Trovare un massimo locale approssimativo con dati rumorosi in Matlab
 https://stackoverflow.com/questions/842131
https://stackoverflow.com/questions/842131
 italiano
italiano english
english français
français española
española 中国
中国 日本の
日本の العربية
العربية Deutsch
Deutsch 한국어
한국어 Português
Português Russian
RussianDomanda
Le FAQ di matlab descrivono un metodo su una riga per trovare le massime locali:
index = find( diff( sign( diff([0; x(:); 0]) ) ) < 0 );
Ma credo che questo funzioni solo se i dati sono più o meno fluidi. Supponiamo di avere dati che saltano su e giù a piccoli intervalli ma che hanno ancora alcune massime locali approssimative. Come faresti a trovare questi punti? Puoi dividere il vettore in n pezzi e trovare il valore più grande non sul bordo di ciascuno, ma dovrebbe esserci una soluzione più elegante e più veloce.
Anche una soluzione a una riga sarebbe ottima.
Modifica: sto lavorando con immagini biologiche rumorose che sto cercando di dividere in sezioni distinte.
Soluzione
A seconda di ciò che si desidera, è spesso utile filtrare i dati rumorosi. Dai un'occhiata a MEDFILT1 o usando CONV insieme a FSPECIAL . Nel secondo approccio, probabilmente vorrai usare lo stesso argomento con CONV e un filtro 'gaussiano' creato da FSPECIAL.
Dopo aver eseguito il filtraggio, alimentalo tramite il maxima finder.
EDIT: complessità runtime
Supponiamo che il vettore di input abbia lunghezza X e che la lunghezza del kernel del filtro sia K.
Il filtro mediano può funzionare eseguendo un ordinamento di inserzione in esecuzione, quindi dovrebbe essere O (X K + K log K). Non ho esaminato il codice sorgente e altre implementazioni sono possibili, ma sostanzialmente dovrebbe essere O (X K).
Quando K è piccolo, conv utilizza un algoritmo O (X * K) diretto. Quando X e K sono quasi uguali, è più veloce usare una trasformata di Fourier veloce. Tale implementazione è O (X log X + K log K). Matlab è abbastanza intelligente da scegliere automaticamente l'algoritmo giusto in base alle dimensioni dell'input.
Altri suggerimenti
Non sono sicuro del tipo di dati con cui hai a che fare, ma ecco un metodo che ho usato per elaborare i dati vocali che potrebbero aiutarti a localizzare i massimi locali. Utilizza tre funzioni dalla Signal Processing Toolbox: HILBERT , BUTTER e FILTFILT .
data = (...the waveform of noisy data...);
Fs = (...the sampling rate of the data...);
[b,a] = butter(5,20/(Fs/2),'low'); % Create a low-pass butterworth filter;
% adjust the values as needed.
smoothData = filtfilt(b,a,abs(hilbert(data))); % Apply a hilbert transform
% and filter the data.
Dovresti quindi eseguire il rilevamento dei tuoi massimi su smoothData . L'uso di HILBERT crea prima un inviluppo positivo sui dati, quindi FILTFILT utilizza i coefficienti di filtro da BUTTER per filtrare passa basso l'inviluppo dei dati.
Per un esempio di come funziona questa elaborazione, ecco alcune immagini che mostrano i risultati per un segmento di discorso registrato. La linea blu è il segnale vocale originale, la linea rossa è l'inviluppo (ottenuto usando HILBERT) e la linea verde è il risultato filtrato passa-basso. La figura in basso è una versione ingrandita della prima.
