パーセンタイルを計算するための高速アルゴリズムは、外れ値を除去します
 https://stackoverflow.com/questions/3779763
https://stackoverflow.com/questions/3779763
-
04-10-2019 - |
 italiano
italiano english
english français
français española
española 中国
中国 日本の
日本の العربية
العربية Deutsch
Deutsch 한국어
한국어 Português
Português Russian
Russian質問
さらに処理する前に外れ値を削除するために、データセットのおおよそのパーセンタイル(注文統計)を繰り返し計算する必要があるプログラムがあります。私は現在、値の配列を並べ替えて適切な要素を選ぶことでそうしています。これは実行可能ですが、プログラムのかなり小さな部分であるにもかかわらず、プロファイルの顕著なブリップです。
より詳しい情報:
- データセットには、最大100000の浮動小数点数の順序に含まれており、「合理的に」分布していると想定されています。特定の値に近い密度の重複も巨大なスパイクもありません。ある奇妙な理由で分布が奇妙である場合、データはおそらくとにかく台無しにされ、さらなる処理が疑わしいので、近似がより精度が低下することは問題ありません。ただし、データは必ずしも均一または正規分布ではありません。退化する可能性は非常に低いです。
- おおよそのソリューションは問題ありませんが、私は理解する必要があります どうやって 近似は、それが有効であることを確認するためにエラーを導入します。
- 目的は外れ値を削除することであるため、私は常に同じデータで2つのパーセンタイルを計算しています。たとえば、1つは95%、1つは5%です。
- このアプリは、C ++で重い持ち上げのビットを備えたC#にあります。どちらの擬似コードまたは既存のライブラリでも問題ありません。
- 外れ値を除去するまったく異なる方法は、それが合理的である限り、問題ありません。
- アップデート: おおよそを探しているようです 選択アルゴリズム.
これはすべてループで行われますが、データは毎回(わずかに)異なりますので、行われたようにデータストラクチャを再利用するのは簡単ではありません この質問のために.
実装されたソリューション
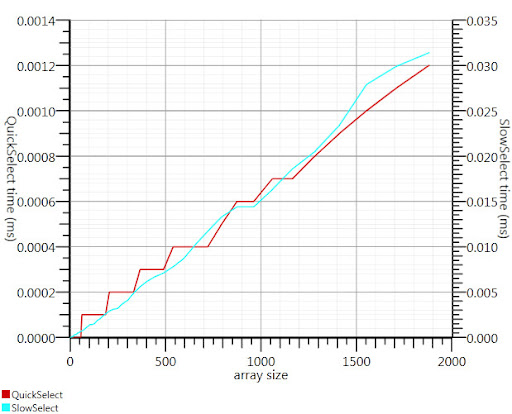
Gronimによって提案されたWikipedia選択アルゴリズムを使用すると、実行時間のこの部分が係数20を約20倍にしました。
C#実装が見つからなかったので、ここに思いついたものがあります。 Array.sortよりも小さな入力でも高速です。 1000の要素では、25倍高速です。
public static double QuickSelect(double[] list, int k) {
return QuickSelect(list, k, 0, list.Length);
}
public static double QuickSelect(double[] list, int k, int startI, int endI) {
while (true) {
// Assume startI <= k < endI
int pivotI = (startI + endI) / 2; //arbitrary, but good if sorted
int splitI = partition(list, startI, endI, pivotI);
if (k < splitI)
endI = splitI;
else if (k > splitI)
startI = splitI + 1;
else //if (k == splitI)
return list[k];
}
//when this returns, all elements of list[i] <= list[k] iif i <= k
}
static int partition(double[] list, int startI, int endI, int pivotI) {
double pivotValue = list[pivotI];
list[pivotI] = list[startI];
list[startI] = pivotValue;
int storeI = startI + 1;//no need to store @ pivot item, it's good already.
//Invariant: startI < storeI <= endI
while (storeI < endI && list[storeI] <= pivotValue) ++storeI; //fast if sorted
//now storeI == endI || list[storeI] > pivotValue
//so elem @storeI is either irrelevant or too large.
for (int i = storeI + 1; i < endI; ++i)
if (list[i] <= pivotValue) {
list.swap_elems(i, storeI);
++storeI;
}
int newPivotI = storeI - 1;
list[startI] = list[newPivotI];
list[newPivotI] = pivotValue;
//now [startI, newPivotI] are <= to pivotValue && list[newPivotI] == pivotValue.
return newPivotI;
}
static void swap_elems(this double[] list, int i, int j) {
double tmp = list[i];
list[i] = list[j];
list[j] = tmp;
}
Gronim、私を正しい方向に向けてくれてありがとう!
