用于计算百分位数的快速算法以删除异常值
 https://stackoverflow.com/questions/3779763
https://stackoverflow.com/questions/3779763
-
04-10-2019 - |
 italiano
italiano english
english français
français española
española 中国
中国 日本の
日本の العربية
العربية Deutsch
Deutsch 한국어
한국어 Português
Português Russian
Russian题
我有一个程序,需要重复计算数据集的大约百分位数(顺序统计量),以便在进一步处理之前删除异常值。我目前是通过对值数组进行排序并选择适当的元素来做到的;这是可行的,但是尽管该计划是相当小的一部分,但这是对配置文件的明显斑点。
更多信息:
- 数据集包含最多100000个浮点数的顺序,并假定为“合理”的分布式 - 不太可能重复或在特定值接近密度的巨大尖峰;而且,如果出于某种奇怪的原因,分布是奇怪的,那么近似值就可以降低准确,因为数据可能会混乱并进一步处理可疑。但是,数据不一定是统一或正常分布的;堕落的不可能是非常不可能的。
- 大概的解决方案会很好,但我确实需要了解 如何 近似引入错误以确保其有效。
- 由于目的是删除异常值,因此我始终在相同数据上计算两个百分位数:例如,一个为95%,一个为5%。
- 该应用在C#中,c ++中的繁重举重。伪代码或以前的库都可以。
- 只要合理,完全不同的删除异常值的方式也可以。
- 更新: 看来我正在寻找大约 选择算法.
尽管这一切都是在循环中完成的,但数据每次都不同,因此重复使用数据架构并不容易 对于这个问题.
实施解决方案
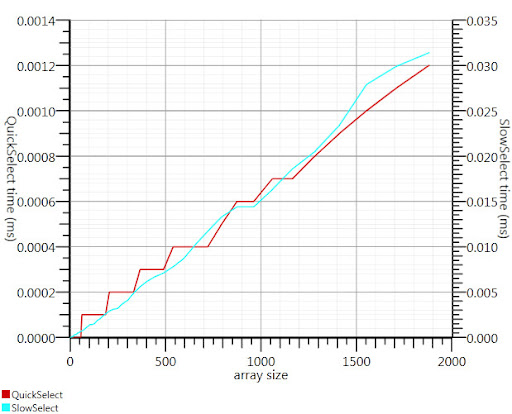
使用Gronim建议的Wikipedia选择算法将运行时间的这一部分降低了约20。
由于我找不到C#实施,这就是我想到的。对于小阵列而言,它的速度还要快。在1000个元素时,它快25倍。
public static double QuickSelect(double[] list, int k) {
return QuickSelect(list, k, 0, list.Length);
}
public static double QuickSelect(double[] list, int k, int startI, int endI) {
while (true) {
// Assume startI <= k < endI
int pivotI = (startI + endI) / 2; //arbitrary, but good if sorted
int splitI = partition(list, startI, endI, pivotI);
if (k < splitI)
endI = splitI;
else if (k > splitI)
startI = splitI + 1;
else //if (k == splitI)
return list[k];
}
//when this returns, all elements of list[i] <= list[k] iif i <= k
}
static int partition(double[] list, int startI, int endI, int pivotI) {
double pivotValue = list[pivotI];
list[pivotI] = list[startI];
list[startI] = pivotValue;
int storeI = startI + 1;//no need to store @ pivot item, it's good already.
//Invariant: startI < storeI <= endI
while (storeI < endI && list[storeI] <= pivotValue) ++storeI; //fast if sorted
//now storeI == endI || list[storeI] > pivotValue
//so elem @storeI is either irrelevant or too large.
for (int i = storeI + 1; i < endI; ++i)
if (list[i] <= pivotValue) {
list.swap_elems(i, storeI);
++storeI;
}
int newPivotI = storeI - 1;
list[startI] = list[newPivotI];
list[newPivotI] = pivotValue;
//now [startI, newPivotI] are <= to pivotValue && list[newPivotI] == pivotValue.
return newPivotI;
}
static void swap_elems(this double[] list, int i, int j) {
double tmp = list[i];
list[i] = list[j];
list[j] = tmp;
}
谢谢,格罗米姆,指我指向正确的方向!
解决方案
Henrik的直方图解决方案将起作用。您还可以使用选择算法在O(n)中的N元素数组中有效地找到k最大或最小的元素。将其用于第95个百分位集合k = 0.05n并找到k最大元素。
参考:
http://en.wikipedia.org/wiki/selection_algorithm#selecting_k_smallest_or_or_largest_elements
其他提示
您可以从数据集的一部分中估计百分位数,例如前几千点。
这 Glivenko – cantelli定理 如果您可以将数据点独立,则确保这将是一个相当不错的估计。
我曾经通过计算 标准偏差. 。距离的所有距离的2(或3)倍,与Avarage的标准偏差更为异常。 2次=约95%。
由于您正在计算avarage,因此计算标准偏差也非常快速。
您还可以仅使用数据子集来计算数字。
将数据的最小值和最大值之间的间隔划分为(例如)1000个垃圾箱,并计算直方图。然后建立部分总和,然后查看它们首先超过5000或95000的位置。
我能想到几种基本方法。首先是计算范围(通过找到最高和最低值),将每个元素投射到一个百分位((x -min) /范围),并抛出任何评估的元素,低于0.05或高于.95。
第二个是计算平均值和标准偏差。与平均值(在两个方向上)的2个标准偏差的跨度将围绕正常分布的样品空间的95%,这意味着您的离群值将在<2.5和> 97.5%。计算系列的平均值是线性的,标准开发(标准DEV(每个元素的差和均值之和)的平方根也是线性的)。然后,从均值中减去2个sigmas,并在均值中添加2个sigmas,并且您的离群极限范围更高。
这两个都将在大致线性时间内计算;第一个需要两次传球,第二次通过三次(一旦有限制,您仍然必须丢弃异常值)。由于这是一个基于列表的操作,因此我认为您不会找到对数或恒定复杂性的任何东西;任何进一步的绩效提高都需要优化迭代和计算,或通过在子样本上执行计算(例如每个第三个元素)来引入错误。
对您的问题的一个很好的答案似乎是 兰萨克。给定模型和一些嘈杂的数据,该算法有效地恢复了模型的参数。
您将不得不选择一个可以映射数据的简单模型。任何光滑的东西都很好。假设几个高斯人的混合物。 RANSAC将设置模型的参数,并同时估算一组Inliners。然后扔掉任何不适合模型的东西。
即使数据不正态分布,您也可以过滤2或3个标准偏差。至少,这将以一致的方式完成,这应该很重要。
当您删除异常值时,STD开发人员将会更改,您可以循环进行此操作,直到STD DEV的更改最小。您是否要这样做取决于您为什么要以这种方式操纵数据。一些统计学家有主要的保留措施来消除异常值。但是有些人删除了异常值,以证明数据是相当正态分布的。
不是专家,但我的记忆暗示:
- 为了确定百分位点,您需要分类并计数
- 从数据中获取样本并计算百分位数听起来像是一个不错的近似计划的好计划
- 如果没有,正如亨里克(Henrik)所建议的那样,如果您做桶并计算它们,则可以避免完全排序
一组100K元素的数据几乎没有时间进行排序,因此我认为您必须重复执行此操作。如果数据集的相同集只是稍微更新,最好是建造一棵树(O(N log N))然后在进来时删除和添加新的要点(O(K log N) 在哪里 K 是更改的点数)。否则, k已经提到的最大元素解决方案为您提供了 O(N) 对于每个数据集。
