Condicionalmente color de puntos de datos fuera de bandas de confianza en R
 https://stackoverflow.com/questions/2687212
https://stackoverflow.com/questions/2687212
-
30-09-2019 - |
 italiano
italiano english
english français
français española
española 中国
中国 日本の
日本の العربية
العربية Deutsch
Deutsch 한국어
한국어 Português
Português Russian
RussianPregunta
necesito puntos de datos de color que están fuera de las bandas de la confianza en el terreno por debajo de forma diferente a los dentro de las bandas. ¿Debo agregar una columna separada a mi conjunto de datos para registrar si los puntos de datos se encuentran dentro de las bandas de confianza? ¿Puede dar un ejemplo por favor?
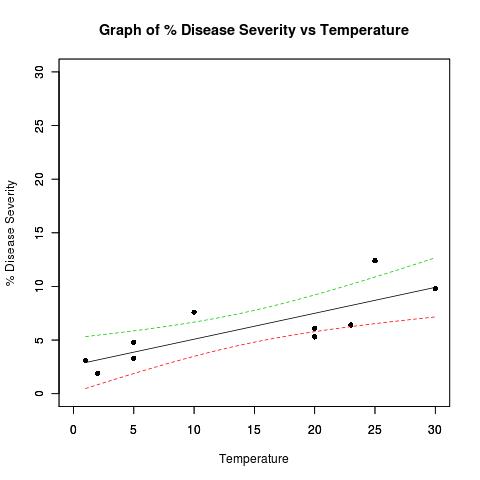
Ejemplo conjunto de datos:
## Dataset from http://www.apsnet.org/education/advancedplantpath/topics/RModules/doc1/04_Linear_regression.html
## Disease severity as a function of temperature
# Response variable, disease severity
diseasesev<-c(1.9,3.1,3.3,4.8,5.3,6.1,6.4,7.6,9.8,12.4)
# Predictor variable, (Centigrade)
temperature<-c(2,1,5,5,20,20,23,10,30,25)
## For convenience, the data may be formatted into a dataframe
severity <- as.data.frame(cbind(diseasesev,temperature))
## Fit a linear model for the data and summarize the output from function lm()
severity.lm <- lm(diseasesev~temperature,data=severity)
# Take a look at the data
plot(
diseasesev~temperature,
data=severity,
xlab="Temperature",
ylab="% Disease Severity",
pch=16,
pty="s",
xlim=c(0,30),
ylim=c(0,30)
)
title(main="Graph of % Disease Severity vs Temperature")
par(new=TRUE) # don't start a new plot
## Get datapoints predicted by best fit line and confidence bands
## at every 0.01 interval
xRange=data.frame(temperature=seq(min(temperature),max(temperature),0.01))
pred4plot <- predict(
lm(diseasesev~temperature),
xRange,
level=0.95,
interval="confidence"
)
## Plot lines derrived from best fit line and confidence band datapoints
matplot(
xRange,
pred4plot,
lty=c(1,2,2), #vector of line types and widths
type="l", #type of plot for each column of y
xlim=c(0,30),
ylim=c(0,30),
xlab="",
ylab=""
)
Solución
La forma más sencilla es probablemente para calcular un vector de valores TRUE/FALSE que indican si un punto de datos se encuentra dentro del intervalo de confianza o no. Voy a volver a barajar tu ejemplo un poco para que todos los cálculos se han completado antes de que los comandos de trazado son executed- esto proporciona una separación limpia de la lógica del programa que podría ser aprovechada si se va a empaquetar algo de esto en una función .
La primera parte es más o menos la misma, excepto que sustituye la llamada adicional a lm() dentro predict() con el severity.lm variable que no hay necesidad de utilizar los recursos informáticos adicionales para volver a calcular el modelo lineal cuando ya lo tenemos almacenado:
## Dataset from
# apsnet.org/education/advancedplantpath/topics/
# RModules/doc1/04_Linear_regression.html
## Disease severity as a function of temperature
# Response variable, disease severity
diseasesev<-c(1.9,3.1,3.3,4.8,5.3,6.1,6.4,7.6,9.8,12.4)
# Predictor variable, (Centigrade)
temperature<-c(2,1,5,5,20,20,23,10,30,25)
## For convenience, the data may be formatted into a dataframe
severity <- as.data.frame(cbind(diseasesev,temperature))
## Fit a linear model for the data and summarize the output from function lm()
severity.lm <- lm(diseasesev~temperature,data=severity)
## Get datapoints predicted by best fit line and confidence bands
## at every 0.01 interval
xRange=data.frame(temperature=seq(min(temperature),max(temperature),0.01))
pred4plot <- predict(
severity.lm,
xRange,
level=0.95,
interval="confidence"
)
Ahora, vamos a calcular los intervalos de confianza para los puntos de datos original ya realizar una prueba para ver si los puntos están dentro del intervalo:
modelConfInt <- predict(
severity.lm,
level = 0.95,
interval = "confidence"
)
insideInterval <- modelConfInt[,'lwr'] < severity[['diseasesev']] &
severity[['diseasesev']] < modelConfInt[,'upr']
A continuación, vamos a hacer la trama- primero al plot() función de alto nivel de trazado, como se lo utilizó en su ejemplo, pero sólo a trazar los puntos dentro del intervalo. a continuación, vamos a seguir con la points() función de bajo nivel que permita trazar todos los puntos fuera del intervalo en un color diferente. Por último, matplot() será utilizada para llenar los intervalos de confianza como lo hacía él. Sin embargo en lugar de llamar par(new=TRUE) prefiero pasar el add=TRUE argumento para funciones de alto nivel para que sean actúan como funciones de bajo nivel.
