Attendez travaux d'arrière-plan dans le script bash à finir
 https://stackoverflow.com/questions/1131484
https://stackoverflow.com/questions/1131484
-
16-09-2019 - |
 italiano
italiano english
english français
français española
española 中国
中国 日本の
日本の العربية
العربية Deutsch
Deutsch 한국어
한국어 Português
Português Russian
RussianQuestion
Afin de maximiser l'utilisation du processeur (je lance des choses sur une Debian Lenny dans EC2) J'ai un script simple pour lancer des travaux en parallèle:
#!/bin/bash
for i in apache-200901*.log; do echo "Processing $i ..."; do_something_important; done &
for i in apache-200902*.log; do echo "Processing $i ..."; do_something_important; done &
for i in apache-200903*.log; do echo "Processing $i ..."; do_something_important; done &
for i in apache-200904*.log; do echo "Processing $i ..."; do_something_important; done &
...
Je suis tout à fait satisfait de cette solution de travail, mais je ne pouvais pas comprendre comment écrire du code supplémentaire qui n'exécuté une fois que toutes les boucles ont été complétées.
Est-il possible d'obtenir le contrôle de cette situation?
La solution
Il y a une commande builtin bash pour cela.
wait [n ...]
Wait for each specified process and return its termination sta‐
tus. Each n may be a process ID or a job specification; if a
job spec is given, all processes in that job’s pipeline are
waited for. If n is not given, all currently active child pro‐
cesses are waited for, and the return status is zero. If n
specifies a non-existent process or job, the return status is
127. Otherwise, the return status is the exit status of the
last process or job waited for.
Autres conseils
Utilisation parallèle GNU fera votre script encore plus court et peut-être plus efficace:
parallel 'echo "Processing "{}" ..."; do_something_important {}' ::: apache-*.log
Ceci lancera un emploi par cœur de CPU et de continuer à le faire jusqu'à ce que tous les fichiers sont traités.
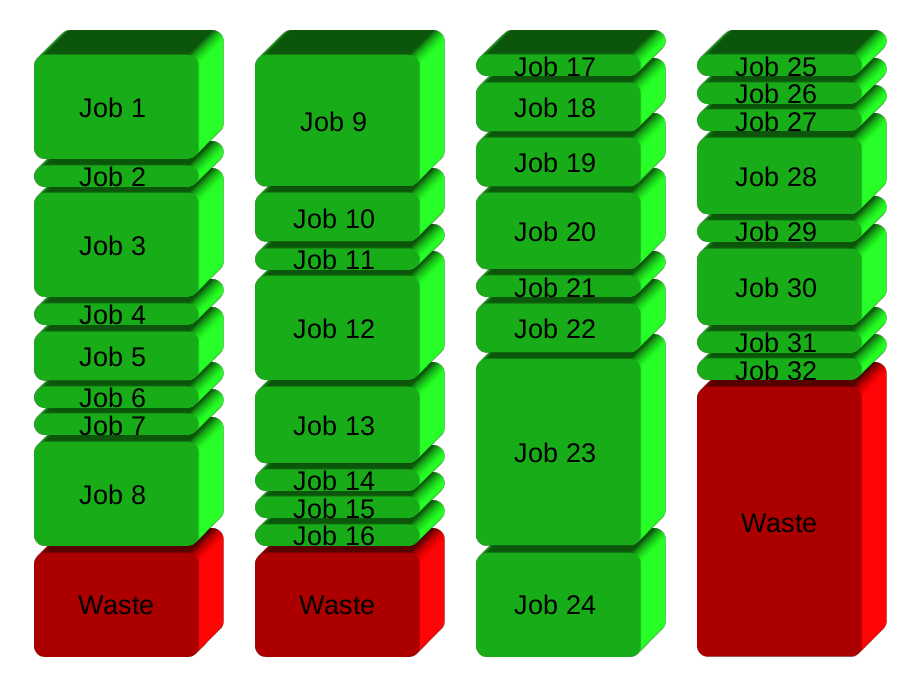
Votre solution sera essentiellement diviser les emplois en groupes avant d'exécuter. Ici 32 emplois en 4 groupes:
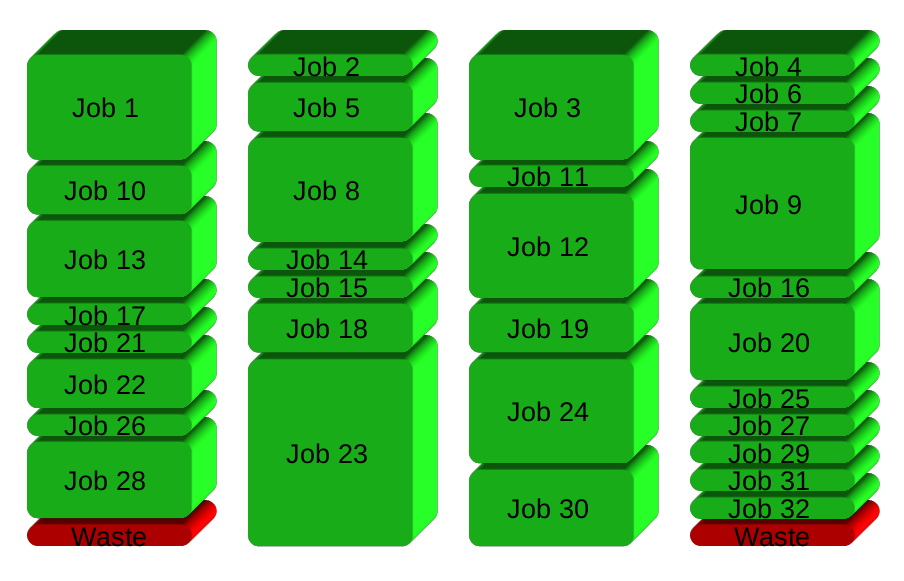
