كيف يتم التلاعب غير المدمر المدمر للذاكرة للمجموعات التي تحققت في البرمجة الوظيفية؟
 https://stackoverflow.com/questions/1993760
https://stackoverflow.com/questions/1993760
-
22-09-2019 - |
 italiano
italiano english
english français
français española
española 中国
中国 日本の
日本の العربية
العربية Deutsch
Deutsch 한국어
한국어 Português
Português Russian
Russianسؤال
أحاول معرفة كيفية تنفيذ التلاعب غير التدميري للمجموعات الكبيرة في البرمجة الوظيفية ، أي. كيف يمكن تغيير أو إزالة عناصر واحدة دون الحاجة إلى إنشاء مجموعة جديدة تمامًا حيث سيتم تكرار جميع العناصر ، حتى العناصر غير المعدلة ، في الذاكرة. (حتى لو كانت المجموعة الأصلية قد تم جمعها القمامة ، أتوقع أن تكون بصمة الذاكرة والأداء العام لمثل هذه المجموعة فظيعة.)
هذا هو المدى الذي وصلت إليه حتى الآن:
باستخدام F#، توصلت إلى وظيفة insert هذا يقسم القائمة إلى قطعتين ويقدم عنصرًا جديدًا بينهما ، على ما يبدو دون استنساخ جميع العناصر التي لم تتغير:
// return a list without its first n elements:
// (helper function)
let rec skip list n =
if n = 0 then
list
else
match list with
| [] -> []
| x::xs -> skip xs (n-1)
// return only the first n elements of a list:
// (helper function)
let rec take list n =
if n = 0 then
[]
else
match list with
| [] -> []
| x::xs -> x::(take xs (n-1))
// insert a value into a list at the specified zero-based position:
let insert list position value =
(take list position) @ [value] @ (skip list position)
بعد ذلك ، راجعت ما إذا كانت الكائنات من القائمة الأصلية "معاد تدويرها" في قوائم جديدة باستخدام .NET's Object.ReferenceEquals:
open System
let (===) x y =
Object.ReferenceEquals(x, y)
let x = Some(42)
let L = [Some(0); x; Some(43)]
let M = Some(1) |> insert L 1
كل التعبيرات الثلاثة التالية تقيم جميعها true, مشيرا إلى أن القيمة المشار إليها بواسطة x يتم إعادة استخدامهما في القوائم L و M, ، بمعنى آخر. أن هناك نسخة واحدة فقط من هذه القيمة في الذاكرة:
L.[1] === x
M.[2] === x
L.[1] === M.[2]
سؤالي:
هل تعيد استخدام لغات البرمجة الوظيفية عمومًا استخدام القيم بدلاً من استنساخها إلى موقع ذاكرة جديد ، أم أنني كنت محظوظًا بسلوك F#؟ على افتراض السابق ، هل هذا هو كيف يمكن تنفيذ تحرير المجموعات الفعال للذاكرة في البرمجة الوظيفية؟
(راجع للشغل: أعرف عن كتاب كريس أوكاساكي هياكل البيانات الوظيفية البحتة, ، لكن لم يكن لديه الوقت الكافي لقراءته بدقة.)
المحلول
أحاول معرفة كيفية تنفيذ التلاعب غير التدميري للمجموعات الكبيرة في البرمجة الوظيفية ، أي. كيف يمكن تغيير أو إزالة عناصر واحدة دون الحاجة إلى إنشاء مجموعة جديدة تمامًا حيث سيتم تكرار جميع العناصر ، حتى العناصر غير المعدلة ، في الذاكرة.
هذه الصفحة لديه بعض الأوصاف وتطبيقات هياكل البيانات في F#. معظمهم يأتون من أوكاساكي هياكل البيانات الوظيفية البحتة, ، على الرغم من أن شجرة AVL هي تنفيذي لأنها لم تكن موجودة في الكتاب.
الآن ، منذ أن سألت ، عن إعادة استخدام العقد غير المعدلة ، دعنا نأخذ شجرة ثنائية بسيطة:
type 'a tree =
| Node of 'a tree * 'a * 'a tree
| Nil
let rec insert v = function
| Node(l, x, r) as node ->
if v < x then Node(insert v l, x, r) // reuses x and r
elif v > x then Node(l, x, insert v r) // reuses x and l
else node
| Nil -> Node(Nil, v, Nil)
لاحظ أننا نعيد استخدام بعض العقد لدينا. لنفترض أننا نبدأ بهذه الشجرة:
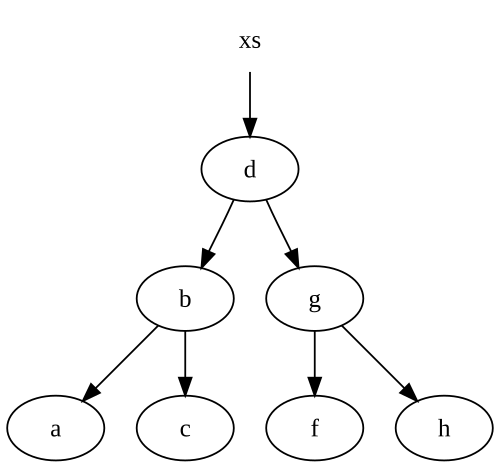
عندما نقدم e في الشجرة ، نحصل على شجرة جديدة ، مع بعض العقد التي تشير إلى شجرتنا الأصلية:

إذا لم يكن لدينا إشارة إلى xs شجرة أعلاه ، ثم .net ستجمع أي عقد بدون مراجع حية ، وتحديداd, g و f العقد.
