Gravity Trier: Est-ce possible programme? [fermé]
 https://stackoverflow.com/questions/2489190
https://stackoverflow.com/questions/2489190
-
21-09-2019 - |
 italiano
italiano english
english français
français española
española 中国
中国 日本の
日本の العربية
العربية Deutsch
Deutsch 한국어
한국어 Português
Português Russian
RussianQuestion
J'ai pensé récemment sur l'utilisation de la conception orientée objet dans l'algorithme de tri. Cependant je ne suis pas en mesure de trouver une bonne façon de vous rapprocher encore plus à faire cet algorithme de tri qui fait le tri dans O (n).
Ok, voici ce que j'ai pensé pendant une semaine. J'ai un ensemble de données d'entrée. Je vais assigner une masse à chacune des données d'entrée (en supposant des données d'entrée d'un type de Mass et un type de Sphere. Si nous supposons que tous les objets à des objets parfaitement sphériques avec des formes proportionnelles à leur masse, le plus lourd touche le sol en premier. ). Je vais mettre toutes mes données d'entrée dans l'espace tout à la même distance de la terre. Et je les ferai chute libre. Selon la loi de gravitation, le plus lourd touche le sol en premier. Et l'ordre dans lequel ils ont frappé me donnera les données triées. Ce drôle est d'une certaine façon, mais en dessous je pense que cela devrait être possible en utilisant l'OO que j'ai appris jusqu'à ce jour
Est-il vraiment possible de faire une technique de tri qui utilise la force gravitationnelle comme scénario ou suis-je stupide / fou?
Edit:. Transforme tous les objets touchent le sol en même temps où j'introduit le concept d'objet sphérique
La solution
La chose est, si l'un des idées de la POO peuvent être à modéliser le monde réel, cela ne signifie pas qu'il y ait une correspondance directe entre combien de temps quelque chose prend dans le monde réel et combien de temps il faudrait simuler avec un ordinateur.
Imaginez les étapes réelles nécessaires à votre procédure:
- Un objet doit être construit pour chaque élément de votre ensemble de données. Sur la plupart du matériel moderne, cela ne nécessiterait itération et serait donc votre stratégie O (n) meilleurs .
- L'effet de la gravité devrait être simulé, pour chaque objet. Encore une fois, la façon la plus évidente, simple à mettre en œuvre ce serait itérer.
- Le temps que chaque terres d'objet sur la surface de la « Terre » dans votre modèle de programmation devraient être capturés et, par l'intermédiaire d'un mécanisme spécifique à la mise en œuvre, l'objet correspondant devrait être inséré dans une liste ordonnée par suite .
Considérant le problème introduit des complications supplémentaires plus. Demandez-vous ceci: à quelle hauteur avez-vous besoin de placer ces objets pour commencer? De toute évidence suffisamment élevée pour que le plus grand en fait tombe ; à savoir, plus loin de la Terre que le rayon du plus grand objet. Mais comment savez-vous à quel point c'est? Vous aurez besoin de déterminer d'abord le plus grand objet de la collection; ce, encore une fois, serait (probablement) exiger itérer. En outre, on pourrait imaginer que cette simulation pourrait être multithread pour tenter de simuler le comportement en temps réel de la notion d'objets en fait tomber; mais vous vous trouverez en essayant d'ajouter des éléments à une collection (une opération qui prend évidemment une quantité non nulle de temps) potentiellement en même temps que de nouvelles collisions sont détectées. Donc, cela va créer des problèmes threading ainsi.
En bref, j'ai du mal à imaginer comment cette idée pourrait être correctement mis en œuvre simplement en utilisant OOP sans matériel spécial. Cela dit, vraiment une bonne idée. Cela me rappelle, en fait, de Perle algorithme Trier --un qui, mais pas la même chose que votre idée, est également une solution de tri qui profite du concept très physique de la gravité et, sans surprise, nécessite du matériel spécialisé.
