Гравитационная сортировка: возможно ли это программно? [закрыто
 https://stackoverflow.com/questions/2489190
https://stackoverflow.com/questions/2489190
-
21-09-2019 - |
 italiano
italiano english
english français
français española
española 中国
中国 日本の
日本の العربية
العربية Deutsch
Deutsch 한국어
한국어 Português
Português Russian
RussianВопрос
Недавно я думал об использовании объектно -ориентированного дизайна в алгоритме сортировки. Однако я не смог найти правильный способ даже приблизиться к тому, чтобы сделать этот алгоритм сортировки, который сортирует во время O (n).
Хорошо, вот о чем я думал неделю. У меня есть набор входных данных. Я назначу массу каждому из входных данных (предполагайте, что входные данные - тип Mass и тип Sphere. Анкет Если мы предположим, что все объекты являются идеально сферическими объектами с формами, пропорциональными их массе, самый тяжелый, сначала касается земли.). Я буду размещать все свои входные данные в пространстве на том же расстоянии от Земли. И я сделаю их свободными падением. Согласно гравитационному законодательству, самый тяжелый в первую очередь попадает на землю. И порядок, в котором они попали, даст мне отсортированные данные. Это каким -то образом смешно, но внизу я чувствую, что это должно быть возможно, используя OO, который я узнал до настоящего времени
Действительно ли возможно сделать технику сортировки, которая использует гравитационную тягу, как сценарий, или я глуп/сумасшедший?
Редактировать: Оказывается, все объекты попадают на землю одновременно, поэтому я представил концепцию сферического объекта.
Решение
Дело в том, что, хотя один из идеи OOP может быть для моделирования реального мира, это не означает, что существует прямая переписка между тем, как долго что -то займет в реальном мире, и сколько времени потребуется, чтобы имитировать его с помощью компьютера.
Представьте себе фактические шаги, необходимые для вашей процедуры:
- Объект должен быть построен для каждого элемента в вашем наборе данных. На большинстве современных оборудования это одно потребует итерации и, следовательно, сделает вашу стратегию O (n) на Лучший.
- Эффект гравитации должен быть смоделирован для каждого объекта. Опять же, самый очевидный, простой способ реализации этого - это итерация.
- Время, когда каждый объект приземляется на поверхности «Земли» в вашей модели программирования, должно быть захвачено, и через некоторый механизм, специфичный для реализации, соответствующий объект должен быть вставлен в упорядоченный список в результате.
Учитывая проблему дальнейшего введения дополнительных осложнений. Спросите себя: насколько высоко вам нужно позиционировать эти объекты, чтобы начать? Очевидно достаточно высок, чтобы самый большой на самом деле водопад; то есть, дальше от земли, чем радиус самого большого объекта. Но как узнать, как далеко это? Вам нужно сначала определить самый большой объект в коллекции; Это, опять же, (вероятно) потребует итерации. Кроме того, можно представить, что это моделирование может быть многопоточно, чтобы попытаться имитировать поведение понятия в реальном времени объектов фактически падение; Но тогда вы обнаружите, что пытаетесь добавить элементы в коллекцию (операцию, которая, очевидно, занимает ненулевое количество времени) потенциально в то же время, когда обнаруживаются новые столкновения. Так что это также создаст проблемы с потоком.
Короче говоря, у меня проблемы с представлением о том, как эта идея может быть должным образом реализована, просто используя ООП без специального оборудования. Тем не менее, это действительно является хорошая идея. Это напоминает мне, на самом деле, о Сорт бусинок-Алгоритм, который, хотя и не такой же, как ваша идея, также является решением для сортировки, которое использует очень физическую концепцию гравитации и, что неудивительно, требует специализированного оборудования.
Другие советы
Вы только что пересмотрели проблему. Расчет порядка гравитационных эффектов будет иметь, в лучшем случае, из алгоритмов, которые вы пытаетесь победить.
Расчет гравитации бесплатный только в реальном мире. В программировании вам нужно моделировать его. Это будет еще один n в минимальном сложности
Сортировка общего назначения доказывает в лучшем случае O (n log n). Чтобы улучшить это, вы должны знать что -то о данных, кроме как сравнивать значения.
