Was bedeutet die ‚Größe‘ Zahlen in der windbg! Heap-Ausgabe?
 https://stackoverflow.com/questions/2706634
https://stackoverflow.com/questions/2706634
 italiano
italiano english
english français
français española
española 中国
中国 日本の
日本の العربية
العربية Deutsch
Deutsch 한국어
한국어 Português
Português Russian
RussianFrage
Ich sehe Ausgabe wie diese in meiner DMP-Datei:
Heap entries for Segment00 in Heap 00150000
00150640: 00640 . 00040 [01] - busy (40)
00150680: 00040 . 01808 [01] - busy (1800)
00151e88: 01808 . 00210 [01] - busy (208)
00152098: 00210 . 00228 [00]
001522c0: 00228 . 00030 [01] - busy (22)
001522f0: 00030 . 00018 [01] - busy (10)
00152308: 00018 . 00048 [01] - busy (3c)
Die WinDbg docs sagen diese:
Heap entries for Segment00 in Heap 250000
0x01 - HEAP_ENTRY_BUSY
0x02 - HEAP_ENTRY_EXTRA_PRESENT
0x04 - HEAP_ENTRY_FILL_PATTERN
0x08 - HEAP_ENTRY_VIRTUAL_ALLOC
0x10 - HEAP_ENTRY_LAST_ENTRY
0x20 - HEAP_ENTRY_SETTABLE_FLAG1
0x40 - HEAP_ENTRY_SETTABLE_FLAG2
Entry Prev Cur 0x80 - HEAP_ENTRY_SETTABLE_FLAG3
Address Size Size flags (Bytes used) (Tag name)
00250000: 00000 . 00b90 [01] - busy (b90)
00250b90: 00b90 . 00038 [01] - busy (38)
00250bc8: 00038 . 00040 [07] - busy (24), tail fill (NTDLL!LDR Database)
Der Abstand ist aber in der Dokumentation seltsam. Heißt die ‚Entry-Adresse‘ und ‚zurück Größe‘ und ‚Köter Größe‘ oder sind der ‚Eintrag‘ ‚zurück‘ und ‚Aktuell‘ nicht für die Linie unten?
Was bedeutet ‚zurück Größe‘ und ‚Köter Größe‘ bedeuten? Insbesondere im Hinblick auf ‚verwendeten Bytes‘. Was ist der Unterschied zwischen ‚Bytes verwendet‘ und ‚Köter Größe‘?
Lösung
Ein Heap-Segment ist ein kontinuierlicher Speicherblock für einen gegebenen Haufen. Es ist auch eine Kette von Heap-Einträgen.
eine Liste von Heap-Einträgen gehen leiten wir die Cur Größe als Offset verwenden können, um den nächsten Haufen Eintrag zu erhalten.
eine Liste von Heap-Einträgen, um rückwärts gehen können wir die vorherige Größe verwenden als zu Beginn des vorigen Eintrags Offset zu erhalten.
Hier (Bild unten) können Sie die psize (iV Größe) und seine Beziehung zu der Größe (aktuellen Größe) für den Eintrag sehen, kurz bevor es.
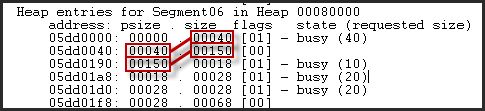
Das Bytes verwendet wird, indem die Größe von der der Anzahl des nicht verwendeten Bytes am Ende dieser Blöcke berechnet, die nicht tatsächlich zugewiesen wurde. Auf diese Weise können Sie die Größe der Zuordnung bestimmen, die vor dem Runden die gewünschte Größe für die Zuweisung Granularität angefordert wurde.
