Нахождение приблизительных локальных максимумов с зашумленными данными в Matlab
 https://stackoverflow.com/questions/842131
https://stackoverflow.com/questions/842131
 italiano
italiano english
english français
français española
española 中国
中国 日本の
日本の العربية
العربية Deutsch
Deutsch 한국어
한국어 Português
Português Russian
RussianВопрос
Часто задаваемые вопросы matlab описывают однострочный метод нахождения локальных максимумов:
index = find( diff( sign( diff([0; x(:); 0]) ) ) < 0 );
Но я считаю, что это работает только в том случае, если данные более или менее сглажены.Предположим, у вас есть данные, которые скачут вверх и вниз с небольшими интервалами, но все еще имеют некоторые приблизительные локальные максимумы.Как бы вы отнеслись к поиску этих точек?Вы могли бы разделить вектор на n частей и найти наибольшее значение не на краю каждой, но должно быть более элегантное и быстрое решение.
Однострочное решение тоже было бы отличным.
Редактировать: Я работаю с зашумленными биологическими изображениями, которые я пытаюсь разделить на отдельные разделы.
Решение
В зависимости от того, что вы хотите, часто бывает полезно отфильтровать зашумленные данные.Взгляните на МЕДФИЛЬТ1, или используя Конвекция вместе с FСПЕЦИАЛЬНЫЙ.В последнем подходе вы, вероятно, захотите использовать 'тот же' аргумент для CONV и 'гауссовский' фильтр, созданный FSPECIAL.
После того как вы выполнили фильтрацию, отправьте ее через maxima finder.
Редактировать: сложность выполнения
Допустим, входной вектор имеет длину X, а длина ядра фильтра равна K.
Медианный фильтр может работать, выполняя текущую сортировку по вставке, поэтому он должен быть O (XK + K log K).Я не смотрел исходный код, и возможны другие реализации, но в принципе это должно быть O (XК).
Когда K мало, conv использует прямолинейный алгоритм O(X*K).Когда X и K почти одинаковы, то быстрее использовать быстрое преобразование Фурье.Эта реализация равна O(X log X + K log K).Matlab достаточно умен, чтобы автоматически выбирать правильный алгоритм в зависимости от размеров входных данных.
Другие советы
Я не уверен, с каким типом данных вы имеете дело, но вот метод, который я использовал для обработки речевых данных, который может помочь вам определить локальные максимумы.Он использует три функции из набора инструментов обработки сигналов: HILBERT, СЛИВОЧНОЕ МАСЛО, и ФИЛЬТРОВАТЬ FILT.
data = (...the waveform of noisy data...);
Fs = (...the sampling rate of the data...);
[b,a] = butter(5,20/(Fs/2),'low'); % Create a low-pass butterworth filter;
% adjust the values as needed.
smoothData = filtfilt(b,a,abs(hilbert(data))); % Apply a hilbert transform
% and filter the data.
Затем вы бы выполнили свой поиск максимумов на Гладкие данные.Использование HILBERT сначала создает положительную огибающую для данных, затем FILTFILT использует коэффициенты фильтра из BUTTER для низкочастотной фильтрации огибающей данных.
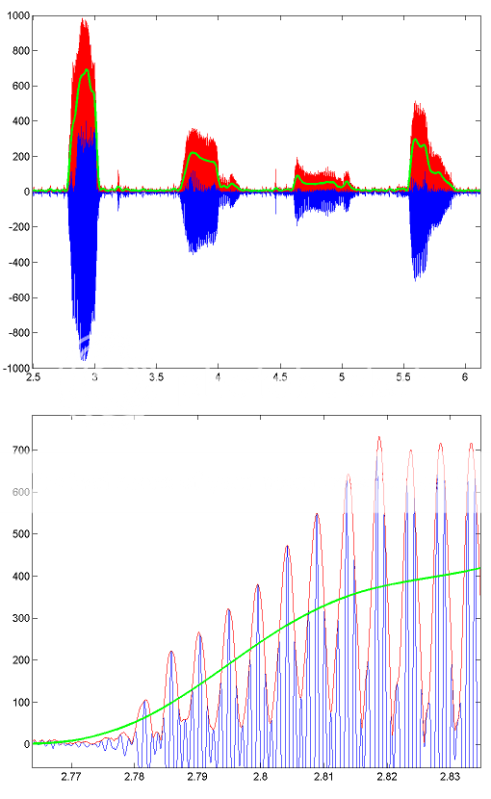
Для примера того, как работает эта обработка, вот несколько изображений, показывающих результаты для сегмента записанной речи.Синяя линия - исходный речевой сигнал, красная линия - огибающая (полученная с помощью HILBERT), а зеленая линия - результат фильтрации нижних частот.Нижний рисунок представляет собой увеличенную версию первого.
