Veloce Algoritmo per percentili per rimuovere valori anomali di calcolo
 https://stackoverflow.com/questions/3779763
https://stackoverflow.com/questions/3779763
-
04-10-2019 - |
 italiano
italiano english
english français
français española
española 中国
中国 日本の
日本の العربية
العربية Deutsch
Deutsch 한국어
한국어 Português
Português Russian
RussianDomanda
Ho un programma che ha bisogno di calcolare ripetutamente il percentile approssimativa (statistica d'ordine) di un set di dati al fine di rimuovere i valori anomali prima di ulteriori trasformazioni. Attualmente sto facendo in modo di classificare la matrice di valori e raccogliendo l'elemento appropriato; questo è fattibile, ma è un blip notevole sui profili pur essendo una parte abbastanza minore del programma.
Più informazioni:
- Il set di dati contiene l'ordine di un massimo di 100000 numeri a virgola mobile, e assunto come "ragionevolmente" distribuito - c'è improbabile che siano duplicati, né enormi picchi di densità nei pressi di valori particolari; e se per qualche strana ragione la distribuzione è strana, è ok per un'approssimazione ad essere meno accurati in quanto i dati sono probabilmente incasinato ogni caso e il successivo trattamento dubbia. Tuttavia, i dati non sono necessariamente uniformemente distribuito o normalmente; è solo molto improbabile che sia degenerata.
- Una soluzione approssimata andrebbe bene, ma ho bisogno di capire come l'errore di approssimazione introduce per assicurarsi che sia valido.
- Poiché l'obiettivo è quello di rimuovere i valori anomali, sto calcolando due percentili oltre gli stessi dati in ogni momento: ad esempio, uno al 95% e uno al 5%.
- L'applicazione è in C # con pezzetti di sollevamento pesante in C ++; pseudocodice o una libreria preesistente in entrambe le andrebbe bene.
- Un modo completamente diverso di rimozione di valori anomali sarebbe troppo bene, a patto che è ragionevole.
- Aggiornamento: Sembra che io sto cercando un approssimativo algoritmo di selezione .
Anche se questo è tutto fatto in un ciclo, i dati sono (leggermente) diverso ogni volta, quindi non è facile da riutilizzare una datastructure come è stato fatto per questa domanda .
implementato la soluzione
Utilizzare l'algoritmo di selezione wikipedia come suggerito da Gronim ridotto questa parte del run-time di circa un fattore 20.
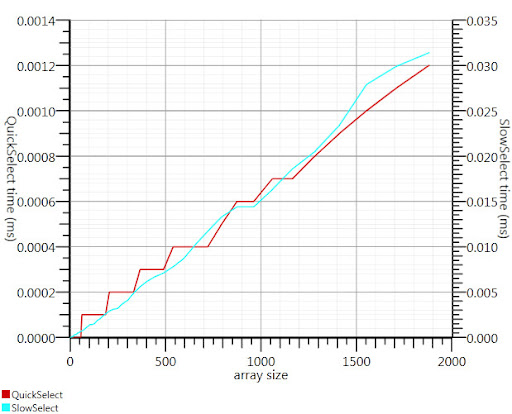
Dato che non riuscivo a trovare un'implementazione C #, ecco cosa mi è venuta. E 'più veloce anche per i piccoli ingressi rispetto Array.Sort; ed a 1000 elementi è 25 volte più veloce.
public static double QuickSelect(double[] list, int k) {
return QuickSelect(list, k, 0, list.Length);
}
public static double QuickSelect(double[] list, int k, int startI, int endI) {
while (true) {
// Assume startI <= k < endI
int pivotI = (startI + endI) / 2; //arbitrary, but good if sorted
int splitI = partition(list, startI, endI, pivotI);
if (k < splitI)
endI = splitI;
else if (k > splitI)
startI = splitI + 1;
else //if (k == splitI)
return list[k];
}
//when this returns, all elements of list[i] <= list[k] iif i <= k
}
static int partition(double[] list, int startI, int endI, int pivotI) {
double pivotValue = list[pivotI];
list[pivotI] = list[startI];
list[startI] = pivotValue;
int storeI = startI + 1;//no need to store @ pivot item, it's good already.
//Invariant: startI < storeI <= endI
while (storeI < endI && list[storeI] <= pivotValue) ++storeI; //fast if sorted
//now storeI == endI || list[storeI] > pivotValue
//so elem @storeI is either irrelevant or too large.
for (int i = storeI + 1; i < endI; ++i)
if (list[i] <= pivotValue) {
list.swap_elems(i, storeI);
++storeI;
}
int newPivotI = storeI - 1;
list[startI] = list[newPivotI];
list[newPivotI] = pivotValue;
//now [startI, newPivotI] are <= to pivotValue && list[newPivotI] == pivotValue.
return newPivotI;
}
static void swap_elems(this double[] list, int i, int j) {
double tmp = list[i];
list[i] = list[j];
list[j] = tmp;
}
Grazie, Gronim, per me che punta nella direzione giusta!
