MATLAB에서 시끄러운 데이터로 대략적인 로컬 최대치를 찾기
 https://stackoverflow.com/questions/842131
https://stackoverflow.com/questions/842131
 italiano
italiano english
english français
français española
española 中国
中国 日本の
日本の العربية
العربية Deutsch
Deutsch 한국어
한국어 Português
Português Russian
Russian문제
Matlab FAQ는 로컬 최대치를 찾는 한 줄 방법을 설명합니다.
index = find( diff( sign( diff([0; x(:); 0]) ) ) < 0 );
그러나 나는 이것이 데이터가 다소 부드럽거나 적은 경우에만 효과가 있다고 생각합니다. 작은 간격으로 위아래로 점프하지만 여전히 대략적인 로컬 최대 값이 있다고 가정합니다. 이 점을 어떻게 찾는가? 벡터를 N 조각으로 나누고 각각의 가장자리가 아닌 가장 큰 값을 찾을 수 있지만 더 우아하고 빠른 솔루션이 있어야합니다.
한 줄 솔루션도 좋을 것입니다.
편집하다: 나는 고유 한 섹션으로 나누려는 시끄러운 생물학적 이미지로 작업하고 있습니다.
해결책
원하는 것에 따라 시끄러운 데이터를 필터링하는 것이 종종 도움이됩니다. 보세요 medfilt1, 또는 사용 설득력 와 함께 fspecial. 후자의 접근 방식에서, 당신은 아마도 '동일한'인수를 설득력에 사용하고 fspecial에 의해 생성 된 '가우스'필터를 사용하고 싶을 것입니다.
필터링을 한 후에는 Maxima Finder를 통해 공급하십시오.
편집하다: 런타임 복잡성
입력 벡터의 길이 x이고 필터 커널 길이가 K라고 가정 해 봅시다.
중앙 필터는 펄럭 삽입 정렬을 수행하여 작동 할 수 있으므로 O (X) 여야합니다.K + K log k). 소스 코드를 보지 못했고 다른 구현이 가능하지만 기본적으로 O (x케이).
k가 작을 때 CONV는 간단한 O (x*k) 알고리즘을 사용합니다. X와 K가 거의 동일하면 빠른 푸리에 변환을 사용하는 것이 더 빠릅니다. 해당 구현은 O (x log x + k log k)입니다. MATLAB은 입력 크기에 따라 올바른 알고리즘을 자동으로 선택할 수있을 정도로 스마트합니다.
다른 팁
어떤 유형의 데이터를 다루고 있는지 잘 모르겠지만 여기에 현지 Maxima를 찾는 데 도움이되는 음성 데이터를 처리하는 데 사용한 방법이 있습니다. 신호 처리 도구 상자에서 세 가지 기능을 사용합니다. 힐버트, 버터, 그리고 filtfilt.
data = (...the waveform of noisy data...);
Fs = (...the sampling rate of the data...);
[b,a] = butter(5,20/(Fs/2),'low'); % Create a low-pass butterworth filter;
% adjust the values as needed.
smoothData = filtfilt(b,a,abs(hilbert(data))); % Apply a hilbert transform
% and filter the data.
그런 다음 Maxima 찾기를 수행합니다 SmoothData. Hilbert를 사용하면 먼저 데이터에 양수 봉투를 생성 한 다음 FiltFilt는 버터에서 데이터 봉투를 저역 통과 필터링하기까지 필터 계수를 사용합니다.
이 처리가 어떻게 작동하는지 예를 들어, 기록 된 음성 세그먼트의 결과를 보여주는 일부 이미지가 있습니다. 파란색 선은 원래 음성 신호, 빨간색 선은 봉투 (힐버트를 사용하여 얻음)이며 녹색 선은 저역 통과 필터링 결과입니다. 하단 그림은 첫 번째 버전의 확대 된 버전입니다.
