Warten Sie bash Hintergrundjobs in Skript fertig gestellt werden
 https://stackoverflow.com/questions/1131484
https://stackoverflow.com/questions/1131484
-
16-09-2019 - |
 italiano
italiano english
english français
français española
española 中国
中国 日本の
日本の العربية
العربية Deutsch
Deutsch 한국어
한국어 Português
Português Russian
RussianFrage
Um die CPU-Auslastung (I laufen die Dinge auf einem Debian Lenny in EC2) Ich habe ein einfaches Skript starten Aufträge parallel zu maximieren:
#!/bin/bash
for i in apache-200901*.log; do echo "Processing $i ..."; do_something_important; done &
for i in apache-200902*.log; do echo "Processing $i ..."; do_something_important; done &
for i in apache-200903*.log; do echo "Processing $i ..."; do_something_important; done &
for i in apache-200904*.log; do echo "Processing $i ..."; do_something_important; done &
...
Ich bin ganz mit dieser Arbeitslösung zufrieden, aber ich konnte nicht herausfinden, wie weiter Code zu schreiben, die alle Schleifen ausgeführt nur einmal abgeschlossen war.
Gibt es eine Möglichkeit der Kontrolle über diese zu bekommen?
Lösung
Es gibt eine bash für diesen Befehl builtin.
wait [n ...]
Wait for each specified process and return its termination sta‐
tus. Each n may be a process ID or a job specification; if a
job spec is given, all processes in that job’s pipeline are
waited for. If n is not given, all currently active child pro‐
cesses are waited for, and the return status is zero. If n
specifies a non-existent process or job, the return status is
127. Otherwise, the return status is the exit status of the
last process or job waited for.
Andere Tipps
GNU Parallel wird Ihren Skript noch kürzer und möglicherweise effizienter machen:
parallel 'echo "Processing "{}" ..."; do_something_important {}' ::: apache-*.log
Dies wird einen Job pro CPU-Kern läuft und weiterhin tun, bis alle Dateien verarbeitet werden.
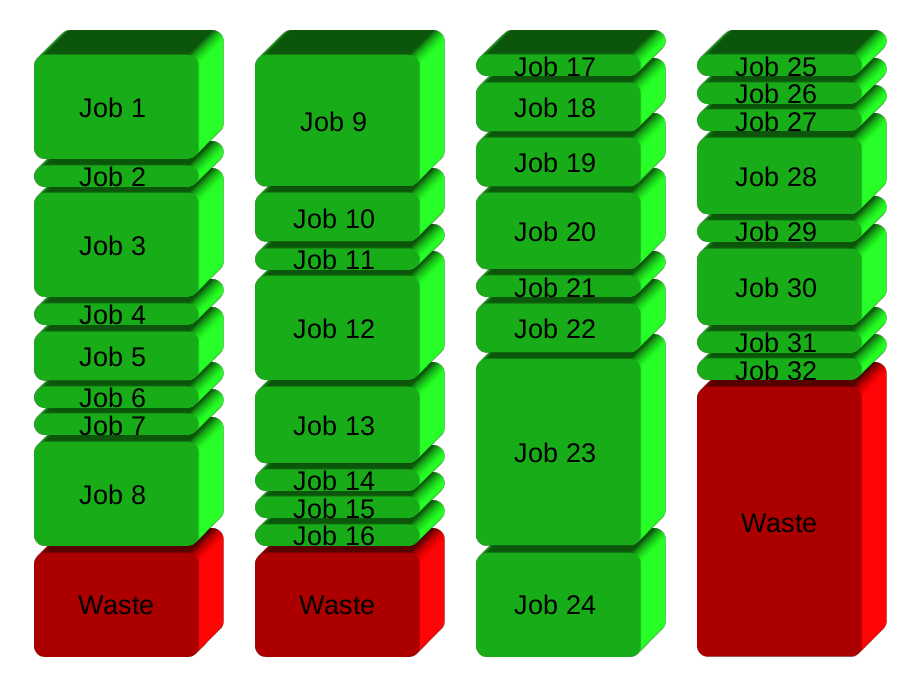
Ihre Lösung wird geteilt grundsätzlich die Arbeitsplätze in Gruppen vor der Ausführung. Hier 32 Arbeitsplätze in 4 Gruppen:
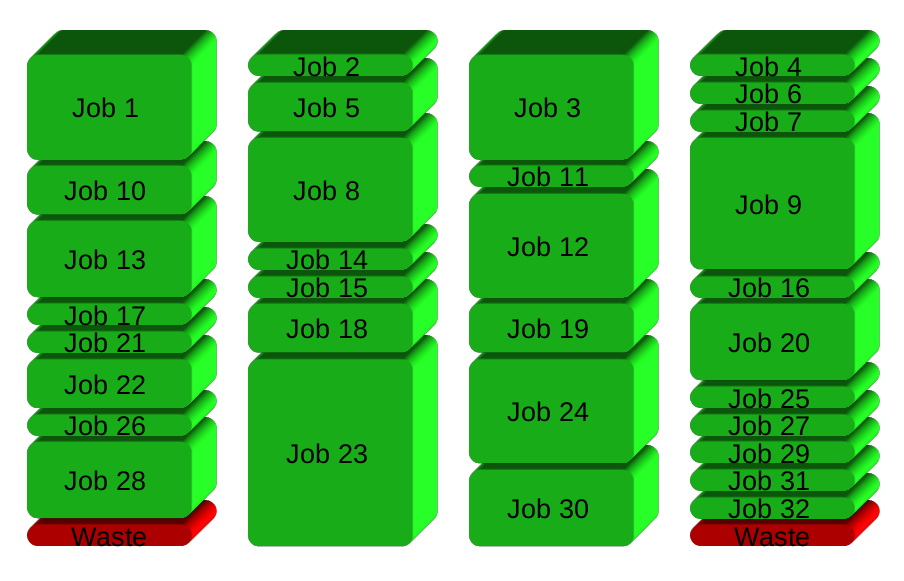
