在windbg!堆输出中,“尺寸”数字意味着什么?
 https://stackoverflow.com/questions/2706634
https://stackoverflow.com/questions/2706634
 italiano
italiano english
english français
français española
española 中国
中国 日本の
日本の العربية
العربية Deutsch
Deutsch 한국어
한국어 Português
Português Russian
Russian题
我在DMP文件中看到了这样的输出:
Heap entries for Segment00 in Heap 00150000
00150640: 00640 . 00040 [01] - busy (40)
00150680: 00040 . 01808 [01] - busy (1800)
00151e88: 01808 . 00210 [01] - busy (208)
00152098: 00210 . 00228 [00]
001522c0: 00228 . 00030 [01] - busy (22)
001522f0: 00030 . 00018 [01] - busy (10)
00152308: 00018 . 00048 [01] - busy (3c)
windbg文档说:
Heap entries for Segment00 in Heap 250000
0x01 - HEAP_ENTRY_BUSY
0x02 - HEAP_ENTRY_EXTRA_PRESENT
0x04 - HEAP_ENTRY_FILL_PATTERN
0x08 - HEAP_ENTRY_VIRTUAL_ALLOC
0x10 - HEAP_ENTRY_LAST_ENTRY
0x20 - HEAP_ENTRY_SETTABLE_FLAG1
0x40 - HEAP_ENTRY_SETTABLE_FLAG2
Entry Prev Cur 0x80 - HEAP_ENTRY_SETTABLE_FLAG3
Address Size Size flags (Bytes used) (Tag name)
00250000: 00000 . 00b90 [01] - busy (b90)
00250b90: 00b90 . 00038 [01] - busy (38)
00250bc8: 00038 . 00040 [07] - busy (24), tail fill (NTDLL!LDR Database)
但是,文档的间距很奇怪。这是指“入口地址”和“ prev大小”和“ cur size”,还是“入口”“ prev”和“ cur”不是下面的行?
“上述大小”和“ cur尺寸”是什么意思?特别是关于“使用的字节”。 “使用的字节”和“ Cur大小”有什么区别?
解决方案
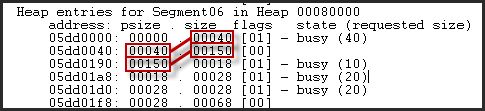
堆段是给定堆的连续内存块。它也是一系列堆条目。
要向前走一系列堆条目,我们可以使用Cur大小作为偏移量来进入下一个堆条目。
为了向后走堆条目列表,我们可以使用上述大小作为偏移量,以达到上一个条目的开始。
在这里(下图),您可以看到PSIZE(上一个尺寸)及其与该条目之前的大小(当前大小)的关系。
使用的字节是通过从该块末尾的未使用字节的数量中减去实际分配的未使用字节的数量来计算的。这使您可以在将请求的大小四舍五入到分配粒度之前确定所需的分配大小。
不隶属于 StackOverflow