لاحظ أننا قمنا فقط بتعديل العقد على طول طريق العقدة المدرجة لدينا. هذا نموذجي إلى حد كبير في معظم هياكل البيانات غير القابلة للتغيير ، بما في ذلك القوائم. لذلك ، فإن عدد العقد التي نقوم بإنشائها مساوية تمامًا لعدد العقد التي نحتاج إلى اجتيازها من أجل إدراجها في بنية البيانات الخاصة بنا.
هل تعيد استخدام لغات البرمجة الوظيفية عمومًا استخدام القيم بدلاً من استنساخها إلى موقع ذاكرة جديد ، أم أنني كنت محظوظًا بسلوك F#؟ على افتراض السابق ، هل هذا هو كيف يمكن تنفيذ تحرير المجموعات الفعال للذاكرة في البرمجة الوظيفية؟
نعم.
ومع ذلك ، فإن القوائم ليست بنية بيانات جيدة جدًا ، لأن معظم العمليات غير التافهة عليها تتطلب وقتًا (ن).
تدعم الأشجار الثنائية المتوازنة O (log n) إدراج ، مما يعني أننا ننشئ نسخًا (سجل n) على كل إدراج. منذ السجل2(10^15) هو ~ = 50 ، النفقات العامة صغيرة جدًا بالنسبة لهذه الهياكل الخاصة بالبيانات. حتى إذا احتفظت بكل نسخة من كل كائن بعد إدراج/حذف ، فإن استخدام الذاكرة الخاص بك سيزداد بمعدل O (n log n) - معقول جدًا ، في رأيي.
نصائح أخرى
كيف يمكن تغيير أو إزالة عناصر واحدة دون الحاجة إلى إنشاء مجموعة جديدة تمامًا حيث سيتم تكرار جميع العناصر ، حتى العناصر غير المعدلة ، في الذاكرة.
هذا يعمل لأنه بغض النظر عن نوع المجموعة ، مؤشرات يتم تخزين العناصر بشكل منفصل عن العناصر نفسها. (استثناء: سيقوم بعض المترجمين بتحسين بعض الوقت ، لكنهم يعرفون ما يفعلونه.) لذلك على سبيل المثال ، يمكنك الحصول على قائمتين تختلفان فقط في العنصر الأول ومشاركة ذيول:
let shared = ["two", "three", "four"]
let l = "one" :: shared
let l' = "1a" :: shared
هاتان القائمتين لهما shared جزء مشترك وعناصرهم الأولى مختلفة. ما هو أقل وضوحًا هو أن كل قائمة تبدأ أيضًا بزوج فريد ، غالبًا ما يسمى "Cons Cell":
قائمة
lيبدأ بزوج يحتوي على مؤشر"one"ومؤشر إلى الذيل المشترك.قائمة
l'يبدأ بزوج يحتوي على مؤشر"1a"ومؤشر إلى الذيل المشترك.
إذا كنا قد أعلننا فقط l وأراد ذلك تغيير أو إزالة العنصر الأول لتأخذ، لتمتلك l', ، سنفعل هذا:
let l' = match l with
| _ :: rest -> "1a" :: rest
| [] -> raise (Failure "cannot alter 1st elem of empty list")
هناك تكلفة ثابتة:
انشق، مزق
lفي رأسها وذيلها عن طريق فحص خلية Cons.تخصيص خلية جديدة تشير إلى
"1a"وذيل.
تصبح خلية Cons الجديدة قيمة القائمة l'.
إذا كنت تقوم بتغييرات تشبه النقاط في منتصف مجموعة كبيرة ، فعادة ما ستستخدم نوعًا من الأشجار المتوازنة التي تستخدم وقت ومساحة لوغاريتمي. في كثير من الأحيان ، قد تستخدم بنية بيانات أكثر تطوراً:
جيرارد هوت سحاب البنطلون يمكن تعريفها لأي بنية بيانات تشبه الأشجار ويمكن استخدامها لاجتياز وإجراء تعديلات شبيهة بتكلفة ثابتة. السوستة سهلة الفهم.
باترسون وهينز أشجار الإصبع تقدم تمثيلات متطورة للغاية للتسلسلات ، والتي من بين الحيل الأخرى تمكنك من تغيير العناصر في الوسط بكفاءة - ولكن من الصعب فهمها.
على الرغم من أن الكائنات المرجعية هي نفسها في الكود الخاص بك ، إلا أنني أتخلى عن مساحة التخزين للمراجع نفسها وهيكل القائمة تكرارها بواسطة take. نتيجة لذلك ، في حين أن الكائنات المشار إليها هي نفسها ، وتتم مشاركة ذيول بين القائمتين ، يتم تكرار "الخلايا" للأجزاء الأولية.
