Attendere bash processi in background in uno script per essere finito
 https://stackoverflow.com/questions/1131484
https://stackoverflow.com/questions/1131484
-
16-09-2019 - |
 italiano
italiano english
english français
français española
española 中国
中国 日本の
日本の العربية
العربية Deutsch
Deutsch 한국어
한국어 Português
Português Russian
RussianDomanda
Per ottimizzare l'utilizzo della CPU (ho eseguito le cose su una Debian Lenny in EC2) ho un semplice script per avviare i lavori in parallelo:
#!/bin/bash
for i in apache-200901*.log; do echo "Processing $i ..."; do_something_important; done &
for i in apache-200902*.log; do echo "Processing $i ..."; do_something_important; done &
for i in apache-200903*.log; do echo "Processing $i ..."; do_something_important; done &
for i in apache-200904*.log; do echo "Processing $i ..."; do_something_important; done &
...
Sono abbastanza soddisfatto di questa soluzione, tuttavia, non riuscivo a capire come scrivere un ulteriore codice che eseguito solo una volta che tutti i loop sono stati completati.
C'è un modo per ottenere il controllo di questo?
Soluzione
C'è un bash comando incorporato per questo.
wait [n ...]
Wait for each specified process and return its termination sta‐
tus. Each n may be a process ID or a job specification; if a
job spec is given, all processes in that job’s pipeline are
waited for. If n is not given, all currently active child pro‐
cesses are waited for, and the return status is zero. If n
specifies a non-existent process or job, the return status is
127. Otherwise, the return status is the exit status of the
last process or job waited for.
Altri suggerimenti
Utilizzando GNU parallelo renderà il vostro script ancora più breve e forse più efficace:
parallel 'echo "Processing "{}" ..."; do_something_important {}' ::: apache-*.log
Questo verrà eseguito un lavoro per core della CPU e continuare a farlo fino a quando tutti i file vengono elaborati.
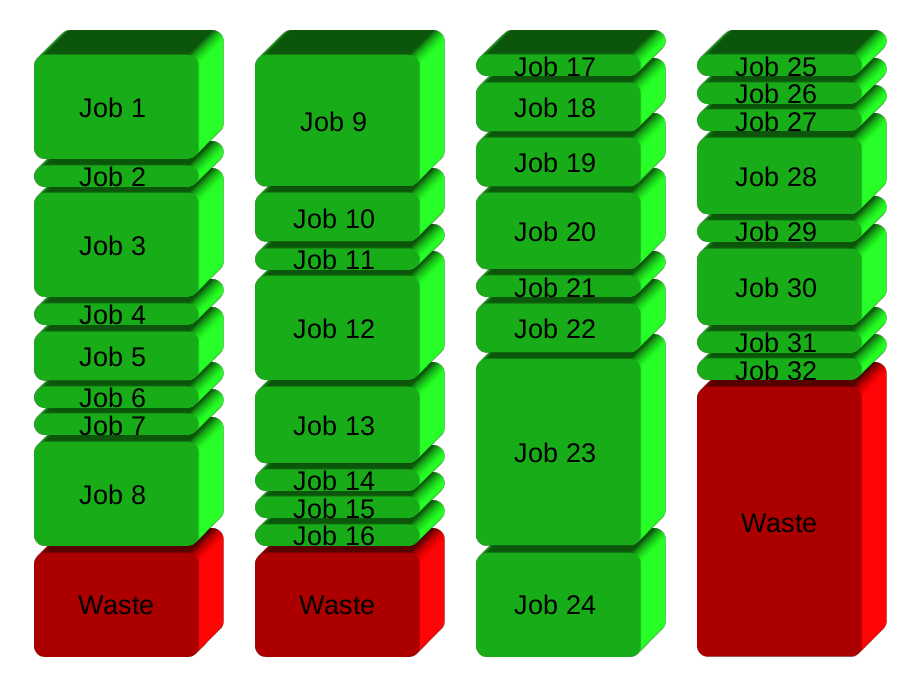
La soluzione sarà essenzialmente suddividere i lavori in gruppi prima di eseguire. Qui 32 posti di lavoro in 4 gruppi:
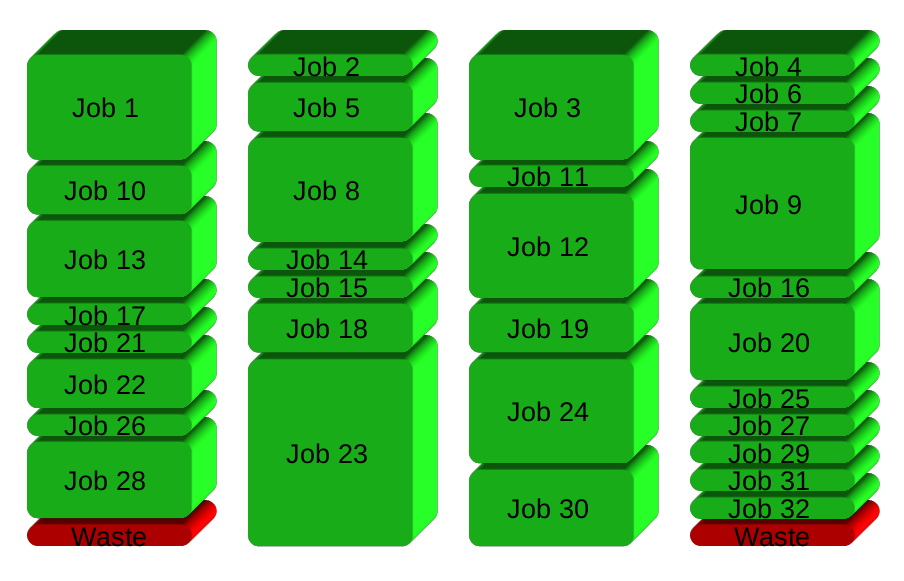
