Algoritmo rápido para los percentiles para eliminar los valores extremos de computación
 https://stackoverflow.com/questions/3779763
https://stackoverflow.com/questions/3779763
-
04-10-2019 - |
 italiano
italiano english
english français
français española
española 中国
中国 日本の
日本の العربية
العربية Deutsch
Deutsch 한국어
한국어 Português
Português Russian
RussianPregunta
I tiene un programa que las necesidades para calcular repetidamente el percentil aproximado (orden estadística) de un conjunto de datos a fin de eliminar valores atípicos antes del procesamiento adicional. Actualmente estoy haciendo así que por la clasificación de la matriz de valores y elegir el elemento apropiado; esto es factible, pero es un problema pasajero notable en los perfiles a pesar de ser una parte bastante pequeña del programa.
Más información:
- El conjunto de datos contiene en el orden de hasta 100.000 números de punto flotante, y supone que es "razonablemente" distribuido - hay poco probable que sea duplicados ni grandes picos en la densidad cerca de valores particulares; y si por alguna extraña razón, la distribución es impar, está bien para una aproximación a ser menos preciso, ya que los datos son probablemente mal estado procesamiento de todos modos y aún más dudosa. Sin embargo, los datos no es necesariamente distribuida de manera uniforme o normalmente; es algo muy poco probable que sea degenerada.
- Una solución aproximada estaría bien, pero tengo necesidad de entender ¿Cómo introduce el error de aproximación para asegurarse de que es válido.
- Puesto que el objetivo es eliminar valores atípicos, estoy calculando dos percentiles más de los mismos datos en todo momento: por ejemplo, una a 95% y una a 5%.
- La aplicación es en C # con trozos de trabajo pesado en C ++; pseudocódigo o una biblioteca preexistente en cualquiera estaría bien.
- Una manera totalmente diferente de la eliminación de valores atípicos estaría bien también, siempre y cuando sea razonable.
- Actualización: Parece que estoy buscando un aproximado algoritmo de selección .
A pesar de todo esto se hace en un bucle, los datos es (ligeramente) diferente cada vez, así que no es fácil de reutilizar una estructura de datos como se hizo para esta pregunta .
implementado la solución
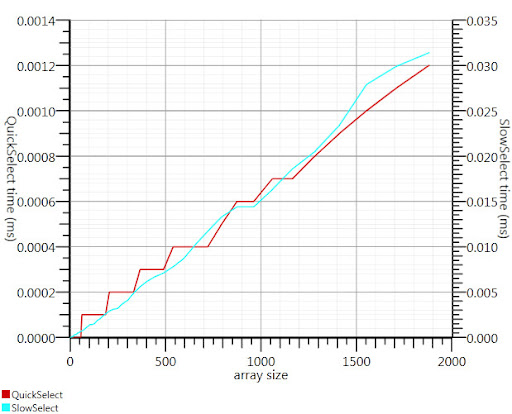
Usando el algoritmo de selección wikipedia como se sugiere por Gronim reducida esta parte del tiempo de ejecución en un factor 20.
Como no podía encontrar una aplicación C #, esto es lo que ocurrió. Es más rápido, incluso para las pequeñas entradas que Array.Sort; y en 1000 los elementos que es 25 veces más rápido.
public static double QuickSelect(double[] list, int k) {
return QuickSelect(list, k, 0, list.Length);
}
public static double QuickSelect(double[] list, int k, int startI, int endI) {
while (true) {
// Assume startI <= k < endI
int pivotI = (startI + endI) / 2; //arbitrary, but good if sorted
int splitI = partition(list, startI, endI, pivotI);
if (k < splitI)
endI = splitI;
else if (k > splitI)
startI = splitI + 1;
else //if (k == splitI)
return list[k];
}
//when this returns, all elements of list[i] <= list[k] iif i <= k
}
static int partition(double[] list, int startI, int endI, int pivotI) {
double pivotValue = list[pivotI];
list[pivotI] = list[startI];
list[startI] = pivotValue;
int storeI = startI + 1;//no need to store @ pivot item, it's good already.
//Invariant: startI < storeI <= endI
while (storeI < endI && list[storeI] <= pivotValue) ++storeI; //fast if sorted
//now storeI == endI || list[storeI] > pivotValue
//so elem @storeI is either irrelevant or too large.
for (int i = storeI + 1; i < endI; ++i)
if (list[i] <= pivotValue) {
list.swap_elems(i, storeI);
++storeI;
}
int newPivotI = storeI - 1;
list[startI] = list[newPivotI];
list[newPivotI] = pivotValue;
//now [startI, newPivotI] are <= to pivotValue && list[newPivotI] == pivotValue.
return newPivotI;
}
static void swap_elems(this double[] list, int i, int j) {
double tmp = list[i];
list[i] = list[j];
list[j] = tmp;
}
Gracias, Gronim, para mí apuntando en la dirección correcta!