Если значения все числа, Радикс Сортировка дает O (n) при условии, что у вас есть верхние и нижние границы для чисел. Этот подход может быть расширен для обработки любого числа - и, в конечном счете, все данные в компьютере представлены с использованием чисел. Например, вы можете Radix-Sorts Strings, в каждом проходе сортируя по одному персонажу, как если бы это была цифра.
К сожалению, обработка размеров переменных данных означает, что переменное количество проходов через Radix Sort. В итоге вы получаете O (n log m), где m является наибольшим значением (поскольку k bits дает вам значение до (2^k) -1 для беспигнированного, вдвое, что для подписания). Например, если вы сортируете целые числа от 0 до M -1, ну, вы фактически снова получите O (n Log N).
Перевод одной проблемы на другую может быть очень хорошим подходом, но иногда это просто добавление еще одного слоя сложности и накладных расходов.
Идея может показаться простой, но разница между реальным миром и смоделированным в этом случае заключается в том, что в реальном мире все происходит параллельно. Чтобы моделировать гравитационную сортировку, как вы описываете, вам придется начать с задуматься о каждом объекте в отдельном потоке с безопасным способом поток, чтобы добавить их в список в порядке, который они заканчивают. Реально с точки зрения сортировки производительности, вы, вероятно, просто использовали бы быстрое сортирование в время или, поскольку они на том же расстоянии - скорость падения. Однако, если ваша формула пропорциональна массе, вы просто пропустите все это и сортируют массу.
В вымышленном «гравитационном компьютере» такого рода сортировки потребуется O (1), чтобы быть решена. Но с настоящими компьютерами, как мы это знаем, ваша боковая мысль не поможет.
Как только вы рассчитываете все время, которые они берут, чтобы попасть на землю, вам все равно придется сортировать эти значения. Вы на самом деле ничего не получаете, вы просто сортируете разные числа после выполнения некоторых дополнительных ненужных расчетов.
РЕДАКТИРОВАТЬ: Упс. Забыли физику 101. Конечно, они все поражают одновременно. :)
Любое подобное моделирование просто превращает одну проблему сортировки в другую. Вы ничего не получите.
Игнорируя все недостатки, которые упоминали все остальные, по сути, это сводится к O(n^2) Алгоритм, нет O(n). Анкет Вам придется повторить все «сферы», найти «самый тяжелый» или «самый большой», а затем выдвинуть его в список, затем промыть и повторить. т.е., чтобы найти тот, который сначала попадает на землю, вы должны итерации по всему списку, если он последний, это потребует O(n) время, второе могло бы взять O(n-1), и т. Д. Но хуже этого вы должны выполнять кучу математических операций каждый раз, просто чтобы рассчитать какое -то бесполезное значение «время», когда вы могли сортировать значение, которое вас интересовало в первую очередь.
Хмммм. Гравитационная сортировка.
Игнорирование вашей конкретной модели тяжести неверно, давайте посмотрим, куда нас приведет эта идея.
Физическая реальность имеет 10^80 процессоров.
Известно, что фактические нижние границы являются log (n), если у вас есть процессоры N/2 для сортировки N -объектов.
Если у вас есть несколько ядер CPU, у вас нет причин, по которым вы не можете запустить Mergesort в нескольких потоках.
На самом деле существует довольно известный алгоритм сортировки под названием Spaghetti Sort, который похож на ваш. Вы можете проверить некоторые из многих анализов в Интернете. Например CSTheory.

Это должно быть определенно только у вас должно быть поддержанное для него аппаратное обеспечение. В противном случае это звучит очень крутая идея. Надеюсь, кто -то представляет бумагу IEEE, чтобы сделать эту сумасшедшую мечту визуализироваться.
Мне нравится идея! Это умно. Пока да, что говорят другие в целом Правильно, что граница O (n log n) является доказуемо более низкой связанной с проблемой сортировки в целом, мы должны помнить, что эта нижняя граница верна только для сравнение на основе модели. То, что вы предлагаете здесь, - это совсем другая модель, она заслуживает дальнейшего размышления.
