Schneller Algorithmus zur Berechnung Perzentile zu Ausreißern entfernen
 https://stackoverflow.com/questions/3779763
https://stackoverflow.com/questions/3779763
-
04-10-2019 - |
 italiano
italiano english
english français
français española
española 中国
中国 日本の
日本の العربية
العربية Deutsch
Deutsch 한국어
한국어 Português
Português Russian
RussianFrage
Ich habe ein Programm, dass der Bedarf wiederholt, um die ungefähre Perzentil zu berechnen (Ordnungsstatistik) einen Datensatz, um Ausreißer zu entfernen, bevor die weitere Verarbeitung. Ich mache zur Zeit so durch die Anordnung von Werten Sortieren und das entsprechende Element Kommissionierung; Das ist machbar, aber es ist ein noticable Blip auf den Profilen trotz ein recht geringer Teil des Programms sein.
Weitere Informationen:
- Der Datensatz enthält in der Größenordnung von bis zu 100000 Gleitkommazahlen und angenommen „vernünftig“ verteilt zu sein - es gibt kaum Duplikate noch große Spitzen in der Dichte in der Nähe von bestimmten Werten sein; und wenn aus irgendeinem Grunde die Verteilung ungerade ist, es ist in Ordnung für eine Annäherung an weniger genau, da die Daten wahrscheinlich verkorkst sind sowieso und weitere zweifelhafte Verarbeitung. Jedoch sind die Daten nicht notwendigerweise gleichmäßig oder normal verteilt; es ist nur sehr unwahrscheinlich degeneriert sein.
- Eine annähernde Lösung wäre in Ordnung, aber ich tun müssen verstehen, wie die Annäherung einleitet Fehler ist es gültig zu gewährleisten.
- Da das Ziel Ausreißer zu entfernen ist, ich bin Rechen zwei Perzentile über die gleichen Daten zu allen Zeiten: z eine bei 95% und einem um 5%.
- Die Anwendung ist in C # mit Bits Heben schwerer Lasten in C ++; Pseudo-Code oder eine bereits existierende Bibliothek in entweder wäre in Ordnung.
- Eine ganz andere Art und Weise Ausreißer zu entfernen, auch in Ordnung wäre, solange es vernünftig ist.
- Update: Es scheint, ich bin für eine ungefähre Auswahlalgorithmus .
Obwohl dies alles in einer Schleife durchgeführt wird, werden die Daten (leicht) jedes Mal anders, so ist es nicht einfach, eine Datenstruktur zur Wiederverwendung als getan wurde für diese Frage .
implementierte Lösung
Mit der wikipedia Auswahlalgorithmus, wie durch Gronim vorgeschlagen reduzierte diesen Teil der Laufzeit um etwa einen Faktor 20.
Da ich nicht eine C # -Implementierung finden könnte, hier ist, was ich kam mit. Es ist schneller, auch für kleine Eingänge als Array.Sort; und bei 1000 Elementen ist es 25-mal schneller.
public static double QuickSelect(double[] list, int k) {
return QuickSelect(list, k, 0, list.Length);
}
public static double QuickSelect(double[] list, int k, int startI, int endI) {
while (true) {
// Assume startI <= k < endI
int pivotI = (startI + endI) / 2; //arbitrary, but good if sorted
int splitI = partition(list, startI, endI, pivotI);
if (k < splitI)
endI = splitI;
else if (k > splitI)
startI = splitI + 1;
else //if (k == splitI)
return list[k];
}
//when this returns, all elements of list[i] <= list[k] iif i <= k
}
static int partition(double[] list, int startI, int endI, int pivotI) {
double pivotValue = list[pivotI];
list[pivotI] = list[startI];
list[startI] = pivotValue;
int storeI = startI + 1;//no need to store @ pivot item, it's good already.
//Invariant: startI < storeI <= endI
while (storeI < endI && list[storeI] <= pivotValue) ++storeI; //fast if sorted
//now storeI == endI || list[storeI] > pivotValue
//so elem @storeI is either irrelevant or too large.
for (int i = storeI + 1; i < endI; ++i)
if (list[i] <= pivotValue) {
list.swap_elems(i, storeI);
++storeI;
}
int newPivotI = storeI - 1;
list[startI] = list[newPivotI];
list[newPivotI] = pivotValue;
//now [startI, newPivotI] are <= to pivotValue && list[newPivotI] == pivotValue.
return newPivotI;
}
static void swap_elems(this double[] list, int i, int j) {
double tmp = list[i];
list[i] = list[j];
list[j] = tmp;
}
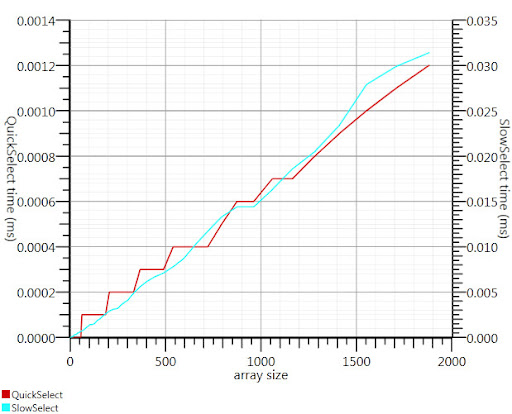
Danke, Gronim, für den Hinweis mich in der richtigen Richtung!