GNU Parallel laicht stattdessen einen neuen Prozess, wenn man beendet - hält die CPUs aktiv und damit Zeitersparnis:
Um mehr zu erfahren:
- Sehen Sie sich das Intro-Video für eine schnelle Einführung: https://www.youtube.com/playlist?list=PL284C9FF2488BC6D1
- Gehen Sie durch das Tutorial (Mann parallel_tutorial). Sie Befehlszeile werden Sie dafür lieben.
Ich hatte das vor kurzem zu tun und mit der folgenden Lösung endete:
while true; do
wait -n || {
code="$?"
([[ $code = "127" ]] && exit 0 || exit "$code")
break
}
done;
Hier ist, wie es funktioniert:
wait -n Exits, sobald eine der (potenziell viele) Hintergrundjobs beendet. Es ergibt immer wahr, und die Schleife geht weiter, bis:
- Exit-Code
127: der letzte Hintergrundjob erfolgreich beendet. Im Dieser Fall, ignorieren wir die Exit-Code und zum Verlassen des Unterschale mit Code 0. - Jede des Hintergrundjobs fehlgeschlagen. Wir verlassen gerade die Unterschale mit dem Exit-Code.
Mit set -e, das garantiert, dass das Skript vorzeitig beendet wird und den Exit-Code eines gescheiterten Hintergrundjobs durchlaufen.
Das ist meine rohe Lösung:
function run_task {
cmd=$1
output=$2
concurency=$3
if [ -f ${output}.done ]; then
# experiment already run
echo "Command already run: $cmd. Found output $output"
return
fi
count=`jobs -p | wc -l`
echo "New active task #$count: $cmd > $output"
$cmd > $output && touch $output.done &
stop=$(($count >= $concurency))
while [ $stop -eq 1 ]; do
echo "Waiting for $count worker threads..."
sleep 1
count=`jobs -p | wc -l`
stop=$(($count > $concurency))
done
}
Die Idee ist, „Jobs“, um zu sehen, wie viele Kinder sind aktiv im Hintergrund und warten, bis diese Zahl fällt (ein Kind Exits) zu verwenden. Sobald ein Kind vorhanden ist, kann die nächste Aufgabe gestartet werden.
Wie Sie sehen können, gibt es auch ein paar zusätzliche Logik ist es, die gleichen Experimente / Befehle mehrere Male zu vermeiden läuft. Es ist der Job für mich .. Allerdings könnte diese Logik entweder ausgelassen oder weiter verbessert (zum Beispiel prüft Dateierstellung Zeitstempel, Eingabeparameter, usw.).
