Finden ungefährer lokaler Maxima mit verrauschten Daten in Matlab
 https://stackoverflow.com/questions/842131
https://stackoverflow.com/questions/842131
 italiano
italiano english
english français
français española
española 中国
中国 日本の
日本の العربية
العربية Deutsch
Deutsch 한국어
한국어 Português
Português Russian
RussianFrage
Die Matlab-FAQ beschreibt eine einzeilige Methode zum Finden der lokalen Maxima:
index = find( diff( sign( diff([0; x(:); 0]) ) ) < 0 );
Aber ich glaube, das funktioniert nur, wenn die Daten einigermaßen glatt sind.Angenommen, Sie haben Daten, die in kleinen Intervallen auf und ab springen, aber dennoch einige ungefähre lokale Maxima aufweisen.Wie würden Sie vorgehen, um diese Punkte zu finden?Sie könnten den Vektor in n Teile aufteilen und den größten Wert nicht am Rand jedes einzelnen finden, aber es sollte eine elegantere und schnellere Lösung geben.
Eine einzeilige Lösung wäre auch toll.
Bearbeiten: Ich arbeite mit verrauschten biologischen Bildern, die ich versuche, in verschiedene Abschnitte zu unterteilen.
Lösung
Je nachdem, was Sie wollen, ist es oft hilfreich, die verrauschten Daten zu filtern. Schauen Sie sich auf MEDFILT1 oder mit CONV zusammen mit FSPECIAL . Im letzteren Ansatz, werden Sie wahrscheinlich das ‚gleiche‘ Argument CONV und einen ‚Gaußsche‘ von FSPECIAL erstellt Filter verwendet werden sollen.
Nachdem Sie die Filterung getan haben, führen Sie es durch die Maxima Finder.
EDIT: Laufzeitkomplexität
Nehmen wir an, der Eingangsvektor Länge X hat und der Filterkern Länge K.
Der Medianfilter kann arbeiten, indem sie einen laufenden Insertionsort tun, so soll es sein O (X K + K K log). Ich habe nicht auf den Quellcode und andere Implementierungen sind möglich, aber im Grunde sollte es sein O (X K).
sahWenn K klein ist, verwendet konv einen straight-forward O (X * K) Algorithmus. Wenn X und K fast gleich sind, dann ist es schneller verwandelt eine schnelle Fourier zu verwenden. Dass die Umsetzung ist O (X log X + K log K). Matlab ist intelligent genug, um automatisch den richtigen Algorithmus zu wählen, abhängig von den Eingangsgrößen.
Andere Tipps
Ich bin mir nicht sicher, mit welcher Art von Daten Sie es zu tun haben, aber hier ist eine Methode, die ich zur Verarbeitung von Sprachdaten verwendet habe und die Ihnen beim Auffinden lokaler Maxima helfen könnte.Es nutzt drei Funktionen aus der Signal Processing Toolbox: HILBERT, BUTTER, Und FILTFILT.
data = (...the waveform of noisy data...);
Fs = (...the sampling rate of the data...);
[b,a] = butter(5,20/(Fs/2),'low'); % Create a low-pass butterworth filter;
% adjust the values as needed.
smoothData = filtfilt(b,a,abs(hilbert(data))); % Apply a hilbert transform
% and filter the data.
Anschließend würden Sie Ihre Maxima-Ermittlung durchführen glatte Daten.Durch die Verwendung von HILBERT wird zunächst eine positive Hüllkurve für die Daten erstellt. Anschließend verwendet FILTFILT die Filterkoeffizienten von BUTTER, um die Datenhüllkurve tiefpasszufiltern.
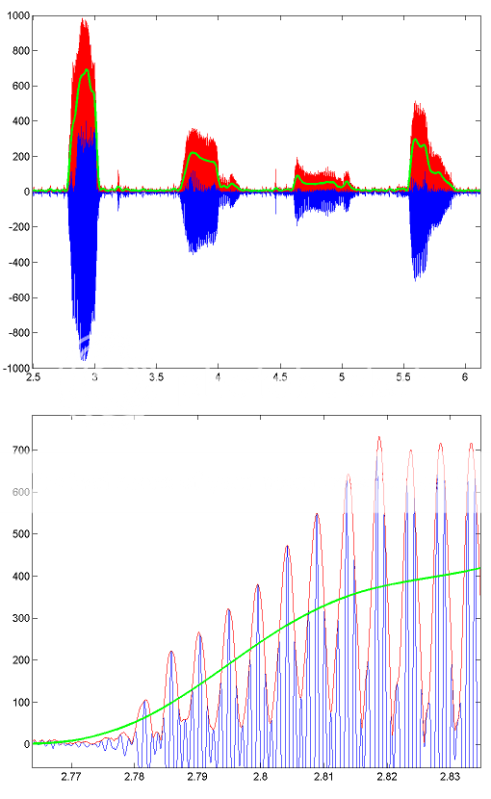
Als Beispiel dafür, wie diese Verarbeitung funktioniert, finden Sie hier einige Bilder, die die Ergebnisse für einen Abschnitt aufgezeichneter Sprache zeigen.Die blaue Linie ist das ursprüngliche Sprachsignal, die rote Linie ist die Hüllkurve (erhalten mit HILBERT) und die grüne Linie ist das tiefpassgefilterte Ergebnis.Die untere Abbildung ist eine vergrößerte Version der ersten.
