العثور على الحدود القصوى المحلية التقريبية مع البيانات الصاخبة في ماتلاب
 https://stackoverflow.com/questions/842131
https://stackoverflow.com/questions/842131
 italiano
italiano english
english français
français española
española 中国
中国 日本の
日本の العربية
العربية Deutsch
Deutsch 한국어
한국어 Português
Português Russian
Russianسؤال
تصف الأسئلة الشائعة حول MATLAB طريقة من سطر واحد للعثور على الحدود القصوى المحلية:
index = find( diff( sign( diff([0; x(:); 0]) ) ) < 0 );
لكنني أعتقد أن هذا لا ينجح إلا إذا كانت البيانات أكثر أو أقل سلاسة.لنفترض أن لديك بيانات تقفز لأعلى ولأسفل في فترات زمنية صغيرة ولكن لا تزال تحتوي على بعض الحدود القصوى المحلية التقريبية.كيف يمكنك العثور على هذه النقاط؟يمكنك تقسيم المتجه إلى أجزاء n والعثور على القيمة الأكبر ليس على حافة كل منها ولكن يجب أن يكون هناك حل أكثر أناقة وأسرع.
سيكون الحل المكون من سطر واحد رائعًا أيضًا.
يحرر: أنا أعمل مع الصور البيولوجية الصاخبة التي أحاول تقسيمها إلى أقسام متميزة.
المحلول
اعتمادًا على ما تريده، غالبًا ما يكون من المفيد تصفية البيانات المزعجة.نلقي نظرة على ميدفيلت1, ، أو باستخدام التحويل جنبا إلى جنب مع خاص.في الطريقة الأخيرة، قد ترغب في استخدام الوسيطة "نفسها" لـ CONV ومرشح "غاوسي" تم إنشاؤه بواسطة FSPECIAL.
بعد الانتهاء من التصفية، قم بتغذيتها من خلال مكتشف الحد الأقصى.
يحرر: تعقيد وقت التشغيل
لنفترض أن متجه الإدخال له طول X وطول نواة المرشح هو K.
يمكن أن يعمل عامل التصفية المتوسط عن طريق إجراء فرز إدراج قيد التشغيل، لذلك يجب أن يكون O(Xك + ك سجل ك).لم ألقي نظرة على الكود المصدري ومن الممكن تنفيذ تطبيقات أخرى، ولكن في الأساس يجب أن يكون O(Xك).
عندما تكون قيمة K صغيرة، يستخدم التحويل خوارزمية O(X*K) المباشرة.عندما تكون X وK متماثلتين تقريبًا، فمن الأسرع استخدام تحويل فورييه السريع.هذا التنفيذ هو O(X log X + K log K).يعد Matlab ذكيًا بدرجة كافية لاختيار الخوارزمية الصحيحة تلقائيًا اعتمادًا على أحجام الإدخال.
نصائح أخرى
لست متأكدًا من نوع البيانات التي تتعامل معها، ولكن إليك طريقة استخدمتها لمعالجة بيانات الكلام والتي يمكن أن تساعدك في تحديد الحد الأقصى المحلي.ويستخدم ثلاث وظائف من مجموعة أدوات معالجة الإشارة: هيلبرت, سمنة, ، و فلتر.
data = (...the waveform of noisy data...);
Fs = (...the sampling rate of the data...);
[b,a] = butter(5,20/(Fs/2),'low'); % Create a low-pass butterworth filter;
% adjust the values as needed.
smoothData = filtfilt(b,a,abs(hilbert(data))); % Apply a hilbert transform
% and filter the data.
ستقوم بعد ذلك بإجراء اكتشاف الحد الأقصى الخاص بك SmoothData.يؤدي استخدام HILBERT أولاً إلى إنشاء مظروف إيجابي على البيانات، ثم يستخدم FILTFILT معاملات التصفية من BUTTER لتصفية مغلف البيانات بتمرير منخفض.
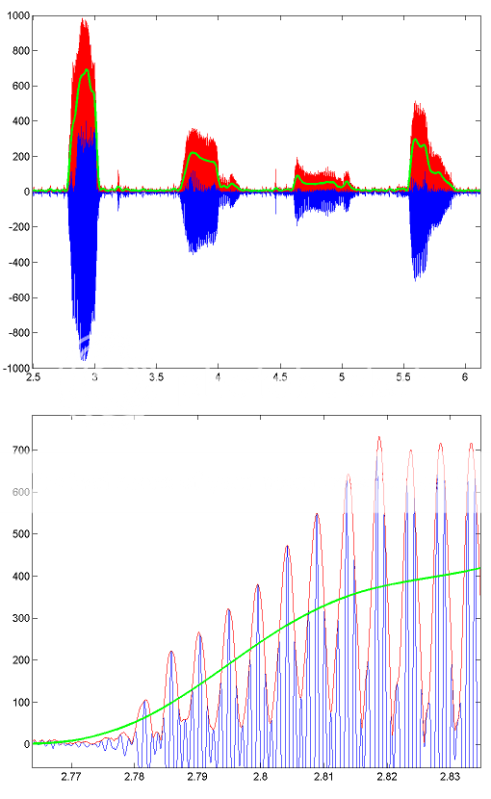
للحصول على مثال لكيفية عمل هذه المعالجة، إليك بعض الصور التي توضح نتائج مقطع من الكلام المسجل.الخط الأزرق هو إشارة الكلام الأصلية، والخط الأحمر هو المغلف (تم الحصول عليه باستخدام هيلبرت)، والخط الأخضر هو النتيجة التي تمت تصفيتها ذات التمرير المنخفض.الشكل السفلي هو نسخة مكبرة من الأول.
