Быстрый алгоритм для вычисления процентов для удаления выбросов
 https://stackoverflow.com/questions/3779763
https://stackoverflow.com/questions/3779763
-
04-10-2019 - |
 italiano
italiano english
english français
français española
española 中国
中国 日本の
日本の العربية
العربية Deutsch
Deutsch 한국어
한국어 Português
Português Russian
RussianВопрос
У меня есть программа, которая должна неоднократно вычислять приблизительный процентильный (статистика заказа) набора данных, чтобы удалить выбросы перед дальнейшей обработкой. В настоящее время я делаю это, сортировка массива ценностей и выбирая соответствующий элемент; Это выполнимо, но это заметное сотрясение на профилях, несмотря на то, что она довольно незначительная часть программы.
Больше информации:
- Набор данных содержит порядка до 100000 номеров плавающих точек и предполагается, что «разумно» распределены - вряд ли будут дублироваться ни огромные шипы в плотности вблизи конкретных значений; И если по какой-то странной причине распределение нечетное, для приближения в порядке, чтобы быть менее точным, поскольку данные, вероятно, воинствуют и дальнейшая обработка сомнительны. Однако данные не обязательно равномерно или обычно распространяются; Это просто очень вряд ли будет вырожденным.
- Приближенное решение было бы в порядке, но мне нужно понимать как Аппроксимация вводит ошибку, чтобы гарантировать, что она действительна.
- Поскольку цель состоит в том, чтобы удалить выбросы, я вычисляю два процента на одни и те же данные во все время: например, один на 95% и один на 5%.
- Приложение находится в C # с битами тяжелой подъема в C ++; псевдокод или прелестительная библиотека либо в порядке.
- Полностью другой способ удаления выбросов будет в порядке, пока это разумно.
- Обновлять: Похоже, я ищу приблизительный Алгоритм выбора.
Хотя это все готово в цикле, данные (слегка) отличаются каждый раз, поэтому нелегко повторно использовать Datastructure, как было сделано Для этого вопроса.
Реализованное решение
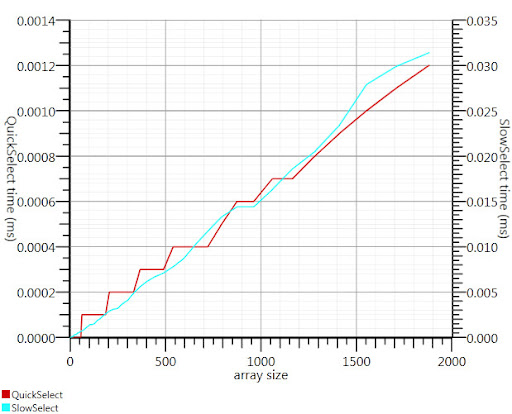
Использование алгоритма выбора Wikipedia, как предложено Gronim, уменьшило эту часть выполнения примерно на 20-фактор.
Поскольку я не мог найти реализацию C #, вот что я придумал. Это быстрее даже для небольших входов, чем array.sort; А на 1000 элементов это в 25 раз быстрее.
public static double QuickSelect(double[] list, int k) {
return QuickSelect(list, k, 0, list.Length);
}
public static double QuickSelect(double[] list, int k, int startI, int endI) {
while (true) {
// Assume startI <= k < endI
int pivotI = (startI + endI) / 2; //arbitrary, but good if sorted
int splitI = partition(list, startI, endI, pivotI);
if (k < splitI)
endI = splitI;
else if (k > splitI)
startI = splitI + 1;
else //if (k == splitI)
return list[k];
}
//when this returns, all elements of list[i] <= list[k] iif i <= k
}
static int partition(double[] list, int startI, int endI, int pivotI) {
double pivotValue = list[pivotI];
list[pivotI] = list[startI];
list[startI] = pivotValue;
int storeI = startI + 1;//no need to store @ pivot item, it's good already.
//Invariant: startI < storeI <= endI
while (storeI < endI && list[storeI] <= pivotValue) ++storeI; //fast if sorted
//now storeI == endI || list[storeI] > pivotValue
//so elem @storeI is either irrelevant or too large.
for (int i = storeI + 1; i < endI; ++i)
if (list[i] <= pivotValue) {
list.swap_elems(i, storeI);
++storeI;
}
int newPivotI = storeI - 1;
list[startI] = list[newPivotI];
list[newPivotI] = pivotValue;
//now [startI, newPivotI] are <= to pivotValue && list[newPivotI] == pivotValue.
return newPivotI;
}
static void swap_elems(this double[] list, int i, int j) {
double tmp = list[i];
list[i] = list[j];
list[j] = tmp;
}
Спасибо, Гроним, за то, что указываю на меня в правильном направлении!