ЧТО-НИБУДЬ СЛУЧАЙНОЕ, ЧТОБЫ ПОПРОБОВАТЬ:
Сначала это была случайная идея, которая пришла мне в голову...вы могли бы попробовать повторить процесс, найдя максимумы максимумов:
index = find(diff(sign(diff([0; x(:); 0]))) < 0);
maxIndex = index(find(diff(sign(diff([0; x(index); 0]))) < 0));
Однако, в зависимости от отношения сигнал / шум, было бы неясно, сколько раз это нужно будет повторить, чтобы получить интересующие вас локальные максимумы.Это просто случайный вариант без фильтрации, который нужно попробовать.=)
НАХОЖДЕНИЕ МАКСИМУМОВ:
На всякий случай, если вам интересно, еще один однострочный алгоритм поиска максимумов, который я видел (в дополнение к тому, который вы перечислили), это:
index = find((x > [x(1) x(1:(end-1))]) & (x >= [x(2:end) x(end)]));
Если ваши данные сильно скачут вверх и вниз, то функция будет иметь много локальных максимумов.Поэтому я предполагаю, что вы не хотите находить все локальные максимумы.Но каковы ваши критерии для определения того, что такое локальный максимум?Если у вас есть критерии, то для этого можно разработать схему или алгоритм.
Прямо сейчас я бы предположил, что, возможно, вам сначала следует применить фильтр нижних частот к вашим данным, а затем найти локальные максимумы.Хотя положения локальных максимумов после фильтрации могут не совсем соответствовать предыдущим.
Есть два способа взглянуть на такую проблему.Можно рассматривать это в первую очередь как проблему сглаживания, используя инструмент фильтрации для сглаживания данных, и только после этого выполнять интерполяцию с использованием некоторой разновидности интерполятора, возможно, интерполирующего сплайна.Найти локальный максимум интерполирующего сплайна достаточно просто.(Обратите внимание, что здесь обычно следует использовать истинный сплайн, а не интерполяцию pchip.Pchip, метод, используемый при указании "кубической" интерполяции в interp1, не будет точно определять местоположение локального минимизатора, который находится между двумя точками данных.)
Другой подход к такой проблеме - это тот, который я склонен предпочитать.Здесь используется модель сплайна методом наименьших квадратов как для сглаживания данных, так и для получения аппроксиманта вместо интерполятора.Преимущество такого сплайна методом наименьших квадратов заключается в том, что он предоставляет пользователю большой контроль над внедрением своих знаний о проблеме в модель.Например, часто ученый или инженер располагает такой информацией, как монотонность, об изучаемом процессе.Это может быть встроено в сплайновую модель методом наименьших квадратов.Другой, связанный с этим вариант - использовать сглаживающий сплайн.Они тоже могут быть построены со встроенными в них регулирующими ограничениями.Если у вас есть spline toolbox, то spap2 будет иметь некоторую полезность для соответствия сплайновой модели.Затем fnmin найдет минимайзер.(Максимизатор легко получить из кода минимизации.)
Схемы сглаживания, использующие методы фильтрации, как правило, являются самыми простыми, когда точки данных расположены на равном расстоянии друг от друга.Неравный интервал может привести к использованию сплайновой модели наименьших квадратов.С другой стороны, размещение узлов может быть проблемой в сплайнах методом наименьших квадратов.Моя точка зрения во всем этом состоит в том, чтобы предположить, что любой из подходов имеет свои достоинства и может быть использован для получения жизнеспособных результатов.
