使用R.动物园绘制的多个系列错误的酒吧
 https://stackoverflow.com/questions/3025347
https://stackoverflow.com/questions/3025347
-
26-09-2019 - |
 italiano
italiano english
english français
français española
española 中国
中国 日本の
日本の العربية
العربية Deutsch
Deutsch 한국어
한국어 Português
Português Russian
Russian题
我有数据,看起来是这样的:
> head(data)
groupname ob_time dist.mean dist.sd dur.mean dur.sd ct.mean ct.sd
1 rowA 0.3 61.67500 39.76515 43.67500 26.35027 8.666667 11.29226
2 rowA 60.0 45.49167 38.30301 37.58333 27.98207 8.750000 12.46176
3 rowA 120.0 50.22500 35.89708 40.40000 24.93399 8.000000 10.23363
4 rowA 180.0 54.05000 41.43919 37.98333 28.03562 8.750000 11.97061
5 rowA 240.0 51.97500 41.75498 35.60000 25.68243 28.583333 46.14692
6 rowA 300.0 45.50833 43.10160 32.20833 27.37990 12.833333 14.21800
每个组名是一个数据系列。因为我想绘制每个系列的另外,我们分开他们这样的:
> A <- zoo(data[which(groupname=='rowA'),3:8],data[which(groupname=='rowA'),2])
> B <- zoo(data[which(groupname=='rowB'),3:8],data[which(groupname=='rowB'),2])
> C <- zoo(data[which(groupname=='rowC'),3:8],data[which(groupname=='rowC'),2])
ETA:
Thanks to gd047: Now I'm using this:
z <- dlply(data,.(groupname),function(x) zoo(x[,3:8],x[,2]))
得到的动物园的对象是这样的:
> head(z$rowA)
dist.mean dist.sd dur.mean dur.sd ct.mean ct.sd
0.3 61.67500 39.76515 43.67500 26.35027 8.666667 11.29226
60 45.49167 38.30301 37.58333 27.98207 8.750000 12.46176
120 50.22500 35.89708 40.40000 24.93399 8.000000 10.23363
180 54.05000 41.43919 37.98333 28.03562 8.750000 11.97061
240 51.97500 41.75498 35.60000 25.68243 28.583333 46.14692
300 45.50833 43.10160 32.20833 27.37990 12.833333 14.21800
所以如果我想要阴谋dist.意味着反对的时间和包括错误的酒吧等于+/-dist.sd每个系列:
- 我如何结合A、B、C区。意思是和dist.sd?
- 我如何做一个酒吧的情节, 或者也许更好, 一线图得到的对象?
解决方案
我没有看到这一点,打破了数据分成三块,只有结合在一起情节。这里是一个阴谋使用 ggplot2 图书馆:
library(ggplot2)
qplot(ob_time, dist.mean, data=data, colour=groupname, geom=c("line","point")) +
geom_errorbar(aes(ymin=dist.mean-dist.sd, ymax=dist.mean+dist.sd))
这个空间的时间值沿着的自然规模,可以使用 scale_x_continuous 定义tickmarks在实际时间值。让他们等间隔是棘手:你可以转换 ob_time 以一个因素,但是然后 qplot 拒绝连接点。
解决方案1-巴图:
qplot(factor(ob_time), dist.mean, data=data, geom=c("bar"), fill=groupname,
colour=groupname, position="dodge") +
geom_errorbar(aes(ymin=dist.mean-dist.sd, ymax=dist.mean+dist.sd), position="dodge")
解决方案2-添加行手动使用的1,2,...重新编码的因素:
qplot(factor(ob_time), dist.mean, data=data, geom=c("line","point"), colour=groupname) +
geom_errorbar(aes(ymin=dist.mean-dist.sd, ymax=dist.mean+dist.sd)) +
geom_line(aes(x=as.numeric(factor(ob_time))))