Кроме того, как отмечали Джеймс и Матрица, более тяжелый не движется быстрее, чем легче, вам, очевидно, нужно адаптировать модель к чему -то, где более тяжелый объект (число) действительно будет двигаться быстрее/дальше (или медленнее/меньше Далее) так, чтобы вы могли каким -то образом различить цифры (также приходит центрифуга).
Требуется больше размышлений, но ваша идея резкая!
(Редактировать) Теперь, глядя на идею Enrique Phys2D, я думаю, что это имеет гораздо больше смысла.
Одна вещь, которую я бы предложил, - это определенно игнорировать аспект эффективности на данный момент. (Я знаю, я знаю, что это была вся цель). Это новая модель, и нам сначала нужно преодолеть разрыв между идеей и ее реализацией. Только тогда мы можем понять, что означает сложность времени для этой модели.
Я думаю, что проблема может быть сделана проще, как это: вы хотите поставить днищики сфер на разные высоты, чтобы при сброшении на идентичных тяжести самый большой погрузился в землю первым, второй по величине второй и т. Д. Это по сути эквивалентно использованию Линии, а не сфер ... в этом случае вы можете просто сказать, что heightoffgeground = max_value - масса.
Вам также не нужно беспокоиться о ускорении с течением времени ... поскольку вам все равно, как быстро они идут или реалистичны, вы можете дать им все начальную скорость x и оттуда.
Проблема в том, что мы по существу только что пересмотрели проблему и решили ее так (псевдокод):
int[] sortedArray; // empty
int[] unsortedArray; // full of stuff
int iVal = MAX_INT_VALUE;
while (true)
{
foreach (currentArrayValue in sortedArray)
{
if (iVal = current array value
{
put it in my sortedArray
remove the value from my unsortedArray
}
}
if (unsortedArray is empty)
{
break; // from while loop
}
iVal--
}
Проблема в том, что для запуска физического двигателя вы должны переехать в каждую единицу времени, и это будет O (1) ... с очень Большая постоянная ... постоянное количество значений дельты, на которых будет работать система. Недостаток заключается в том, что для очень подавляющего большинства этих значений дельты вы, по сути, не будете приближаться к ответу: на любой итерации вполне вероятно, что все сферы/линии/все, что переместится ... но нет ударит.
Вы можете попытаться просто сказать, ну, давайте пропустим много промежуточных шагов и просто прыгнули вперед, пока один не попадет! Но это означает, что вы должны знать, какой из них самый большой ... и вы вернулись к проблеме сортировки.
I’ll adapt your idea a little. We do have our objects but they don’t differ in weight, but in speed. So, at the beginning all objects are aligned at the starting line and on the starting shot, they’ll all move with their respective velocities to the finish.
Clear enough: First object in finish will emit a signal, saying it is there. You catch the signal and write to the results paper who it was.
Okay, so you’ll want to simulate that.
We take the length of your field to be L=1. With step size ∆t each of your N objects moves a length of vᵢ∙∆t at a time.
That means each object needs sᵢ = L / (vᵢ∙∆t) steps before reaching the finish.
The point is now, in order to distinguish between two objects with very close speeds, you’ll need to have a different step size for all of your objects.
Now, in the best case, this means that object 1 finishes in one step, object 2 in two and so on. Therefore, the total number of steps is S = 1 + 2 + … + N = N∙(N + 1)/2. This is of order N∙N.
If it’s not the best case and the velocities are not equally close to each other, you’ll have to lower the step size and in effect iterate many more times.
If a computer were to be built that sorted objects based on some criteria (which is not utterly ridiculous to think about), then I believe the order of complexity would have nothing to do with the number of objects, but rather the rate of local acceleration due to gravity. Assuming it's modeled in Earth, the complexity would be O(g0) where g0 is:
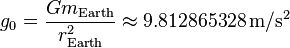
The simple reasoning is that the number of spherical objects (n) is irrelevant if their centers are aligned at start. Moreover, the acceleration due to gravity will have a much bigger impact than the height itself as it increases. For instance, if we increase the height of all objects by 10x, it wouldn't take them 10x the time to hit the ground, but much lesser. This includes various negligible approximations as the acceleration actually depends on distance between two objects, but that can be ignored as we are more interested in a bigger picture rather than a specific value.