شيء عشوائي لمحاولة:
كانت هذه فكرة عشوائية خطرت ببالي في البداية..يمكنك محاولة تكرار العملية من خلال إيجاد الحدود القصوى للحدود القصوى:
index = find(diff(sign(diff([0; x(:); 0]))) < 0);
maxIndex = index(find(diff(sign(diff([0; x(index); 0]))) < 0));
ومع ذلك، اعتمادًا على نسبة الإشارة إلى الضوضاء، لن يكون من الواضح عدد المرات التي يجب تكرارها للحصول على الحد الأقصى المحلي الذي تهتم به.إنه مجرد خيار عشوائي غير مرشح للمحاولة.=)
اكتشاف ماكسيما:
فقط في حال كنت فضوليًا، هناك خوارزمية أخرى لإيجاد الحد الأقصى من سطر واحد رأيتها (بالإضافة إلى تلك التي ذكرتها) هي:
index = find((x > [x(1) x(1:(end-1))]) & (x >= [x(2:end) x(end)]));
إذا كانت بياناتك تقفز لأعلى ولأسفل كثيرًا، فستحتوي الدالة على العديد من الحدود القصوى المحلية.لذلك أفترض أنك لا تريد العثور على جميع الحدود القصوى المحلية.ولكن ما هي معاييرك لتحديد الحد الأقصى المحلي؟إذا كان لديك معايير، فيمكن للمرء تصميم مخطط أو خوارزمية لذلك.
أعتقد الآن أنه ربما يتعين عليك تطبيق مرشح الترددات المنخفضة على بياناتك أولاً، ثم العثور على الحد الأقصى المحلي.على الرغم من أن مواضع الحد الأقصى المحلي بعد التصفية قد لا تتوافق تمامًا مع تلك السابقة.
هناك طريقتان لعرض مثل هذه المشكلة.يمكن للمرء أن ينظر إلى هذا على أنه في المقام الأول مشكلة تجانس، وذلك باستخدام أداة تصفية لتسهيل البيانات، فقط بعد ذلك يتم الاستيفاء باستخدام مجموعة متنوعة من الإقحام، وربما شريحة الاستيفاء.إن العثور على الحد الأقصى المحلي للخط المحرف هو أمر سهل بما فيه الكفاية.(لاحظ أنه يجب عليك بشكل عام استخدام شريحة حقيقية هنا، وليس شريحة pchip interpolant.Pchip، الطريقة المستخدمة عند تحديد interpolant "مكعب" في interp1، لن تحدد بدقة موقع المصغر المحلي الذي يقع بين نقطتي بيانات.)
النهج الآخر لمثل هذه المشكلة هو الذي أميل إلى تفضيله.هنا يستخدم المرء نموذج خط المربعات الصغرى لتسهيل البيانات وإنتاج تقريبي بدلاً من الإقحام.يتمتع خط المربعات الصغرى هذا بميزة السماح للمستخدم بقدر كبير من التحكم لإدخال معرفته بالمشكلة في النموذج.على سبيل المثال، غالبًا ما يكون لدى العالم أو المهندس معلومات، مثل الرتابة، حول العملية قيد الدراسة.يمكن بناء هذا في نموذج خط المربعات الصغرى.خيار آخر ذو صلة هو استخدام شريحة التنعيم.ويمكن أيضًا بناؤها مع وجود قيود تنظيمية مدمجة فيها.إذا كان لديك صندوق أدوات الشريحة، فسيكون spap2 مفيدًا بعض الشيء ليناسب نموذج الشريحة.ثم سوف تجد fnmin المصغر.(يمكن الحصول على أداة التكبير بسهولة من رمز التصغير.)
تكون مخططات التجانس التي تستخدم طرق التصفية أبسط بشكل عام عندما تكون نقاط البيانات متباعدة بشكل متساوٍ.قد تدفع المسافات غير المتساوية إلى نموذج خط المربعات الصغرى.من ناحية أخرى، يمكن أن يكون وضع العقدة مشكلة في خطوط المربعات الصغرى.ما أريد قوله في كل هذا هو الإشارة إلى أن أياً من النهجين له ميزة، ومن الممكن أن يؤدي إلى نتائج قابلة للتطبيق.
