Espere por trabalhos de fundo festa no script para ser concluído
 https://stackoverflow.com/questions/1131484
https://stackoverflow.com/questions/1131484
-
16-09-2019 - |
 italiano
italiano english
english français
français española
española 中国
中国 日本の
日本の العربية
العربية Deutsch
Deutsch 한국어
한국어 Português
Português Russian
RussianPergunta
Para maximizar o uso da CPU (eu executar as coisas em um Lenny Debian no EC2) Eu tenho um script simples para trabalhos de lançamento em paralelo:
#!/bin/bash
for i in apache-200901*.log; do echo "Processing $i ..."; do_something_important; done &
for i in apache-200902*.log; do echo "Processing $i ..."; do_something_important; done &
for i in apache-200903*.log; do echo "Processing $i ..."; do_something_important; done &
for i in apache-200904*.log; do echo "Processing $i ..."; do_something_important; done &
...
Estou bastante satisfeito com esta solução de trabalho, no entanto eu não conseguia descobrir como escrever código adicional que só executado uma vez todos os ciclos foram concluídos.
Existe uma maneira de obter o controle dessa?
Solução
Há uma bash builtin comando para isso.
wait [n ...]
Wait for each specified process and return its termination sta‐
tus. Each n may be a process ID or a job specification; if a
job spec is given, all processes in that job’s pipeline are
waited for. If n is not given, all currently active child pro‐
cesses are waited for, and the return status is zero. If n
specifies a non-existent process or job, the return status is
127. Otherwise, the return status is the exit status of the
last process or job waited for.
Outras dicas
Usando GNU Parallel fará seu script ainda mais curto e, possivelmente, mais eficiente:
parallel 'echo "Processing "{}" ..."; do_something_important {}' ::: apache-*.log
Isto irá executar um trabalho por núcleo de CPU e continuar a fazer isso até que todos os arquivos são processados.
A sua solução será, basicamente, dividir os trabalhos em grupos antes de executar. Aqui 32 postos de trabalho em 4 grupos:
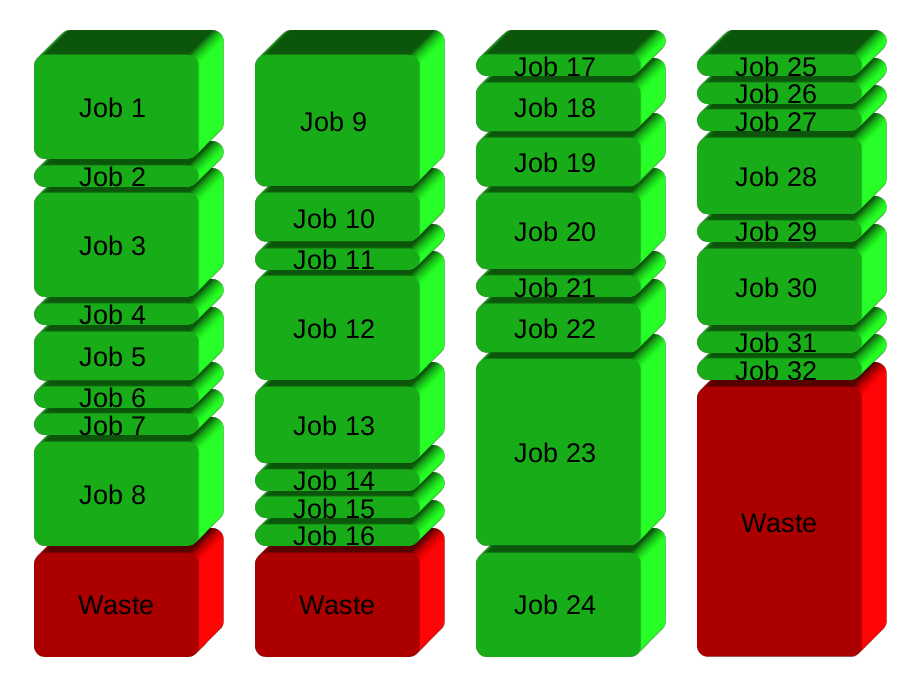