El uso de par(new=TRUE) es como jugar un truco sucio Función- un trazado que puede tener consecuencias imprevistas. El argumento add es proporcionada por muchas funciones para hacer que les permite añadir información a una parcela en lugar de volver a dibujar IT recomendaría la explotación de este argumento siempre que sea posible y caer de nuevo manipulaciones par() como último recurso.
# Take a look at the data- those points inside the interval
plot(
diseasesev~temperature,
data=severity[ insideInterval,],
xlab="Temperature",
ylab="% Disease Severity",
pch=16,
pty="s",
xlim=c(0,30),
ylim=c(0,30)
)
title(main="Graph of % Disease Severity vs Temperature")
# Add points outside the interval, color differently
points(
diseasesev~temperature,
pch = 16,
col = 'red',
data = severity[ !insideInterval,]
)
# Add regression line and confidence intervals
matplot(
xRange,
pred4plot,
lty=c(1,2,2), #vector of line types and widths
type="l", #type of plot for each column of y
add = TRUE
)
Otros consejos
Bueno, pensé que esto sería bastante fácil con ggplot2, pero ahora me doy cuenta que no tengo ni idea de cómo / geom_smooth se calculan los límites de confianza para stat_smooth.
Tenga en cuenta lo siguiente:
library(ggplot2)
pred <- as.data.frame(predict(severity.lm,level=0.95,interval="confidence"))
dat <- data.frame(diseasesev,temperature,
in_interval = diseasesev <=pred$upr & diseasesev >=pred$lwr ,pred)
ggplot(dat,aes(y=diseasesev,x=temperature)) +
stat_smooth(method='lm') + geom_point(aes(colour=in_interval)) +
geom_line(aes(y=lwr),colour=I('red')) + geom_line(aes(y=upr),colour=I('red'))
Esto produce: texto alternativo http://ifellows.ucsd.edu/pmwiki/uploads/Main/strangeplot.jpg
I no entiendo por qué la banda de confianza calculado por stat_smooth es incompatible con la banda calculada directamente de predecir (es decir, las líneas rojas). ¿Alguien puede arrojar algo de luz sobre esto?
Editar:
lo descubrió. ggplot2 utiliza 1,96 * error estándar para dibujar los intervalos para todos los métodos de suavizado.
pred <- as.data.frame(predict(severity.lm,se.fit=TRUE,
level=0.95,interval="confidence"))
dat <- data.frame(diseasesev,temperature,
in_interval = diseasesev <=pred$fit.upr & diseasesev >=pred$fit.lwr ,pred)
ggplot(dat,aes(y=diseasesev,x=temperature)) +
stat_smooth(method='lm') +
geom_point(aes(colour=in_interval)) +
geom_line(aes(y=fit.lwr),colour=I('red')) +
geom_line(aes(y=fit.upr),colour=I('red')) +
geom_line(aes(y=fit.fit-1.96*se.fit),colour=I('green')) +
geom_line(aes(y=fit.fit+1.96*se.fit),colour=I('green'))
Me gustó la idea y trató de hacer una función para eso. Por supuesto que es lejos de ser perfecto. Sus comentarios son bienvenidos
diseasesev<-c(1.9,3.1,3.3,4.8,5.3,6.1,6.4,7.6,9.8,12.4)
# Predictor variable, (Centigrade)
temperature<-c(2,1,5,5,20,20,23,10,30,25)
## For convenience, the data may be formatted into a dataframe
severity <- as.data.frame(cbind(diseasesev,temperature))
## Fit a linear model for the data and summarize the output from function lm()
severity.lm <- lm(diseasesev~temperature,data=severity)
# Function to plot the linear regression and overlay the confidence intervals
ci.lines<-function(model,conf= .95 ,interval = "confidence"){
x <- model[[12]][[2]]
y <- model[[12]][[1]]
xm<-mean(x)
n<-length(x)
ssx<- sum((x - mean(x))^2)
s.t<- qt(1-(1-conf)/2,(n-2))
xv<-seq(min(x),max(x),(max(x) - min(x))/100)
yv<- coef(model)[1]+coef(model)[2]*xv
se <- switch(interval,
confidence = summary(model)[[6]] * sqrt(1/n+(xv-xm)^2/ssx),
prediction = summary(model)[[6]] * sqrt(1+1/n+(xv-xm)^2/ssx)
)
# summary(model)[[6]] = 'sigma'
ci<-s.t*se
uyv<-yv+ci
lyv<-yv-ci
limits1 <- min(c(x,y))
limits2 <- max(c(x,y))
predictions <- predict(model, level = conf, interval = interval)
insideCI <- predictions[,'lwr'] < y & y < predictions[,'upr']
x_name <- rownames(attr(model[[11]],"factors"))[2]
y_name <- rownames(attr(model[[11]],"factors"))[1]
plot(x[insideCI],y[insideCI],
pch=16,pty="s",xlim=c(limits1,limits2),ylim=c(limits1,limits2),
xlab=x_name,
ylab=y_name,
main=paste("Graph of ", y_name, " vs ", x_name,sep=""))
abline(model)
points(x[!insideCI],y[!insideCI], pch = 16, col = 'red')
lines(xv,uyv,lty=2,col=3)
lines(xv,lyv,lty=2,col=3)
}
El uso de esta manera:
ci.lines(severity.lm, conf= .95 , interval = "confidence")
ci.lines(severity.lm, conf= .85 , interval = "prediction")

{kind=link}