result negative if needed!
CMP AX, 0180h ;// Combo-test: Is 'y' odd bit AND 'x' sign bit set?
JNE EXIT_RETURN ;// If positive, exit; if not, add '-' sign!
FCHS ;// 'x' is negative, 'y' is ~odd, final result = negative! :)
EXIT_RETURN:
;// For __fastcall/__declspec(naked), gotta clean stack here (2 x 8-byte doubles)!
RET 16 ;// Return & pop 16 bytes off stack
}}
さて、この実験をまとめるために、RDTSC CPUタイムスタンプ/時計カウンター命令を使用してベンチマークテストを実行しました。また、「setPriorityClass(getCurrentProcess()、high_priority_class);」でプロセスを優先度を高めるというアドバイスに従いました。そして、私は他のすべてのアプリを閉じました。
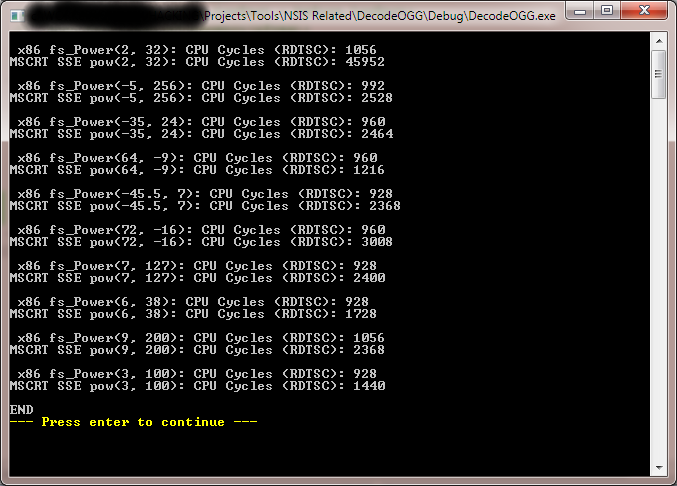
結果:レトロX87 FPU数学機能「FS_POWER(X、Y)」は、 '_pow_pentium4:'というラベルの付いたコードのかなり長いSSEブランチを使用するMSCRT2005 POW(X、Y)バージョンよりも50-60%高速です。 64ビット> Pentium4+ CPU。だからyaaaaay !! :-)
注:(1)CRT POW()には、このテストで46,000を示しているように表示される〜33マイクロ秒の初期化ブランチがあります。 1200〜3000サイクルの後の通常の平均で動作します。手作りのX87 FPU Beautyは一貫性があり、最初の呼び出しでは初期的なペナルティはありません!
(2)CRT POW()はすべてのテストを失いましたが、1つの領域で勝ちました。ほとんどのアプリは、典型的/通常の使用のためにエラーチェックを必要としないため、それは無関係です。
https://i.postimg.cc/qnbb7zvz/fpuv-semath-power-proc-test.png
2回目のテスト(画像スナップ後にテキストをコピー/貼り付けるために再度実行する必要がありました):
x86 fs_Power(2, 32): CPU Cycles (RDTSC): 1248
MSCRT SSE pow(2, 32): CPU Cycles (RDTSC): 50112
x86 fs_Power(-5, 256): CPU Cycles (RDTSC): 1120
MSCRT SSE pow(-5, 256): CPU Cycles (RDTSC): 2560
x86 fs_Power(-35, 24): CPU Cycles (RDTSC): 1120
MSCRT SSE pow(-35, 24): CPU Cycles (RDTSC): 2528
x86 fs_Power(64, -9): CPU Cycles (RDTSC): 1120
MSCRT SSE pow(64, -9): CPU Cycles (RDTSC): 1280
x86 fs_Power(-45.5, 7): CPU Cycles (RDTSC): 1312
MSCRT SSE pow(-45.5, 7): CPU Cycles (RDTSC): 1632
x86 fs_Power(72, -16): CPU Cycles (RDTSC): 1120
MSCRT SSE pow(72, -16): CPU Cycles (RDTSC): 1632
x86 fs_Power(7, 127): CPU Cycles (RDTSC): 1056
MSCRT SSE pow(7, 127): CPU Cycles (RDTSC): 2016
x86 fs_Power(6, 38): CPU Cycles (RDTSC): 1024
MSCRT SSE pow(6, 38): CPU Cycles (RDTSC): 2048
x86 fs_Power(9, 200): CPU Cycles (RDTSC): 1152
MSCRT SSE pow(9, 200): CPU Cycles (RDTSC): 7168
x86 fs_Power(3, 100): CPU Cycles (RDTSC): 1984
MSCRT SSE pow(3, 100): CPU Cycles (RDTSC): 2784
現実世界のアプリケーションはありますか?はい! POW(X、Y)は、CDの波形式をOGGにエンコード/デコードし、その逆に重く使用しています。 60分間の波のデータをエンコードすると、時間を節約するペイオフが重要になります!多くの数学関数は、ogg/libvorbisでacos()、cos()、sin()、atan()、sqrt()、ldexp()(非常に重要)などのように使用されています。エラーチェックを気にしない/必要はありません、多くの時間を節約できます!!
私の実験は、NSISインストーラーシステム用のOGGデコーダーを構築した結果です。これにより、アルゴリズムが必要とするすべての数学「C」ライブラリが上記のものをすべて交換しました。まあ、ほとんど、私はx86でacos()が必要ですが、それでも何も見つかりません...
よろしく、これがいじくり回すのが好きな他の人に役立つことを願っています!

{kind=link}