ETWAS ZUFÄLLIGES ZUM AUSPROBIEREN:
Das war eine zufällige Idee, die ich zuerst hatte ...Sie könnten versuchen, den Vorgang zu wiederholen, indem Sie die Maxima der Maxima ermitteln:
index = find(diff(sign(diff([0; x(:); 0]))) < 0);
maxIndex = index(find(diff(sign(diff([0; x(index); 0]))) < 0));
Abhängig vom Signal-Rausch-Verhältnis wäre jedoch unklar, wie oft dies wiederholt werden müsste, um die gewünschten lokalen Maxima zu erhalten.Es handelt sich lediglich um eine zufällige, nicht filternde Option zum Ausprobieren.=)
MAXIMA-FESTSTELLUNG:
Nur für den Fall, dass Sie neugierig sind: Ein weiterer einzeiliger Maxima-Suchalgorithmus, den ich gesehen habe (zusätzlich zu dem von Ihnen aufgeführten), ist:
index = find((x > [x(1) x(1:(end-1))]) & (x >= [x(2:end) x(end)]));
Wenn Sie Ihre Daten auf und ab springt viel, dann wird die Funktion viele lokale Maxima haben. Also ich gehe davon aus, dass Sie nicht wollen, alle lokalen Maxima zu finden. Aber was ist Ihre Kriterien für das, was ein lokales Maximum ist? Wenn Sie ein Kriterium haben, dann kann man einen schem entwerfen oder einen Algorithmus für die.
Ich würde jetzt vermuten, dass vielleicht sollten Sie zunächst einen Tiefpassfilter auf Ihre Daten anwenden und dann die lokalen Maxima finden. Obwohl die Positionen der lokalen Maxima nach Filterung die nicht genau vor entsprechen.
Es gibt zwei Möglichkeiten, ein solches Problem zu betrachten. Man kann dies als in ersten Linie eines Glättungs Problem betrachten, einen Filter Werkzeug unter Verwendung der Daten zu glätten, erst danach mit irgendeiner Vielzahl von Interpolationsmittels zu interpolieren, vielleicht einen Interpolations-Splines. ein lokales Maximum einer Interpolations-Spline zu finden, ist eine einfach genug Sache. (Beachten Sie, dass Sie in der Regel einen echten Spline hier verwendet werden sollen, nicht pchip Interpolant. Pchip, wobei das Verfahren verwendet wird, wenn Sie ein „cubic“ Interpolant in interp1 angeben, wird nicht genau einen lokalen Minimierer suchen, die zwischen zwei Datenpunkte fallen.)
Der andere Ansatz für ein solches Problem ist eine, die ich neige dazu, bevorzugen. Hier verwendet man ein Least-Squares-Spline Modell sowohl für die Daten zu glätten und eine approximant anstelle eines Interpolationsmittels zu erzeugen. Eine solche kleinsten Quadrate Spline hat den Vorteil, dass dem Benutzer ein hohes Maß an Kontrolle, ihr Wissen über das Problem in das Modell einzuführen. Zum Beispiel oft die Wissenschaftler oder Ingenieur haben Informationen, wie Monotonie, über den Prozess untersucht. Dies kann in ein Least-Squares-Spline Modell gebaut werden. Eine weitere, verwandte Option ist eine glättende Spline zu verwenden. Sie können auch mit Regularisierung Einschränkungen in ihnen gebaut werden gebaut. Wenn Sie die Spline-Toolbox haben, dann wird spap2 einiger Nützlichkeit sein, ein Spline-Modell zu passen. Dann wird fnmin einen Minimierer finden. (A maximizer ist leicht von einer Minimierung Code erhalten.)
Glättungsfilterungsschemata, die Verfahren verwenden in der Regel einfachsten, wenn die Datenpunkte mit gleichem Abstand sind. Ungleiche Abstände könnten für die kleinsten Quadrate Spline Modell schieben. Auf der anderen Seite, Knoten Platzierung kann ein Problem in der kleinsten Quadrate Splines sein. Mein Punkt in all dies ist zu vermuten, dass entweder Ansatz Verdienst hat, und gemacht werden kann tragfähige Ergebnisse zu erzielen.