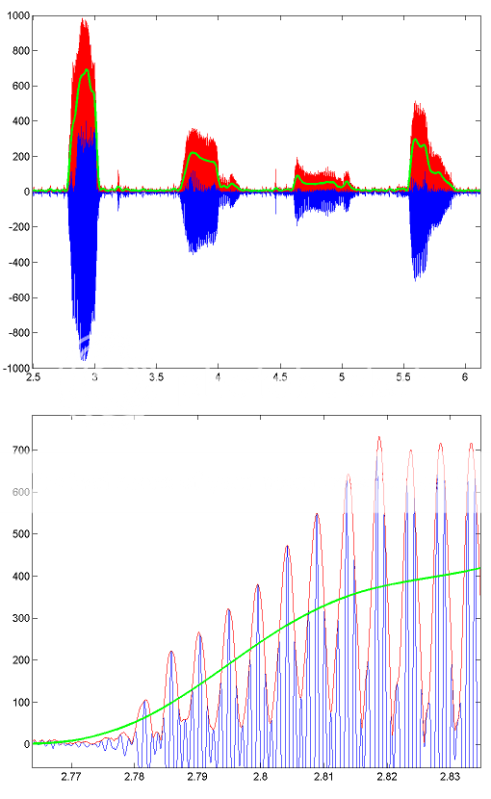
시도 할 무작위 :
이것은 내가 처음에 가지고 있었던 임의의 아이디어였습니다 ... 당신은 Maximas의 Maximas를 찾아서 과정을 반복 할 수 있습니다.
index = find(diff(sign(diff([0; x(:); 0]))) < 0);
maxIndex = index(find(diff(sign(diff([0; x(index); 0]))) < 0));
그러나 신호 대 잡음비에 따라 관심이있는 로컬 최대 값을 얻기 위해 몇 번 반복 해야하는지 불분명합니다. 시도하는 임의의 비 필터링 옵션 일뿐입니다. =))
Maxima 찾기 :
호기심이 많은 경우, 내가 본 또 다른 한 줄의 맥시마 찾기 알고리즘 (나열된 것 외에도)은 다음과 같습니다.
index = find((x > [x(1) x(1:(end-1))]) & (x >= [x(2:end) x(end)]));
데이터가 많이 위아래로 점프하면 기능에 많은 로컬 최대 값이 있습니다. 그래서 나는 당신이 모든 지역 최대를 찾고 싶지 않다고 가정합니다. 그러나 지역 최대 값이 무엇인지에 대한 기준은 무엇입니까? 기준이있는 경우 그에 대한 체계 또는 알고리즘을 설계 할 수 있습니다.
이제 데이터에 저역 통과 필터를 먼저 적용한 다음 로컬 최대 값을 찾아야 할 것 같습니다. 필터링 후 로컬 최대의 위치는 이전의 위치와 정확히 일치하지 않을 수 있지만.
그러한 문제를 보는 두 가지 방법이 있습니다. 필터링 도구를 사용하여 데이터를 부드럽게하기 위해 주로 스무딩 문제로 볼 수 있습니다. 나중에는 다양한 보간, 아마도 보간 스플라인을 사용하여 보간됩니다. 보간 스플라인의 로컬 최대 값을 찾는 것은 충분한 일입니다. (일반적으로 PCHIP 대기업이 아닌 진정한 스플라인을 사용해야합니다. PCHIP는 Interp1에서 "Cubic"보간제를 지정할 때 사용되는 방법 인 PCHIP는 두 데이터 포인트 사이에있는 로컬 최소화를 정확하게 찾지 못합니다).
그러한 문제에 대한 다른 접근법은 내가 선호하는 경향이 있습니다. 여기에서 가장 적은 제곱 스플라인 모델을 사용하여 데이터를 매끄럽게하고 대체 대신 근사값을 생성합니다. 이러한 최소 제곱 스플라인은 사용자가 문제에 대한 지식을 모델에 소개 할 수있는 많은 제어를 허용하는 이점이 있습니다. 예를 들어, 과학자 나 엔지니어는 종종 연구중인 과정에 대한 단조성과 같은 정보를 가지고 있습니다. 이것은 최소 제곱 스플라인 모델에 내장 될 수 있습니다. 또 다른 관련 옵션은 스무딩 스플라인을 사용하는 것입니다. 그것들은 그것들에 내장 된 규칙적인 제약 조건으로 건축 할 수 있습니다. Spline Toolbox가있는 경우 Spap2는 스플라인 모델에 맞는 유틸리티가됩니다. FNMIN은 최소화를 찾을 것입니다. (최소화 코드에서 최대 값을 쉽게 얻을 수 있습니다.)
필터링 방법을 사용하는 스무딩 체계는 일반적으로 데이터 포인트가 동일하게 간격을두면 가장 간단합니다. 불평등 한 간격은 최소 제곱 스플라인 모델을 밀어 넣을 수 있습니다. 반면에, 매듭 배치는 적어도 사각형 스플라인에서 문제가 될 수 있습니다. 이 모든 것에 대한 나의 요점은 어느 접근 방식이 모두 장점이 있으며, 실행 가능한 결과를 생성하기 위해 만들어 질 수 있음을 시사하는 것입니다.