أنا لست خبيراً في البرمجة الوظيفية ، ولكن ربما مع نوع من الأشجار ، يمكنك تحقيق ازدواجية عن عناصر السجل (N) فقط ، حيث يجب عليك إعادة إنشاء المسار فقط من الجذر إلى العنصر المدرج.
يبدو لي أن سؤالك هو في المقام الأول بيانات ثابتة, وليس اللغات الوظيفية في حد ذاته. البيانات هي في الواقع غير قابلة للتغيير في التعليمات البرمجية الوظيفية البحتة (راجع الشفافية المرجعية) ، لكنني لست على دراية بأي لغات غير عادية تنفذ نقاء المطلقة في كل مكان (على الرغم من أن Haskell يأتي الأقرب ، إذا كنت تحب هذا النوع من الأشياء).
بالمعنى الدقة ، تعني الشفافية المرجعية ذلك لا يوجد فرق عملي بين متغير/تعبير والقيمة التي يحملها/تقييمها. نظرًا لأن جزءًا من البيانات غير القابلة للتغيير لن تتغير (بحكم التعريف) أبدًا ، يمكن تحديدها بشكل تافه مع قيمتها ويجب أن تتصرف بشكل لا يمكن تمييزها عن أي بيانات أخرى بنفس القيمة.
لذلك ، من خلال اختيار عدم التمييز الدلالي بين قطعتين من البيانات بنفس القيمة ، ليس لدينا أي سبب لإنشاء قيمة مكررة. لذلك ، في حالات المساواة الواضحة (على سبيل المثال ، إضافة شيء ما إلى قائمة ، تمريره كوسيطة وظيفة ، & c.) ، فإن اللغات التي تكون فيها ضمانات التثبيت ممكنة بشكل عام ستعيد استخدام المرجع الحالي ، كما تقول.
وبالمثل ، غير قابل للتغيير هياكل البيانات تمتلك شفافية مرجعية جوهرية لهيكلها (وإن لم تكن محتوياتها). على افتراض أن جميع القيم الموجودة غير قابلة للتغيير ، فهذا يعني أنه يمكن إعادة استخدام أجزاء من الهيكل بأمان في هياكل جديدة أيضًا. على سبيل المثال ، يمكن إعادة استخدام ذيل قائمة السلبيات ؛ في الكود الخاص بك ، أتوقع ذلك:
(skip 1 L) === (skip 2 M)
...سيكون ايضا كن صادقا.
إعادة الاستخدام غير ممكن دائمًا ، على الرغم من ؛ الجزء الأولي من القائمة التي تمت إزالتها بواسطة skip لا يمكن إعادة استخدام الوظيفة حقًا ، على سبيل المثال. للسبب نفسه ، يعد إلحاق شيء ما حتى نهاية قائمة السلبيات عملية باهظة الثمن ، حيث يجب أن تعيد بناء قائمة جديدة كاملة ، على غرار مشكلة السلاسل المسلحة المسلحة.
في مثل هذه الحالات ، تدخل النهج الساذجة بسرعة في عالم الأداء الفظيع الذي كنت قلقًا بشأنه. في كثير من الأحيان ، من الضروري إعادة التفكير بشكل كبير في الخوارزميات الأساسية وهياكل البيانات لتكييفها بنجاح مع البيانات غير القابلة للتغيير. تتضمن التقنيات تقسيم الهياكل إلى قطع ذات طبقات أو هرمية لعزل التغييرات ، أو تقلب الأجزاء من الهيكل لفضح تحديثات رخيصة للأجزاء المعدلة بشكل متكرر ، أو حتى تخزين الهيكل الأصلي إلى جانب مجموعة من التحديثات ودمج التحديثات مع الأصل على الأصل فقط على الذبابة عندما يتم الوصول إلى البيانات.
نظرًا لأنك تستخدم F# هنا ، سأفترض أنك على الأقل على دراية بـ C# ؛ لا يقدر بثمن إريك ليبرت عدد كبير من الوظائف على هياكل البيانات غير القابلة للتغيير في C# والتي من المحتمل أن تنولك إلى ما هو أبعد من ما يمكنني تقديمه. على مدار العديد من المنشورات ، يوضح تطبيقات غير قابلة للتغيير (فعالة بشكل معقول) من المكدس والشجرة الثنائية وقائمة الانتظار المزدوجة ، من بين أمور أخرى. قراءة مبهجة لأي مبرمج .NET!
قد تكون مهتمًا باستراتيجيات الحد من التعبيرات في لغات البرمجة الوظيفية. كتاب جيد عن هذا الموضوع تنفيذ لغات البرمجة الوظيفية, ، بقلم سيمون بيتون جونز ، أحد منشئي هاسكل. إلقاء نظرة خاصة على الفصل التالي تخفيض الرسم البياني من تعبيرات لامدا لأنه يصف مشاركة التعبيرات الفرعية المشتركة. آمل أن يساعد ذلك ، لكنني أخشى أن ينطبق فقط على اللغات الكسول.