GNU parallela genera invece un nuovo processo quando si finisce - mantenendo la CPU attiva e risparmiando tempo:
Per saperne di più:
- Guarda il video introduttivo per una breve introduzione: https://www.youtube.com/playlist?list=PL284C9FF2488BC6D1
- Passeggiata attraverso il tutorial (uomo parallel_tutorial). È riga di comando ti amerà per esso.
Ho dovuto fare questo di recente e si è conclusa con la seguente soluzione:
while true; do
wait -n || {
code="$?"
([[ $code = "127" ]] && exit 0 || exit "$code")
break
}
done;
Ecco come funziona:
uscite wait -n non appena uno dei (molti) potenzialmente processi in background uscite. Si restituisce sempre true e il ciclo va avanti fino a:
- Codice di uscita
127: l'ultimo processo in background è uscito con successo. Nel questo caso, ignoriamo il codice di uscita e uscire dal sub-shell con codice 0. - Ogni del lavoro in background non riuscita. Abbiamo appena uscire dal sotto-shell con quel codice di uscita.
Con set -e, questo garantirà che lo script terminerà presto e passare attraverso il codice di uscita di qualsiasi processo in background non riuscita.
Questo è il mio grezzo soluzione:
function run_task {
cmd=$1
output=$2
concurency=$3
if [ -f ${output}.done ]; then
# experiment already run
echo "Command already run: $cmd. Found output $output"
return
fi
count=`jobs -p | wc -l`
echo "New active task #$count: $cmd > $output"
$cmd > $output && touch $output.done &
stop=$(($count >= $concurency))
while [ $stop -eq 1 ]; do
echo "Waiting for $count worker threads..."
sleep 1
count=`jobs -p | wc -l`
stop=$(($count > $concurency))
done
}
L'idea è di utilizzare dei "lavori" per vedere quanti bambini sono attivi in background e attendere fino a questo numero di gocce (un bambino esce).Una volta che un bambino esiste, la prossima attività può essere iniziata.
Come si può vedere, c'è anche un po ' di extra logica di evitare l'esecuzione di esperimenti/comandi più volte.Si fa il lavoro per me..Tuttavia, questa logica può essere ignorato o in ulteriore miglioramento (ad esempio, per controllare file timestamp di creazione, i parametri di input, etc.).