其他提示
这是一个暗示的方式,我会尝试这样做。我有忽略分组,这样你就必须修改,以包括更多于一个系列。我也没有使用动物园,因为我不知道多少。
g <- (nrow(data)-1)/(3*nrow(data))
plot(data[,"dist.mean"],col=2, type='o',lwd=2,cex=1.5, main="This is the title of the graph",
xlab="x-Label", ylab="y-Label", xaxt="n",
ylim=c(0,max(data[,"dist.mean"])+max(data[,"dist.sd"])),
xlim=c(1-g,nrow(data)+g))
axis(side=1,at=c(1:nrow(data)),labels=data[,"ob_time"])
for (i in 1:nrow(data)) {
lines(c(i,i),c(data[i,"dist.mean"]+data[i,"dist.sd"],data[i,"dist.mean"]-data[i,"dist.sd"]))
lines(c(i-g,i+g),c(data[i,"dist.mean"]+data[i,"dist.sd"], data[i,"dist.mean"]+data[i,"dist.sd"]))
lines(c(i-g,i+g),c(data[i,"dist.mean"]-data[i,"dist.sd"], data[i,"dist.mean"]-data[i,"dist.sd"]))
}
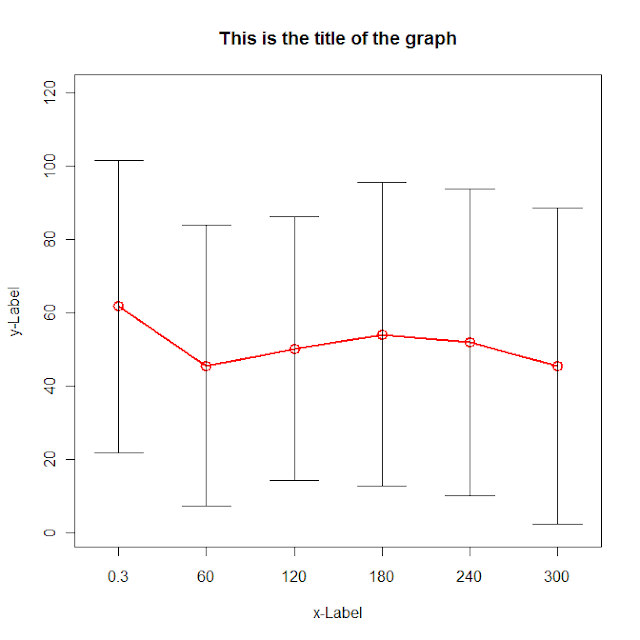
读取的数据在使用的阅读。动物园的分割=参数分割的组名.然后绑定在一起的区较低和上线。最后的阴谋。
Lines <- "groupname ob_time dist.mean dist.sd dur.mean dur.sd ct.mean ct.sd
rowA 0.3 61.67500 39.76515 43.67500 26.35027 8.666667 11.29226
rowA 60.0 45.49167 38.30301 37.58333 27.98207 8.750000 12.46176
rowA 120.0 50.22500 35.89708 40.40000 24.93399 8.000000 10.23363
rowA 180.0 54.05000 41.43919 37.98333 28.03562 8.750000 11.97061
rowB 240.0 51.97500 41.75498 35.60000 25.68243 28.583333 46.14692
rowB 300.0 45.50833 43.10160 32.20833 27.37990 12.833333 14.21800"
library(zoo)
# next line is only needed until next version of zoo is released
source("http://r-forge.r-project.org/scm/viewvc.php/*checkout*/pkg/zoo/R/read.zoo.R?revision=719&root=zoo")
z <- read.zoo(textConnection(Lines), header = TRUE, split = 1, index = 2)
# pick out the dist and sd columns binding dist with lower & upper
z.dist <- z[, grep("dist.mean", colnames(z))]
z.sd <- z[, grep("dist.sd", colnames(z))]
zz <- cbind(z = z.dist, lower = z.dist - z.sd, upper = z.dist + z.sd)
# plot using N panels
N <- ncol(z.dist)
ylab <- sub("dist.mean.", "", colnames(z.dist))
plot(zz, screen = 1:N, type = "l", lty = rep(1:2, N*1:2), ylab = ylab)
我不认为你需要创造动物园的对象对这类情节,我会这样做直接从数据框架。当然,可能还有其它原因使用动物园的对象,这样一个聪明的融合,汇聚,等等。
一种选择是的 segplot 能从latticeExtra
library(latticeExtra)
segplot(ob_time ~ (dist.mean + dist.sd) + (dist.mean - dist.sd) | groupname,
data = data, centers = dist.mean, horizontal = FALSE)
## and with the latest version of latticeExtra (from R-forge):
trellis.last.object(segments.fun = panel.arrows, ends = "both", angle = 90, length = .1) +
xyplot(dist.mean ~ ob_time | groupname, data, col = "black", type = "l")
使用Gabor的很好的-可重复的数据集中这种生产:

不隶属于 StackOverflow