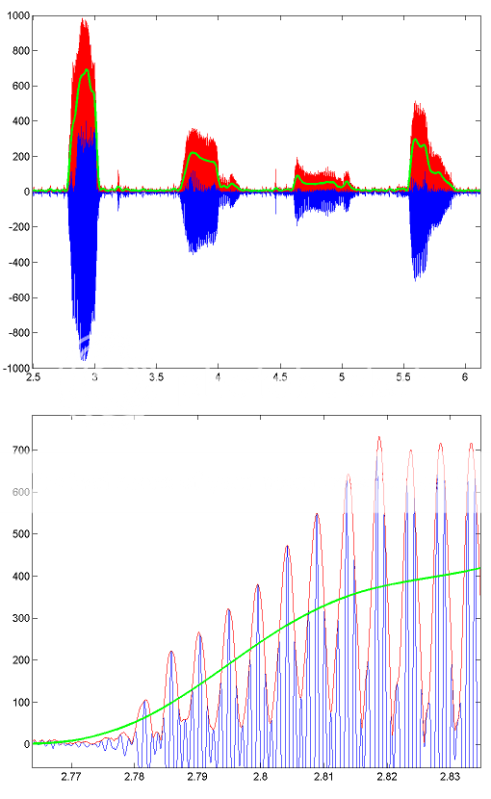
QUALCOSA DI CASO DA PROVARE:
Questa è stata un'idea casuale che ho avuto all'inizio ... potresti provare a ripetere il processo trovando le massime delle massime:
index = find(diff(sign(diff([0; x(:); 0]))) < 0);
maxIndex = index(find(diff(sign(diff([0; x(index); 0]))) < 0));
Tuttavia, a seconda del rapporto segnale-rumore, non sarebbe chiaro quante volte questo dovrebbe essere ripetuto per ottenere i massimi locali a cui sei interessato. È solo un'opzione casuale di non filtro per provare. =)
TROVAZIONE MAXIMA:
Nel caso in cui tu sia curioso, un altro algoritmo di ricerca di valori massimi di una riga che ho visto (oltre a quello che hai elencato) è:
index = find((x > [x(1) x(1:(end-1))]) & (x >= [x(2:end) x(end)]));
Se i tuoi dati saltano molto su e giù, la funzione avrà molti massimi locali. Quindi presumo che tu non voglia trovare tutti i massimi locali. Ma quali sono i tuoi criteri per ciò che è un massimo locale? Se hai dei criteri, allora puoi progettare uno schema o un algoritmo per quello.
Immagino che adesso dovresti applicare prima un filtro passa-basso ai tuoi dati, quindi trovare i massimi locali. Sebbene le posizioni dei massimi locali dopo il filtraggio potrebbero non corrispondere esattamente a quelle precedenti.
Esistono due modi per visualizzare questo problema. Si può considerare questo come principalmente un problema di livellamento, usando uno strumento di filtro per smussare i dati, solo successivamente per interpolare usando una varietà di interpolanti, forse una spline interpolante. Trovare un massimo locale di una spline interpolante è una cosa abbastanza semplice. (Nota che dovresti generalmente usare una spline vera qui, non un interpolante pchip. Pchip, il metodo impiegato quando specifichi un & Quot; cubico & Quot; interpolant in interp1, non localizzerà accuratamente un minimizer locale che cade tra due punti dati.)
L'altro approccio a tale problema è quello che tendo a preferire. Qui si utilizza un modello di spline dei minimi quadrati sia per lisciare i dati sia per produrre un approssimativo anziché un interpolante. Tale spline di minimi quadrati ha il vantaggio di consentire all'utente un grande controllo per introdurre la propria conoscenza del problema nel modello. Ad esempio, spesso lo scienziato o l'ingegnere dispone di informazioni, come la monotonia, sul processo in studio. Questo può essere incorporato in un modello di spline dei minimi quadrati. Un'altra opzione correlata è utilizzare una spline di livellamento. Anche loro possono essere costruiti con vincoli di regolarizzazione incorporati in essi. Se hai la casella degli strumenti spline, allora spap2 sarà di qualche utilità per adattarsi a un modello spline. Quindi fnmin troverà un minimizer. (Un massimizzatore si ottiene facilmente da un codice di minimizzazione.)
Gli schemi di livellamento che utilizzano metodi di filtraggio sono generalmente più semplici quando i punti dati sono equidistanti. Una spaziatura disuguale potrebbe spingere per il modello di spline dei minimi quadrati. D'altra parte, il posizionamento del nodo può essere un problema nelle spline dei minimi quadrati. Il mio punto in tutto ciò è suggerire che entrambi gli approcci hanno valore e possono essere fatti per produrre risultati fattibili.