解決
Henrikのヒストグラムソリューションが機能します。また、選択アルゴリズムを使用して、O(n)のn要素の配列でk最大または最小の要素を効率的に見つけることもできます。これを95パーセンタイルセットk = 0.05nに使用し、K最大の要素を見つけます。
参照:
http://en.wikipedia.org/wiki/selection_algorithm#selecting_k_smallest_or_largest_elements
他のヒント
最初の数千ポイントのように、データセットの一部からパーセンタイルを見積もることができます。
Glivenko – Cantelli定理 データポイントが独立していると仮定できる場合、これがかなり良い見積もりになることを保証します。
私は、計算することで外れ値を特定していました 標準偏差. 。距離があるすべてのものはすべて、砲撃からの標準偏差の2倍(または3)倍です。 2回=約95%。
あなたは砲撃を計算しているので、標準偏差を計算するのは非常に簡単です。
データのサブセットのみを使用して、数値を計算することもできます。
データの最小値と最大値の間隔を(たとえば)1000ビンに分割し、ヒストグラムを計算します。次に、部分的な合計を作成し、最初に5000または95000を超える場所を確認します。
私が考えることができるいくつかの基本的なアプローチがあります。最初に(最高値と最低値を見つけることにより)範囲を計算し、各要素をパーセンタイル((x -min) /範囲)に投影し、0.05以下より低いものを.95より低いものに捨てることです。
2つ目は、平均と標準偏差を計算することです。平均からの2つの標準偏差(両方の方向)のスパンは、通常分散したサンプルスペースの95%を囲みます。つまり、外れ値は<2.5および> 97.5パーセンタイルになります。標準開発(各要素の差の合計と平均の合計の平方根)と同様に、シリーズの平均を計算することは線形です。次に、平均から2つのシグマを差し引き、平均に2つのシグマを追加すると、外れ値の制限があります。
これらは両方とも、ほぼ直線的な時間で計算されます。 1つ目は2つのパスが必要です。2番目のパスは3回かかります(制限があると、外れ値を破棄する必要があります)。これはリストベースの操作であるため、対数または一定の複雑さを備えたものは何も見つからないと思います。さらなるパフォーマンスの向上は、サブサンプル(3つの要素ごとなど)で計算を実行することにより、反復と計算を最適化するか、エラーを導入する必要があります。
あなたの問題に対する良い一般的な答えは ランサック。モデルといくつかの騒々しいデータが与えられた場合、アルゴリズムはモデルのパラメーターを効率的に回復します。
データをマップできる簡単なモデルを選択する必要があります。スムーズなものは何でも大丈夫です。少数のガウスの混合物を言ってみましょう。 RANSACはモデルのパラメーターを設定し、同時に一連のインライナーを推定します。その後、モデルに適切に適合しないものは何でも捨てます。
データが正規分布していない場合でも、2または3の標準偏差をフィルタリングできます。少なくとも、それは一貫した方法で行われますが、それは重要です。
外れ値を削除すると、STD開発者が変更されます。STD開発者の変更が最小限になるまで、これをループで実行できます。これを行いたいかどうかは、なぜこのようにデータを操作するのかによって異なります。一部の統計学者による外れ値を除去するための大きな留保があります。しかし、一部の人は外れ値を削除して、データがかなり正常に分散されていることを証明します。
専門家ではありませんが、私の記憶は次のように提案しています。
- パーセンタイルポイントを正確に判断するには、ソートしてカウントする必要があります
- データからサンプルを取得し、パーセンタイル値を計算することは、良いサンプルを取得できる場合、適切な近似の良い計画のように聞こえます
- そうでない場合は、ヘンリックが示唆しているように、バケツを行い、数えれば完全な種類を避けることができます
100kの要素のデータの1つのセットは、ソートするのにほとんど時間がかからないので、これを繰り返し行わなければならないと思います。データセットがわずかに更新されたのと同じセットの場合、ツリーを構築するのが最善です(O(N log N))そして、新しいポイントが入ったときに削除して追加します(O(K log N) どこ K ポイントの数は変更されています)。それ以外の場合、 kすでに述べた最大の要素ソリューションはあなたに与えます O(N) 各データセットに対して。