Autres conseils
Vous venez de le problème mis à jour. Calcul de l'ordre des effets gravitationnels aura, au mieux, l'O des algorithmes de tri que vous essayez de battre.
calcul de Gravitation est gratuit uniquement dans le monde réel. Dans programm vous devez modéliser. Ce sera un autre n minimum de complexité
tri général but est démontrable au mieux O (n log n). Pour améliorer cela, vous devez savoir quelque chose sur les données autres que seulement la façon de comparer les valeurs.
Si les valeurs sont tous les nombres, radix tri donne O (n) en supposant que vous avez limites supérieures et inférieures pour les nombres. Cette approche peut être étendue pour gérer un nombre quelconque - et en fin de compte, toutes les données dans un ordinateur est représenté en utilisant des nombres. Par exemple, vous pouvez chaînes de tri radix par, à chaque passage, le tri par un caractère comme si elle était un chiffre.
Malheureusement, la manipulation des tailles variables des données signifie faire un nombre variable de passes à travers le tri radix. Vous vous retrouvez avec O (n log m) où m est la plus grande valeur (puisque k bits vous donne une valeur de jusqu'à (2 ^ k) -1 pour non signé, la moitié pour signer). Par exemple, si vous triez les nombres entiers de 0 à m-1, bien - vous avez bien O (n log n) à nouveau
.un problème à traduire une autre peut être une très bonne approche, mais parfois il est juste d'ajouter une autre couche de complexité et les frais généraux.
L'idée peut sembler simple, mais la différence entre le monde réel et le modelado dans ce cas est que dans le monde réel, tout se passe en parallèle. Pour modéliser le genre de gravité que vous décrivez vous devez commencer par penser chaque objet sur un thread séparé avec un fil moyen sûr de les ajouter à une liste dans l'ordre où ils finissent. De façon réaliste en termes de performance de tri vous probablement utiliser une sorte rapide sur le temps, ou parce qu'ils sont à la même distance que le taux de chute. Toutefois, si votre formule est proportionnelle à la masse, vous voulez juste sauter tout cela et trier la masse.
Dans un fictif « ordinateur gravitationnelle » ce type de tri prendrait O (1) à résoudre. Mais avec les vrais ordinateurs comme nous le savons, votre pensée latérale ne serait pas utile.
Une fois que vous avez calculé tous les temps qu'ils prennent pour frapper le sol, vous aurez encore à trier ces valeurs. Vous n'êtes pas gagner vraiment quoi que ce soit, vous êtes juste le tri des nombres différents après avoir effectué un calcul supplémentaire inutile.
EDIT : Whoops. 101. physique oublié Bien sûr, ils vont tous frappé en même temps. :)
Toute sorte de modélisation comme celui-ci transforme juste un problème de tri dans une autre. Vous ne gagnerez rien.
Ignorer tous les défauts que tout le monde a mentionné d'autre, cela se résume essentiellement à un algorithme de O(n^2), non O(n). Vous auriez à itérer sur toutes les « sphères », trouver le « plus lourd » ou « le plus grand » un, puis le pousser sur une liste, puis rincer et répéter. à-dire, pour trouver celui qui frappe le sol d'abord, vous devez itérer sur la liste, si elle est le dernier, il prendrait le temps O(n), le second aurait pu prendre O(n-1), etc ... mais pire que cela, vous devez effectuer un tas d'opérations mathématiques à chaque fois juste pour calculer une valeur « temps » inutile quand on aurait pu trier sur la valeur que vous étiez intéressé par en premier lieu.
Hmmmm. tri par gravité.
Ignorant votre modèle de gravité est erroné, nous allons voir où cette idée nous prend.
La réalité physique a 10 ^ 80 processeurs.
Les bornes inférieures réelles de tri est connu pour être log (N) si vous avez des processeurs N / 2 pour trier des objets N.
Si vous avez plusieurs cœurs de processeur disponibles il n'y a aucune raison que vous ne pouvez pas exécuter mergesort sur plusieurs threads.