GNU parallèle à la place engendre un nouveau processus quand on termine - en gardant les CPU active et un gain de temps:
Pour en savoir plus:
- Regardez la vidéo d'intro pour une introduction rapide: https://www.youtube.com/playlist?list=PL284C9FF2488BC6D1
- Promenade à travers le tutoriel (homme parallel_tutorial). Vous en ligne de commande vous remerciera.
Je devais le faire récemment et a fini avec la solution suivante:
while true; do
wait -n || {
code="$?"
([[ $code = "127" ]] && exit 0 || exit "$code")
break
}
done;
Voilà comment cela fonctionne:
sorties de wait -n dès que l'une des sorties (potentiellement nombreux) emplois de fond. Il est toujours vraie et la boucle se poursuit jusqu'à:
- Code de sortie
127: le dernier travail de fond est sorti avec succès. Dans ce cas, nous ignorons le code de sortie et de sortie du sous-shell avec le code 0. - Tout du travail de fond a échoué. Nous sortons juste la sous-shell avec ce code de sortie.
Avec set -e, cela garantira que le script prendra fin tôt et passer à travers le code de sortie de tout travail de fond a échoué.
Ceci est ma solution brute:
function run_task {
cmd=$1
output=$2
concurency=$3
if [ -f ${output}.done ]; then
# experiment already run
echo "Command already run: $cmd. Found output $output"
return
fi
count=`jobs -p | wc -l`
echo "New active task #$count: $cmd > $output"
$cmd > $output && touch $output.done &
stop=$(($count >= $concurency))
while [ $stop -eq 1 ]; do
echo "Waiting for $count worker threads..."
sleep 1
count=`jobs -p | wc -l`
stop=$(($count > $concurency))
done
}
L'idée est d'utiliser des « emplois » pour voir combien d'enfants sont actifs dans l'arrière-plan et d'attendre jusqu'à ce que ce nombre tombe (un sort de l'enfant). Une fois qu'un enfant existe, la tâche suivante peut être démarré.
Comme vous pouvez le voir, il y a aussi un peu de logique supplémentaire pour éviter de les mêmes expériences / commandes à plusieurs reprises. Il fait le travail pour moi .. Cependant, cette logique pourrait être soit sautées ou encore amélioré (par exemple, vérifier les horodatages de création de fichiers, paramètres d'entrée, etc.).