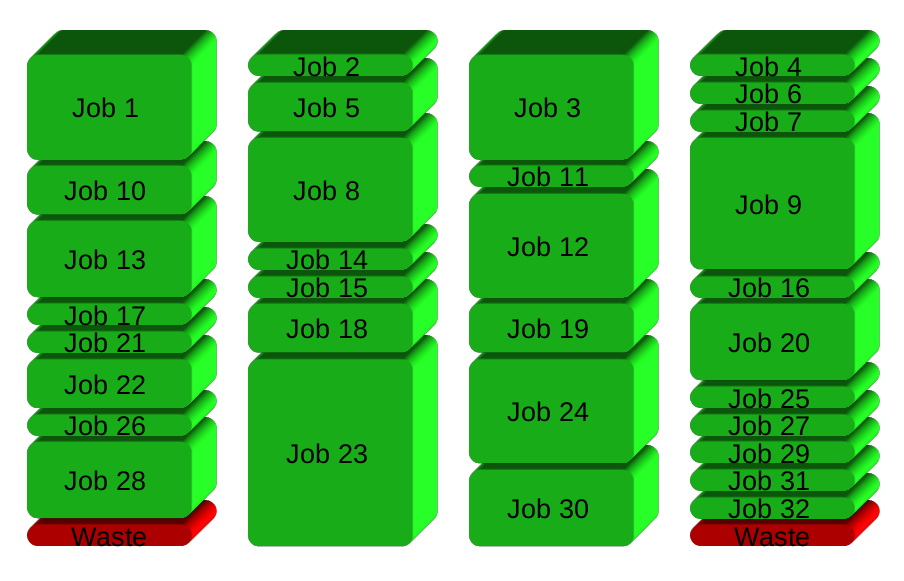
GNU Paralelo vez gera um novo processo quando termina uma - mantendo as CPUs ativo e, portanto, economizando tempo:
Para saber mais:
- Assista ao vídeo de introdução para uma rápida introdução: https://www.youtube.com/playlist?list=PL284C9FF2488BC6D1
- Atravesse o tutorial (homem parallel_tutorial). Você comanda linha vai te amo por isso.
Eu tive que fazer isso recentemente e acabou com a seguinte solução:
while true; do
wait -n || {
code="$?"
([[ $code = "127" ]] && exit 0 || exit "$code")
break
}
done;
Eis como funciona:
saídas wait -n, logo que um dos (potencialmente muitos) trabalhos de fundo saídas. Ele sempre avalia como true e o ciclo continua até que:
-
127Código de saída: o último trabalho de fundo saído com êxito. Dentro Nesse caso, podemos ignorar o código de saída e sair do sub-shell com código 0. - Qualquer do trabalho em segundo plano falhou. Nós apenas sair do sub-shell com que o código de saída.
Com set -e, isso vai garantir que o script terminará cedo e passar pelo código de saída de qualquer trabalho em segundo plano falhou.
Esta é a minha solução bruta:
function run_task {
cmd=$1
output=$2
concurency=$3
if [ -f ${output}.done ]; then
# experiment already run
echo "Command already run: $cmd. Found output $output"
return
fi
count=`jobs -p | wc -l`
echo "New active task #$count: $cmd > $output"
$cmd > $output && touch $output.done &
stop=$(($count >= $concurency))
while [ $stop -eq 1 ]; do
echo "Waiting for $count worker threads..."
sleep 1
count=`jobs -p | wc -l`
stop=$(($count > $concurency))
done
}
A idéia é usar "empregos" para ver quantas crianças estão ativos em segundo plano e esperar até este gotas numéricas (uma criança saídas). Uma vez que existe uma criança, a próxima tarefa pode ser iniciado.
Como você pode ver, há também um pouco de lógica extra para evitar correr os mesmos experimentos / comandos várias vezes. Ele faz o trabalho para mim .. No entanto, esta lógica poderia ser ou ignorada ou melhorada (por exemplo, verificação de data e hora de criação de arquivo, parâmetros de entrada, etc.).