Il est en fait un algorithme de tri très célèbre appelé Spaghetti genre qui est un peu semblable à la vôtre. Vous pouvez vérifier quelques-unes des nombreuses analyses de celui-ci sur le web. par exemple. sur cstheory .

Il devrait certainement être que vous devriez avoir le matériel approprié pris en charge pour elle. Sinon, cela semble une idée très cool. L'espoir que quelqu'un présente un document IEEE pour faire de ce rêve fou visualisé.
J'adore l'idée! Il est intelligent. Alors que oui ce que disent les autres est en général correcte, que le O (n log n) lié est une prouvablement borne inférieure sur le problème de tri en général, nous devons garder à l'esprit que cette borne inférieure est vrai que pour comparaison à base modèles. Ce que vous proposez ici est un modèle tout à fait différent, il ne mérite plus la pensée.
En outre, comme James et Matrix ont souligné, le plus lourd ne doit pas voyager plus vite que le plus léger, vous évidemment d'adapter le modèle à quelque chose où l'objet plus lourd (nombre) serait en effet aller plus vite / plus (ou plus lent / moins encore) afin que vous puissiez en quelque sorte distinguer les nombres (une centrifugeuse vient à l'esprit aussi bien).
nécessite plus de pensée, mais votre idée est forte!
(Edit) Vous voyez maintenant l'idée de Phys2D Enrique, je pense qu'il fait un ensemble beaucoup plus de sens.
Une chose que je suggère est d'ignorer sans aucun doute l'aspect efficacité pour l'instant. (Je sais, je sais que le but était entier). Il est un nouveau modèle, et nous avons d'abord besoin de combler le fossé entre l'idée et sa mise en œuvre. Alors seulement, nous pouvons comprendre ce que la complexité de temps signifie que même pour ce modèle.
Je pense que le problème peut être plus simple comme ceci: vous voulez mettre les fonds des sphères à différentes hauteurs afin que lors d'une chute à gravités identiques le plus grand frappera le sol en premier, deuxième seconde, etc. Ceci est essentiellement équivalent à l'utilisation des lignes plutôt que des sphères ... dans ce cas, vous pouvez simplement dire que heightOffTheGround = MAX_VALUE -. masse
Vous n'avez pas besoin de vous soucier de l'accélération au fil du temps ... puisque vous ne vous inquiétez pas à quelle vitesse ils vont ou la physique réaliste, vous pouvez leur donner toute une vitesse initiale x, et partir de là.
Le problème est alors que nous avons essentiellement juste reformulé le problème et résolu le problème comme celui-ci (pseudo-code):
int[] sortedArray; // empty
int[] unsortedArray; // full of stuff
int iVal = MAX_INT_VALUE;
while (true)
{
foreach (currentArrayValue in sortedArray)
{
if (iVal = current array value
{
put it in my sortedArray
remove the value from my unsortedArray
}
}
if (unsortedArray is empty)
{
break; // from while loop
}
iVal--
}
Le problème est que pour exécuter le moteur physique, vous devez itérer sur chaque unité de temps, et qui sera O (1) ... avec très grande constante ... le nombre constant de valeurs delta que le système fonctionne sur. L'inconvénient est que, pour la très grande majorité de ces valeurs delta, vous essentiellement obtiendrez pas plus près de la réponse: à une itération donnée, il est très probable que toutes les sphères / lignes / tout ce qui sera déplacé ... mais aucun frappera.
Vous pouvez essayer de dire simplement, eh bien, nous allons passer beaucoup d'étapes intermédiaires et juste sauter en avant jusqu'à ce qu'un succès! Mais cela signifie que vous devez savoir lequel est le plus grand ... et vous êtes de retour à la question de tri.