Решение
Решение гистограммы от Хенрика будет работать. Вы также можете использовать алгоритм выбора для эффективного поиска K крупнейших или наименьших элементов k в массиве n элементов o (n). Чтобы использовать это для 95-го процентиля набора k = 0,05n и найдите k крупнейших элементов.
Ссылка:
http://en.wikipedia.org/wiki/selection_algorithm#slecting_k_smallest_or_largest_elements.
Другие советы
Вы можете оценить ваши проценты только из части вашего набора данных, как первые несколько тысяч очков.
То Теорема Гливенко-Кантилелли гарантирует, что это будет довольно хорошая оценка, если вы можете предположить, что ваши данные оказываются независимыми.
Я использовал для выделения выбросов путем расчета среднеквадратичное отклонение. Отказ Все, что с расстоянием более 2 (или 3) раз. Стандартное отклонение от достигающего доклада. 2 раза = около 95%.
Поскольку ваши вычисляют достигающуюся, его также очень легко рассчитать стандартное отклонение очень быстро.
Вы также можете использовать только подмножество ваших данных для расчета чисел.
Разделите интервал между минимальным и максимум ваших данных в (скажем) 1000 банок и рассчитайте гистограмму. Затем постройте частичные суммы и посмотрите, где они впервые превышают 5000 или 95000.
Есть пара основных подходов, о которых я могу думать. Во-первых, состоит в том, чтобы вычислить диапазон (путем нахождения самых высоких и самых низких значений), проецируйте каждый элемент до процентиля ((x - min) / диапазона) и выбросьте любые, которые оценивают более 0,05 или выше .95.
Во-вторых - вычислять среднее и стандартное отклонение. Промежуток из 2 стандартных отклонений от среднего (в обоих направлениях) приведет к 95% от нормально распределенного пространства образца, что означает, что ваши выбросы будут в процентах <2,5 и> 97,5. Расчет среднего значения серии является линейным, как и стандартный разработчик (квадратный корень от суммы разницы каждого элемента и среднего). Затем вычитайте 2 сигма со средним, и добавьте 2 сигма в среднем, и у вас есть свои пределы выбросов.
Оба этого будут вычисления примерно в примерно линейном времени; Первым требуется два прохода, второй берет три (после того, как у вас есть свои ограничения, вы все еще должны отказаться от выбросов). Поскольку это операция на основе списка, я не думаю, что вы найдете что-либо с логарифмической или постоянной сложностью; Любые дальнейшие повышения производительности потребуют либо оптимизацию итерации и расчета, либо внедряя ошибку, выполнив расчеты на подпровизе (например, каждый третий элемент).
Хороший общий ответ на вашу проблему, кажется, Ransac.Отказ Учитывая модель и некоторые шумные данные, алгоритм эффективно восстанавливает параметры модели.
Вам придется выбрать простую модель, которая может отображать ваши данные. Что-нибудь гладкое должно быть в порядке. Пусть скажу смесь нескольких гауссов. RANSAC установит параметры вашей модели и оценивает набор иннедельцев одновременно. Затем выбросьте все, что не подходит для модели правильно.
Вы можете отфильтровать 2 или 3 стандартного отклонения, даже если данные обычно не распространяются; По крайней мере, это будет сделано последовательным образом, что должно быть важно.
Когда вы удаляете выбросы, STD Dev изменится, вы можете сделать это в цикле, пока изменение в STD Dev не минимально. Независимо от того, хотите ли вы, это зависит от того, почему вы управляете данными таким образом. Есть основные оговорки некоторыми статистиками для удаления выбросов. Но некоторые удаляют выбросы, чтобы доказать, что данные довольно распространяются.
Не эксперт, но моя память предлагает:
- Чтобы определить точки процентных точек, которые именно вам нужно сортировать и подсчитать
- Принимая образец из данных и расчет процентных значений звучит как хороший план для приличного приближения, если вы можете получить хороший образец
- Если нет, как предложено Henrik, вы можете избежать полного рода, если вы делаете ведра и посчитаете их
Один набор данных элементов 100K не занимает некоторое время, поэтому я предполагаю, что вы должны сделать это неоднократно. Если набор данных тот же набор, просто обновляемый слегка, вы лучше отказываются от строительства дерева (O(N log N)) а затем удаление и добавление новых моментов, как они входят (O(K log N) куда K это количество точек изменено). В противном случае то kКоличество крупнейших элементов решения уже упомянуты, дает вам O(N) для каждого набора данных.
