Espere a que los empleos fondo golpe en la secuencia de comandos para ser terminado
 https://stackoverflow.com/questions/1131484
https://stackoverflow.com/questions/1131484
-
16-09-2019 - |
 italiano
italiano english
english français
français española
española 中国
中国 日本の
日本の العربية
العربية Deutsch
Deutsch 한국어
한국어 Português
Português Russian
RussianPregunta
Para maximizar el uso de la CPU (corro cosas en un Debian Lenny en EC2) Tengo un script sencillo para iniciar trabajos en paralelo:
#!/bin/bash
for i in apache-200901*.log; do echo "Processing $i ..."; do_something_important; done &
for i in apache-200902*.log; do echo "Processing $i ..."; do_something_important; done &
for i in apache-200903*.log; do echo "Processing $i ..."; do_something_important; done &
for i in apache-200904*.log; do echo "Processing $i ..."; do_something_important; done &
...
Estoy bastante satisfecho con esta solución de trabajo, sin embargo no podía encontrar la manera de escribir código adicional que sólo se ejecuta una vez que todos los bucles se ha completado.
¿Hay una manera de conseguir el control de esta?
Solución
Hay una bash orden interna para eso.
wait [n ...]
Wait for each specified process and return its termination sta‐
tus. Each n may be a process ID or a job specification; if a
job spec is given, all processes in that job’s pipeline are
waited for. If n is not given, all currently active child pro‐
cesses are waited for, and the return status is zero. If n
specifies a non-existent process or job, the return status is
127. Otherwise, the return status is the exit status of the
last process or job waited for.
Otros consejos
El uso paralelo de GNU hará que su escritura aún más corto y posiblemente más eficiente:
parallel 'echo "Processing "{}" ..."; do_something_important {}' ::: apache-*.log
Esto ejecutará un empleo por cada núcleo de CPU y seguir haciéndolo hasta que todos los archivos se procesan.
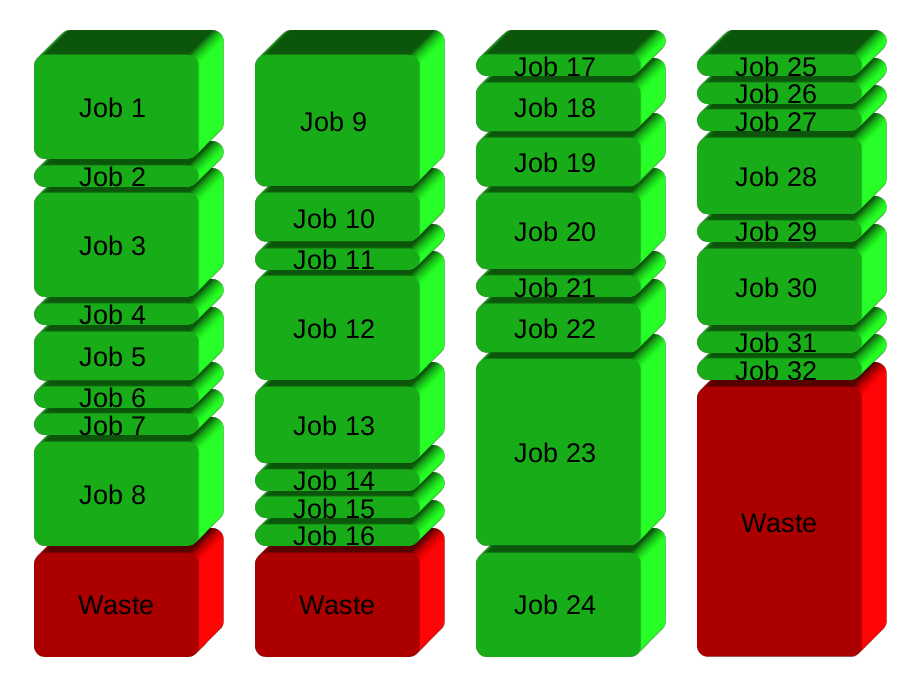
Su solución será básicamente dividir los trabajos en grupos antes de ejecutar. Aquí 32 puestos de trabajo en 4 grupos:
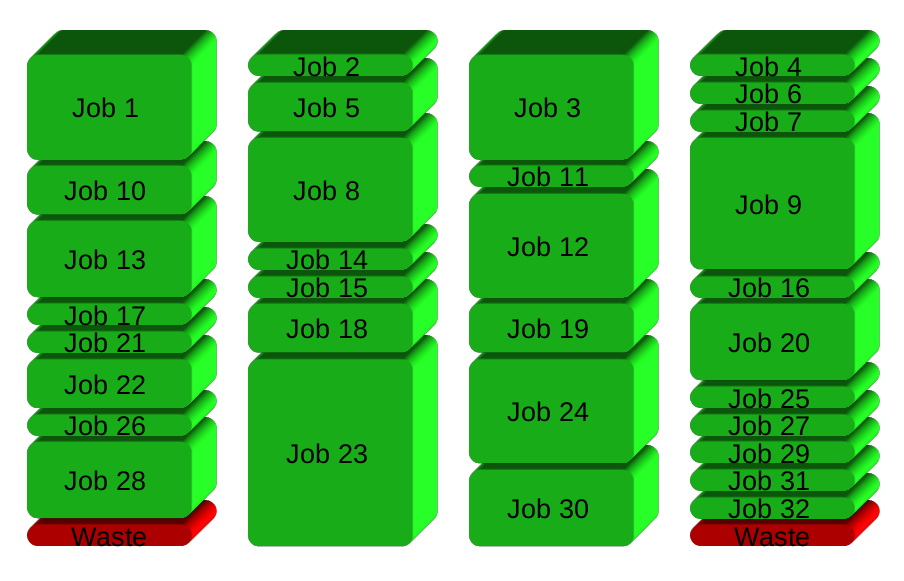