Je vais adapter votre idée un peu. Nous avons nos objets, mais ils ne sont pas différentes en poids, mais la vitesse. Ainsi, au début tous les objets sont alignés sur la ligne de départ et sur le coup de départ, ils se déplacent tous avec leurs vitesses respectives à l'arrivée.
assez clair: Premier objet fini émet un signal, en disant qu'il est là. Vous attrapez le signal et d'écrire sur le papier des résultats qui il était.
D'accord, vous aurez envie de simuler cela.
Nous prenons la longueur de votre champ à L=1. Avec la taille de l'étape ∆t chacun de vos objets N déplace une longueur de vᵢ∙∆t à la fois.
Cela signifie que chaque objet a besoin avant d'atteindre les étapes sᵢ = L / (vᵢ∙∆t) l'arrivée.
Le point est maintenant, afin de faire la distinction entre deux objets avec des vitesses très proches, vous aurez besoin d'avoir un pas différent pour tous vos objets.
Maintenant, dans le meilleur cas, cela signifie que l'objet 1 se termine en une étape, l'objet 2 en deux et ainsi de suite. Par conséquent, le nombre total d'étapes est S = 1 + 2 + … + N = N∙(N + 1)/2. Ceci est de l'ordre N∙N.
Si ce n'est pas le meilleur des cas et les vitesses ne sont pas aussi proches les uns des autres, vous devrez réduire la taille de l'étape et en effet beaucoup plus itérer fois.
Si un ordinateur devait être construit que triée des objets en fonction de certains critères (ce qui est tout à fait ridicule de penser), alors je crois que l'ordre de complexité aurait rien à voir avec le nombre d'objets, mais le taux de l'accélération locale de la pesanteur. En supposant qu'il est modélisé dans la Terre, la complexité serait O (g 0 ) où g 0 est:
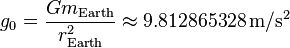
Le raisonnement simple est que le nombre d'objets sphériques (n) est sans objet si leurs centres sont alignés au départ. En outre, l'accélération due à la gravité aura un impact beaucoup plus grande que la hauteur elle-même car elle augmente. Par exemple, si l'on augmente la hauteur de tous les objets 10x, il ne serait pas les prendre 10 fois le temps de toucher le sol, mais bien moindre. Cela comprend diverses approximations négligeables que l'accélération dépend en fait de la distance entre deux objets, mais qui peut être ignoré que nous sommes plus intéressés par une plus grande image plutôt qu'une valeur spécifique.
Brillante idée quand même.
, j'aime aussi la vidéo de tri de pièces posté par @ Jeremy. Et l'objet enfin serait le orientation vers le moindre de mes soucis dans la construction d'une telle machine. En pensant plus à ce sujet, voici mes deux cents stupides sur la construction d'une telle machine:
O 0 o O o
. . . . .
. . . . .
. . . . .
= = = = =
Tous les objets sont de différentes tailles proportionnelles aux critères que nous voulons trier. Ils sont d'abord maintenues ensemble horizontalement par une tige mince qui traverse le centre de chaque sphère. Le = en bas sont spécialement conçus pour enregistrer une valeur (éventuellement leur position) quelque part dès qu'ils entrent en collision avec une sphère. Après toutes les sphères sont entrés en collision, nous aurons notre ordre de tri sur la base des valeurs enregistrées.
de réponse de Debilski:
Je vais adapter votre idée un peu. Nous faisons ont nos objets, mais ils ne diffèrent pas en poids, mais la vitesse. Ainsi, au à partir de tous les objets sont alignés à la ligne de départ et sur la mise en marche coup, ils vont tous se déplacent avec leur les vitesses respectives à l'arrivée.
assez clair: Premier objet fini émet un signal, en disant qu'il est Là. Vous attrapez le signal et écrire sur le papier des résultats qui était
Je simplifie un peu plus loin et dire que ces objets sont des nombres entiers positifs aléatoires. Et nous voulons les trier dans un ordre croissant à l'approche de zéro, donc ils ont un distance de zéro d qui est initialement égal à l'entier lui-même.