Solución
La solución histograma de Henrik funcionará. También puede utilizar un algoritmo de selección de manera eficiente encontrar el k más grande o más pequeños elementos en una matriz de n elementos en O (n). Para utilizar esto para el 95º percentil conjunto de k = 0,05 N y encontrar los k elementos más grandes.
Referencia:
http://en.wikipedia.org/wiki/Selection_algorithm#Selecting_k_smallest_or_largest_elements
Otros consejos
Se podría estimar sus percentiles de sólo una parte de su conjunto de datos, al igual que los primeros miles de puntos.
El Glivenko-Cantelli teorema asegura que esto sería una estimación bastante buena, si se puede asumir sus puntos de datos para ser independiente.
I usado para identificar los valores atípicos mediante el cálculo de la desviación estándar . Todo con una distancia más como 2 (o 3) veces la desviación estándar de la avarage es un valor atípico. 2 veces = aproximadamente 95%.
Debido a que su calculando la normalito, su también muy fácil de calcular la desviación estándar es muy rápido.
También es posible usar sólo un subconjunto de los datos para el cálculo de los números.
Se divide el intervalo entre el mínimo y el máximo de sus datos en (por ejemplo) 1000 contenedores y calcular un histograma. A continuación, crear sumas parciales y ver donde primero exceden 5000 o 95000.
Hay un par de enfoques básicos que se me ocurren. En primer lugar es para calcular el rango (mediante la búsqueda de los valores máximos y mínimos), proyectar cada elemento a un percentil. ((X - min) / intervalo) y tirar fuera cualquiera que evaluar para bajar de 0,05 o superior a 0,95
La segunda es calcular la desviación media y estándar. Un lapso de 2 desviaciones estándar de la media (en ambas direcciones) encerrará 95% de un espacio de muestra distribuida normalmente, es decir, sus valores atípicos sería en el <2,5 y> 97,5 percentiles. El cálculo de la media de una serie es lineal, como es el dev estándar (raíz cuadrada de la suma de la diferencia de cada elemento y la media). A continuación, restar 2 sigmas de la media, y agregar 2 sigmas a la media, y usted tiene sus límites de valores atípicos.
Ambos computará en el tiempo más o menos lineal; el primero requiere dos pasos, el segundo toma tres (una vez que tenga sus límites todavía tiene que descartar los valores atípicos). Dado que esta es una operación basada en la lista, no creo que se encuentra cualquier cosa con la complejidad logarítmica o constante; cualquier ganancia aún más el rendimiento requerirían o bien la optimización de la iteración y el cálculo, o la introducción de error mediante la realización de los cálculos en una sub-muestra (tal como cada tercer elemento).
Una buena respuesta general a su problema parece ser RANSAC .
Dado un modelo, y algunos datos ruidosos, el algoritmo recupera de manera eficiente los parámetros del modelo.
Usted tendrá que elegir un modelo simple que puede mapear sus datos. Cualquier cosa suave debe estar bien. Vamos a decir una mezcla de unos gaussianas. RANSAC fijará los parámetros de su modelo y estimar un conjunto de inliners al mismo tiempo. Luego tirar todo lo que no encaja en el modelo correctamente.
podría filtrar 2 o 3 desviación estándar incluso si los datos no se distribuyen normalmente; al menos, que se llevará a cabo de una manera consistente, que debe ser importante.
Como quitar los valores atípicos, el std dev va a cambiar, usted puede hacer esto en un bucle hasta que el cambio en std dev es mínima. Independientemente de si usted quiere hacer esto depende de qué estás manipulando los datos de esta forma. Hay grandes reservas de algunos estadísticos a la eliminación de valores atípicos. Sin embargo, algunos Retire los valores extremos para demostrar que los datos se distribuyen normalmente bastante.
No es un experto, pero mi memoria sugiere:
- percentil para determinar exactamente los puntos que necesita para ordenar y recuento
- toma de una muestra a partir de los datos y calcular los valores de los percentiles sonidos como un buen plan para la aproximación decente si se puede obtener una muestra de buena
- Si no es así, como se sugiere por Henrik, se puede evitar el tipo completo si lo hace los cubos y contarlos
Un conjunto de datos de elementos de 100k lleva casi no hay tiempo para clasificar, por lo que se supone que tiene que hacer esto varias veces. Si el conjunto de datos es el mismo conjunto acaba de actualizar un poco, que es el mejor de la construcción de un árbol (O(N log N)) y luego eliminar y añadir nuevos puntos a medida que llegan (O(K log N) donde K es el número de puntos cambiado). De lo contrario, el más grande kth solución de elementos ya mencionados le da O(N) para cada conjunto de datos.
