Что значит цифры «размера» в Windbg!
 https://stackoverflow.com/questions/2706634
https://stackoverflow.com/questions/2706634
 italiano
italiano english
english français
français española
española 中国
中国 日本の
日本の العربية
العربية Deutsch
Deutsch 한국어
한국어 Português
Português Russian
RussianВопрос
Я вижу, как это в моем файле DMP:
Heap entries for Segment00 in Heap 00150000
00150640: 00640 . 00040 [01] - busy (40)
00150680: 00040 . 01808 [01] - busy (1800)
00151e88: 01808 . 00210 [01] - busy (208)
00152098: 00210 . 00228 [00]
001522c0: 00228 . 00030 [01] - busy (22)
001522f0: 00030 . 00018 [01] - busy (10)
00152308: 00018 . 00048 [01] - busy (3c)
Документы Windbg говорят это:
Heap entries for Segment00 in Heap 250000
0x01 - HEAP_ENTRY_BUSY
0x02 - HEAP_ENTRY_EXTRA_PRESENT
0x04 - HEAP_ENTRY_FILL_PATTERN
0x08 - HEAP_ENTRY_VIRTUAL_ALLOC
0x10 - HEAP_ENTRY_LAST_ENTRY
0x20 - HEAP_ENTRY_SETTABLE_FLAG1
0x40 - HEAP_ENTRY_SETTABLE_FLAG2
Entry Prev Cur 0x80 - HEAP_ENTRY_SETTABLE_FLAG3
Address Size Size flags (Bytes used) (Tag name)
00250000: 00000 . 00b90 [01] - busy (b90)
00250b90: 00b90 . 00038 [01] - busy (38)
00250bc8: 00038 . 00040 [07] - busy (24), tail fill (NTDLL!LDR Database)
Интервал странный в документах, хотя. Значит ли это «адрес входа» и «Prev Size» и «Prev», или «запись» «Prev» и «CUR» не для строки ниже?
Что означает «предыдущий размер» и «порок»? Особенно в отношении «использованных байтов». В чем разница между «BYTES используемыми» и «по размерам»?
Решение
Сегмент кучи - это непрерывный блок памяти для данной кучи. Это также цепочка доходов кучи.
Чтобы пройти список записей кучи вперед, мы можем использовать размер Curry в качестве смещения, чтобы добраться до следующей записи кучи.
Чтобы пройти список записей кучи назад, мы можем использовать размер Prev в качестве смещения, чтобы добраться до начала предыдущей записи.
Здесь (рисунок ниже) вы можете увидеть Psize (предыдущий размер) и его отношения с размером (размер текущего) для записи непосредственно перед ним.
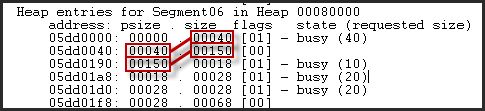
Используемые байты рассчитываются путем вычитания размера от количества неиспользованных байтов в конце этого блока, которые на самом деле не были выделены. Это позволяет определить размер выделения, который был запрошен до того, как округлить запрошенный размер к детализации распределения.