En supposant que la simulation se déroule en étapes de temps discrets à savoir cadres , dans chaque image, nouvelle distance serait de chaque objet: d = d - v et un objet obtiendriez ajouté à la liste lorsque son d ≤ 0. C'est une soustraction et une condition. Deux étapes discrètes pour chaque objet, de sorte que les calculs semblent être O (n):. Linear
Le hic est, il est linéaire pour une image uniquement! Il est multiplié par le nombre d'images f nécessaires pour terminer. La simulation elle-même est O (nf):. Quadratique
Cependant, si l'on prend la durée d'un cadre comme t argument nous obtenons la capacité d'influer sur le nombre de trames f de manière inversement proportionnelle. Nous pouvons augmenter t pour réduire f mais cela se fait au détriment de la précision, plus on augmente t, plus la probabilité que deux objets se terminent dans le même laps de temps donc être classé comme équivalent, même si elles ne sont pas. Nous obtenons donc un algorithme avec une précision réglable (comme il est dans la simulation des éléments finis les plus contextes)
Nous pouvons encore affiner en le transformant en une adaptation + algorithme récursif. Dans le code humain, ce serait:
function: FESort: arguments: OriginalList, Tolerance
define an empty local list: ResultList
while OriginalList has elements
define an empty local list: FinishedList
iterate through OriginalList
decrement the distance of each object by Tolerance
if distance is less than or equal to zero, move object from OriginalList to FinishedList
check the number of elements in FinishedList
when zero
set Tolerance to double Tolerance
when one
append the only element in FinishedList to ResultList
when more
append the result of FESort with FinishedList and half Tolerance to ResultList
return ResultList
Je me demande s'il y a une mise en œuvre réelle similaire qui fonctionne pour quelqu'un.
Sujet intéressant en effet:)
PS. Le pseudocode ci-dessus est mon idée de pseudo-code, s'il vous plaît ne hésitez pas à le réécrire de manière plus lisible ou s'il est conforme un.
Il y a quelques semaines, je pensais à la même chose.
Je pensais utiliser Phys2D bibliothèque pour la mettre en œuvre. Il ne peut être pratique, mais juste pour le plaisir. Vous pouvez également attribuer des poids négatifs aux objets pour représenter des nombres négatifs. Avec la bibliothèque phys2d vous pouvez définir la gravité si des objets ayant un poids négatif iront sur le toit et des objets avec un poids positif va tomber arranger .Ensuite tous les objets au milieu entre le sol et le toit avec la même distance entre le sol et le toit. Supposons que vous avez un tableau résultant r [] de longueur = nombre d'objets. Ensuite, chaque fois qu'un objet touche le toit que vous ajoutez au début du tableau r [0] et incrémenter le compteur, la prochaine fois un objet touche le toit vous l'ajoutez à r [1], chaque fois qu'un objet atteint le sol vous ajouter à la fin du tableau r [r.length-1], la prochaine fois que vous ajoutez à r [r.length-2]. Aux objets finaux qui n'ont pas bougé (resté flottant au milieu) peuvent être ajoutés au milieu du tableau (ces objets sont des 0).
Ce n'est pas efficace, mais peut vous aider à mettre en œuvre votre idée.
- Je crois qu'il est bon de mentionner / se référer à: constante gravitationnelle la masse est négligeable.
- Simuler un processus physique peut affecter la complexité du temps réel.
Analyse: (1) Tous les centres de sphères sont alignés au début (2) plus grand nombre ==> masse plus élevée ==> rayon supérieur ==> distance au sol inférieure (3) « vide » même accélération = même évolution de la vitesse ==> même distance du centre ==> comment rayon supérieur de la façon précédemment de ... la sphère va frapper le sol ==> technique sur le plan conceptuel OK, si bien physique quand une sphère a frappé le sol, il peut envoyer un signal indentification + temps frappé ... Wich donnera la liste triée Pratiquement ... pas une technique numérique 'bonne'