GNU vez genera un nuevo proceso cuando uno termina - mantener la CPU activa y el consiguiente ahorro de tiempo:
Para obtener más información:
- Ver el vídeo de introducción para una introducción rápida: https://www.youtube.com/playlist?list=PL284C9FF2488BC6D1
- Paseo por el tutorial (parallel_tutorial hombre). Te mando línea se lo agradecerá.
que tenía que hacer esto recientemente y terminó con la siguiente solución:
while true; do
wait -n || {
code="$?"
([[ $code = "127" ]] && exit 0 || exit "$code")
break
}
done;
Así es como funciona:
salidas wait -n tan pronto como uno de los muchos (potencialmente) ofertas de trabajo fondo salidas. Siempre se evalúa como verdadera y el bucle continúa hasta que:
- El código de salida
127: el último trabajo en segundo plano salido de forma satisfactoria. En ese caso, ignoramos el código de salida y salir de la sub-shell con código 0. - Cualquiera de los fallidos trabajo en segundo plano. Acabamos de Salida de un sub-shell con ese código de salida.
Con set -e, esto garantizará que el script terminará pronto y pasar por el código de salida de cualquier trabajo en segundo plano fallado.
Esta es mi solución bruta:
function run_task {
cmd=$1
output=$2
concurency=$3
if [ -f ${output}.done ]; then
# experiment already run
echo "Command already run: $cmd. Found output $output"
return
fi
count=`jobs -p | wc -l`
echo "New active task #$count: $cmd > $output"
$cmd > $output && touch $output.done &
stop=$(($count >= $concurency))
while [ $stop -eq 1 ]; do
echo "Waiting for $count worker threads..."
sleep 1
count=`jobs -p | wc -l`
stop=$(($count > $concurency))
done
}
La idea es utilizar "trabajos" para ver cuántos niños están activos en segundo plano y esperar a que este número se reduce (un niño salidas). Una vez que existe un niño, la siguiente tarea se puede iniciar.
Como se puede ver, también hay un poco de lógica adicional para evitar encontrarse con los mismos experimentos / comandos varias veces. Se hace el trabajo para mí .. Sin embargo, esta lógica podría ser omitidos o mejorarse aún más (por ejemplo, la verificación de las marcas de tiempo de creación de archivos, parámetros de entrada, etc.).