Soluzione
La soluzione istogramma di Henrik funzionerà. È inoltre possibile utilizzare un algoritmo di selezione in modo efficiente trovare il k più grande o più piccoli elementi di un array di n elementi in O (n). Per utilizzare questo per il 95 ° percentile set k = 0,05 N e trovare il k elementi più grandi.
Riferimento:
http://en.wikipedia.org/wiki/Selection_algorithm#Selecting_k_smallest_or_largest_elements
Altri suggerimenti
Si potrebbe valutare il vostro percentili da solo una parte dell'insieme di dati, come i primi mille punti.
Il Glivenko-Cantelli teorema assicura che questo sarebbe un abbastanza buona stima, se si può assumere i punti dati per essere indipendente.
Ho usato per identificare valori anomali calcolando la deviazione standard . Tutto con una distanza più come 2 (o 3) volte la deviazione standard dalla media di marea è un valore anomalo. 2 volte = circa il 95%.
Dal momento che la sta calcolando la media di marea, la sua anche molto facile da calcolare la deviazione standard è molto veloce.
Si potrebbe anche utilizzare solo un sottoinsieme di dati per calcolare i numeri.
Dividere l'intervallo tra minimo e massimo dei dati in (diciamo) 1000 bidoni e calcolare un istogramma. Poi costruire somme parziali e vedere dove superano primo 5000 o 95000.
Ci sono un paio di approcci di base mi vengono in mente. In primo luogo è quello di calcolare la gamma (trovando i valori più alti e più bassi), proiettare ogni elemento ad un percentile. ((X - min) / intervallo) e buttare via qualsiasi che restituiscono inferiore a 0,05 o superiore a 0,95
Il secondo consiste nel calcolare la deviazione media e standard. Un arco di 2 deviazioni standard dalla media (in entrambe le direzioni) racchiuderà il 95% di un campione di spazio normalmente distribuita, il che significa i vostri valori anomali sarebbe nella <2.5 e> 97.5 percentili. Calcolando la media di una serie è lineare, come è il dev standard (radice quadrata della somma della differenza di ciascun elemento e la media). Poi, sottrarre 2 sigma dalla media, e aggiungere 2 sigma alla media, e hai i tuoi limiti di valori anomali.
Entrambi questi calcolerà in tempo più o meno lineare; il primo richiede due passaggi, il secondo prende tre (una volta che hai i tuoi limiti si devono ancora scartare i valori anomali). Dal momento che si tratta di un'operazione di lista, non credo che troverete qualcosa con la complessità logaritmica o costante; ulteriori miglioramenti delle prestazioni richiederebbero ottimizzare sia l'iterazione e calcolo, o introducendo errore eseguendo i calcoli su un sottocampione (ad esempio ogni terzo elemento).
Una buona risposta generale al vostro problema sembra essere RANSAC .
Dato un modello, e alcuni dati rumorosi, l'algoritmo recupera in modo efficiente i parametri del modello.
Si dovrà scegliere un modello semplice che può mappare i dati. Tutto ciò liscio dovrebbe andare bene. Diciamo una miscela di alcuni gaussiane. RANSAC imposterà i parametri del modello e di stimare una serie di pattini in linea allo stesso tempo. Poi buttare via tutto ciò che non rientra il modello corretto.
Si potrebbe filtrare fuori 2 o 3 deviazioni standard, anche se i dati non sono distribuiti normalmente; almeno, sarà fatto in modo coerente, che dovrebbe essere importante.
Come si rimuovono le valori anomali, il dev std cambierà, si potrebbe fare questo in un ciclo fino a quando il cambiamento di dev std è minimo. O se non si vuole fare questo dipende perché stai manipolando i dati in questo modo. Ci sono importanti riserve da parte di alcuni esperti di statistica per la rimozione di valori anomali. Ma alcuni Rimuovere il valori anomali per dimostrare che i dati sono abbastanza distribuiti normalmente.
Non è un esperto, ma la mia memoria suggerisce:
- per determinare percentile punti esattamente è necessario ordinare e count
- prelievo di un campione dai dati e il calcolo dei valori percentili suoni come un piano buono per approssimazione decente se è possibile ottenere un campione di buona
- se non, come suggerito da Henrik, è possibile evitare il completo sorta se fate i secchi e le considero
Una serie di dati di 100k elementi richiede pochissimo tempo per ordinare, quindi suppongo che dovete fare questo più volte. Se l'insieme di dati è lo stesso gruppo ha appena aggiornato un po ', si sta meglio fuori costruzione di un albero (O(N log N)) e poi la rimozione e l'aggiunta di nuovi punti come vengono in (O(K log N) dove K è il numero di punti di cambiata). In caso contrario, la più grande soluzione di kth elemento già accennato dà O(N) per ogni set di dati.