Lösung
Das Histogramm Lösung von Henrik arbeiten. Sie können auch eine Auswahl-Algorithmus, um effizient die k finden größte oder kleinste Elemente in einem Array von n Elementen in O (n) verwenden. Um dies zu verwenden für die 95. Perzentil Satz k = 0,05 N und die k größte Elemente finden.
Referenz:
http://en.wikipedia.org/wiki/Selection_algorithm#Selecting_k_smallest_or_largest_elements
Andere Tipps
Sie können Ihre Perzentile von nur einem Teil des Datensatzes schätzen, wie die ersten paar tausend Punkte.
Die Glivenko-Cantelli Satz Stellt sicher, dass dies wäre ein ziemlich gute Schätzung, wenn Sie Ihre Datenpunkte übernehmen, unabhängig zu sein.
verwendete ich Ausreißer zu identifizieren, indem die Berechnung der Standardabweichung . Alles, was mit einem Abstand von mehr als 2 (oder 3) mal die Standardabweichung von der Durchschnitts ein Ausreißer ist. 2 mal = etwa 95%.
Da Ihr die avarage kalkulieren, es ist auch sehr einfach, die Standardabweichung zu berechnen, ist sehr schnell.
Sie können auch nur einen Teil Ihrer Daten verwenden, um die Zahlen zu berechnen.
Teilen Sie das Intervall zwischen Minimum und Maximum Ihrer Daten in (sagen wir) 1000 Bins und ein Histogramm berechnen. Dann Teilsumme bauen und sehen, wo sie zum ersten Mal 5000 oder 95000 nicht überschreiten.
Es gibt ein paar grundlegende Ansätze, die ich mir vorstellen kann. Zuerst wird den Bereich berechnen (durch die höchsten und niedrigsten Werte zu finden), Projekt jedes Elements auf ein Perzentil. ((X - Min) / range) und jedes zuwerfen, die als .05 oder höher zu senken bewerten als .95
Die zweite ist der Mittelwert und Standardabweichung zu berechnen. Eine Spanne von 2 Standardabweichungen vom Mittelwert (in beiden Richtungen) wird 95% eines normalverteilten Probenraumes umschließen, was bedeutet, Ihre Ausreißer im würde <2,5 und> 97,5 Perzentile. das Mittel aus einer Reihe Berechnung ist linear, wie der Standard-dev (Quadratwurzel aus der Summe der Differenz eines jedes Elements und das Mittelwert) ist. Dann subtrahiert 2 Sigmas aus dem Mittelwert, und fügen Sie 2 Sigma den Mittelwert, und Sie haben Ihre Ausreißer Grenzen bekommen.
Beide werden in etwa linearer Zeit berechnen; die erste erfordert zwei Durchgänge, die zweite nimmt drei (sobald Sie Ihre Grenzen haben Sie immer noch die Ausreißer verwerfen müssen). Da dies ein listenbasierten Betrieb ist, glaube ich nicht, dass Sie etwas mit logarithmischer oder konstanter Komplexität finden; Weitergehende Leistungsgewinne würde entweder erfordern die Iteration und die Berechnung zu optimieren, oder Fehler Einführung durch die Berechnungen auf einer Teilprobe (etwa jedem dritten Element) durchführt.
Eine gute allgemeine Antwort auf Ihr Problem scheint zu sein, RANSAC .
Bei einem Modell, und einige verrauschten Daten, erholt sich der Algorithmus effizient die Parameter des Modells.
Sie haben ein einfaches Modell wählen, die Ihre Daten zuordnen können. Alles glatt sollte in Ordnung sein. eine Mischung aus einigen Gaußsche sagen zu lassen. RANSAC werden die Parameter des Modells festgelegt und eine Reihe von Inlinern zur gleichen Zeit schätzen. Dann wegzuwerfen, was das Modell nicht richtig passt.
Sie könnten herauszufiltern 2 oder 3 Standardabweichung auch dann, wenn die Daten nicht normal verteilt sind; zumindest wird es in einer konsistenten Art und Weise durchgeführt werden, sollte das wichtig sein.
Wie Sie die Ausreißer entfernen, wird die std dev ändern, können Sie dies in einer Schleife tun könnte, bis die Änderung in std dev ist minimal. Unabhängig davon, ob Sie dies tun, hängt von warum manipulieren Sie die Daten auf diese Weise. Es gibt große Vorbehalte einiger Statistiker Entfernen von Ausreißern. Aber einige Entfernen Sie die Ausreißer zu beweisen, dass die Daten ziemlich normal verteilt.
ist kein Experte, aber mein Gedächtnis schlägt vor:
- , um zu bestimmen Perzentilpunkte genau müssen Sie sortieren und count
- eine Probe aus den Daten zu nehmen und die Berechnung der Prozentwerte klingt wie ein guter Plan für anständige Annäherung wenn Sie eine gute Probe bekommen
- wenn nicht, wie von Henrik vorgeschlagen, können Sie die volle Art vermeiden, wenn Sie die Eimer tun und zählen sie
Ein Satz von Daten von 100k Elementen dauert fast keine Zeit zu sortieren, so dass ich nehme an, Sie haben dies immer wieder tun. Wenn der Datensatz der gleiche Satz nur aktualisiert leicht ist, sind Sie am besten von einem Baum Gebäude (O(N log N)) und dann das Entfernen und Hinzufügen neuer Punkte, wie sie kommen in (O(K log N) wo K ist die Anzahl der Punkte geändert). Ansonsten erwähnt die kth größte Element Lösung bereits gibt Ihnen für jeden Datensatz O(N).
