Encontrar máximos locales aproximados con datos ruidosos en Matlab
 https://stackoverflow.com/questions/842131
https://stackoverflow.com/questions/842131
 italiano
italiano english
english français
français española
española 中国
中国 日本の
日本の العربية
العربية Deutsch
Deutsch 한국어
한국어 Português
Português Russian
RussianPregunta
Las preguntas frecuentes de matlab describen un método unilineal para encontrar los máximos locales:
index = find( diff( sign( diff([0; x(:); 0]) ) ) < 0 );
Pero creo que esto sólo funciona si los datos son más o menos fluidos.Suponga que tiene datos que saltan hacia arriba y hacia abajo en pequeños intervalos pero aún tienen algunos máximos locales aproximados.¿Cómo harías para encontrar estos puntos?Podrías dividir el vector en n partes y encontrar el valor más grande no en el borde de cada una, pero debería haber una solución más elegante y rápida.
Una solución de una sola línea también sería genial.
Editar: Estoy trabajando con imágenes biológicas ruidosas que intento dividir en secciones distintas.
Solución
Dependiendo de lo que desee, a menudo es útil filtrar los datos ruidosos. Eche un vistazo a MEDFILT1 , o use CONV junto con FSPECIAL . En este último enfoque, es probable que desee utilizar el 'mismo' argumento para CONV y un filtro 'gaussiano' creado por FSPECIAL.
Después de que haya filtrado, alimente a través del buscador máximo.
EDITAR: complejidad de tiempo de ejecución
Digamos que el vector de entrada tiene una longitud X y la longitud del núcleo del filtro es K.
El filtro mediano puede funcionar realizando una ordenación de inserción en ejecución, por lo que debería ser O (X K + K log K). No he mirado el código fuente y son posibles otras implementaciones, pero básicamente debería ser O (X K).
Cuando K es pequeño, conv utiliza un algoritmo directo O (X * K). Cuando X y K son casi iguales, entonces es más rápido usar una transformación rápida de Fourier. Esa implementación es O (X log X + K log K). Matlab es lo suficientemente inteligente como para elegir automáticamente el algoritmo correcto en función de los tamaños de entrada.
Otros consejos
No estoy seguro de con qué tipo de datos estás tratando, pero aquí tienes un método que he utilizado para procesar datos de voz que podría ayudarte a localizar máximos locales.Utiliza tres funciones de Signal Processing Toolbox: HILBERT, MANTECA, y FILTRAR.
data = (...the waveform of noisy data...);
Fs = (...the sampling rate of the data...);
[b,a] = butter(5,20/(Fs/2),'low'); % Create a low-pass butterworth filter;
% adjust the values as needed.
smoothData = filtfilt(b,a,abs(hilbert(data))); % Apply a hilbert transform
% and filter the data.
Luego realizarías tu hallazgo máximo en datos suaves.El uso de HILBERT primero crea una envolvente positiva en los datos, luego FILTFILT usa los coeficientes de filtro de BUTTER para filtrar la envolvente de datos en paso bajo.
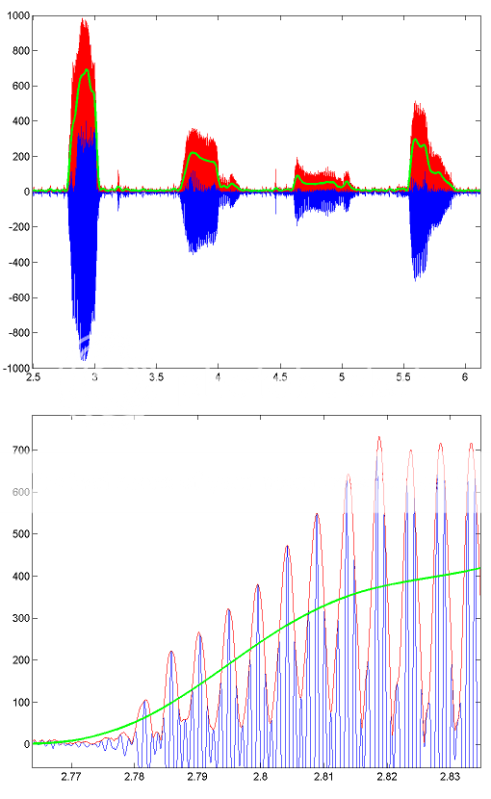
Para ver un ejemplo de cómo funciona este procesamiento, aquí hay algunas imágenes que muestran los resultados de un segmento de voz grabada.La línea azul es la señal de voz original, la línea roja es la envolvente (obtenida con HILBERT) y la línea verde es el resultado del filtrado de paso bajo.La figura inferior es una versión ampliada de la primera.