Brilliant idea nevertheless.
Also, I love the coin sorting video posted by @Jeremy. And finally object orientedness would be the least of my concerns in building such a machine. Thinking more about it, here's my stupid two cents on building such a machine:
O 0 o O o
. . . . .
. . . . .
. . . . .
= = = = =
All objects are of varying sizes proportional to the criteria we want to sort by. They are initially held together horizontally by a thin rod that runs through the center of each sphere. The = at the bottom are specially designed to record a value (optionally their position) somewhere as soon as they collide with a sphere. After all spheres have collided, we will have our sorted order based on the recorded values.
from Debilski's answer:
I’ll adapt your idea a little. We do have our objects but they don’t differ in weight, but in speed. So, at the beginning all objects are aligned at the starting line and on the starting shot, they’ll all move with their respective velocities to the finish.
Clear enough: First object in finish will emit a signal, saying it is there. You catch the signal and write to the results paper who it was
I'd simplify it a step further and say these objects are random positive integers. And we want to sort them in an ascending order as they approach zero, so they have a distance from zero d which initially is equal to the integer itself.
Assuming the simulation takes place in discrete time steps i.e. frames, in every frame, every object's new distance would be: d = d - v and an object would get added to the list when its d ≤ 0. That is one subtraction and one conditional. Two discrete steps for each object, so the calculations seem to be O(n): linear.
The catch is, it is linear for one frame only! It is multiplied by the number of frames f required to finish. The simulation itself is O(nf): quadratic.
However, if we take the duration of a frame as the argument t we get the ability to affect the number of frames f in an inversely proportional manner. We can increase t to reduce f but this comes at the cost of accuracy, the more we increase t, the more the probability that two objects will finish in the same time frame therefore be listed as equivalent, even if they are not. So we get an algorithm with adjustable accuracy (as it is in most finite element simulation contexts)
We can further refine this by turning it into an adaptive+recursive algorithm. In human code it would be:
function: FESort: arguments: OriginalList, Tolerance
define an empty local list: ResultList
while OriginalList has elements
define an empty local list: FinishedList
iterate through OriginalList
decrement the distance of each object by Tolerance
if distance is less than or equal to zero, move object from OriginalList to FinishedList
check the number of elements in FinishedList
when zero
set Tolerance to double Tolerance
when one
append the only element in FinishedList to ResultList
when more
append the result of FESort with FinishedList and half Tolerance to ResultList
return ResultList
I'm wondering if there's any real similar implementation that works for someone.
Interesting subject indeed :)
PS. The pseudocode above is my idea of pseudocode, please feel free to rewrite it in a more legible or conformant way if there is one.
Some weeks ago I was thinking about the same thing.
I thought to use Phys2D library to implement it. It may not be practical but just for fun. You could also assign negative weights to the objects to represent negative numbers. With phys2d library you can define the gravity so objects with negative weight will go to the roof and objects with positive weight will fall down .Then arrange all objects in the middle between the floor and roof with the same distance between floor and roof. Suppose you have a resulting array r[] of length=number of objects. Then every time an object touches the roof you add it at the beginning of the array r[0] and increment the counter, next time an object touches the roof you add it at r[1], every time an object reaches the floor you add it at the end of the array r[r.length-1], next time you add it at r[r.length-2]. At the end objects that didn't move(stayed floating in the middle) can be added in the middle of the array(these objects are the 0's).
This is not efficient but can help you implement your idea.
- I believe it is nice to mention/refer to: What is the relation
between P vs. NP and Nature's ability to solve NP problems
efficiently?
Sorting is
O(nlog(n)), why not trying to solve NP-hard problems? - By the laws of physics objects fall with proportions to the gravitational constant the mass is negligible.
- Simulating a physical process can affect the actual time complexity.
Analyse : (1) All centers of spheres are aligned at start (2) greater number ==> mass higher ==> radius greater ==> distance to the ground lower (3) in 'vacuum' same acceleration = same speed evolution ==> same distance for the center ==> how greater de radius...how earlier the sphere will hit the ground ==> conceptually OK, good physical technique if when a sphere hit the ground it can send an indentification signal + hit time ... wich will give the sorted list Practically...not a 'good' numeric technique