ALGO ALEATORIO PARA PROBAR:
Esta fue una idea aleatoria que tuve al principio...Podrías intentar repetir el proceso encontrando los máximos de los máximos:
index = find(diff(sign(diff([0; x(:); 0]))) < 0);
maxIndex = index(find(diff(sign(diff([0; x(index); 0]))) < 0));
Sin embargo, dependiendo de la relación señal-ruido, no estaría claro cuántas veces sería necesario repetir esto para obtener los máximos locales que le interesan.Es solo una opción aleatoria sin filtrado para probar.=)
HALLAZGO MÁXIMO:
En caso de que tengas curiosidad, otro algoritmo de búsqueda de máximos de una línea que he visto (además del que mencionaste) es:
index = find((x > [x(1) x(1:(end-1))]) & (x >= [x(2:end) x(end)]));
Si sus datos suben y bajan mucho, entonces la función tendrá muchos máximos locales. Así que supongo que no quieres encontrar todos los máximos locales. Pero, ¿cuál es su criterio para lo que es un máximo local? Si tiene un criterio, entonces uno puede diseñar un esquema o algoritmo para eso.
Supongo en este momento que tal vez debería aplicar primero un filtro de paso bajo a sus datos y luego encontrar los máximos locales. Aunque las posiciones de los máximos locales después del filtrado pueden no corresponder exactamente con las anteriores.
Hay dos formas de ver este problema. Uno puede ver esto principalmente como un problema de suavizado, usando una herramienta de filtrado para suavizar los datos, solo después para interpolar usando alguna variedad de interpolante, tal vez una spline de interpolación. Encontrar un máximo local de una spline interpoladora es algo bastante fácil. (Tenga en cuenta que generalmente debe usar una spline verdadera aquí, no un interpolante pchip. Pchip, el método empleado cuando especifica un & Quot; cubic & Quot; interpolante en interp1, no localizará con precisión un minimizador local que caiga entre dos puntos de datos).
El otro enfoque para tal problema es uno que tiendo a preferir. Aquí se usa un modelo de spline de mínimos cuadrados para suavizar los datos y producir una aproximación en lugar de un interpolante. Tal spline de mínimos cuadrados tiene la ventaja de permitir al usuario un gran control para introducir su conocimiento del problema en el modelo. Por ejemplo, a menudo el científico o ingeniero tiene información, como la monotonía, sobre el proceso en estudio. Esto puede integrarse en un modelo de spline de mínimos cuadrados. Otra opción relacionada es usar una spline de suavizado. También se pueden construir con restricciones de regularización incorporadas en ellos. Si tiene la caja de herramientas de spline, spap2 será de alguna utilidad para adaptarse a un modelo de spline. Entonces fnmin encontrará un minimizador. (Un maximizador se obtiene fácilmente de un código de minimización).
Los esquemas de suavizado que emplean métodos de filtrado son generalmente más simples cuando los puntos de datos están igualmente espaciados. El espaciado desigual podría impulsar el modelo de spline de mínimos cuadrados. Por otro lado, la colocación de nudos puede ser un problema en splines de mínimos cuadrados. Mi punto en todo esto es sugerir que cualquiera de los enfoques tiene mérito, y puede hacerse para producir resultados viables.
