Wie speichereffiziente zerstörungs Manipulation von Sammlungen wird in der funktionalen Programmierung erreicht?
 https://stackoverflow.com/questions/1993760
https://stackoverflow.com/questions/1993760
-
22-09-2019 - |
 italiano
italiano english
english français
français española
española 中国
中国 日本の
日本の العربية
العربية Deutsch
Deutsch 한국어
한국어 Português
Português Russian
RussianFrage
Ich versuche, herauszufinden, wie nicht-destruktive Bearbeitung großer Sammlungen in der funktionalen Programmierung implementiert ist, dh. wie es möglich ist, zu ändern oder einzelne Elemente zu entfernen, ohne eine völlig neue Sammlung erstellen zu müssen, in der alle Elemente, auch die unmodifizierten, im Speicher dupliziert werden. (Auch wenn die ursprüngliche Sammlung Garbage Collection wäre, würde ich den Speicherbedarf und die allgemeine Leistung einer solchen Sammlung erwarten schrecklich zu sein.)
Dies ist, wie weit habe ich bis jetzt habe:
Mit F #, kam ich mit einer Funktion insert up, die eine Liste in zwei Teile und führt spaltet ein neues Element in-between, scheinbar ohne alle unveränderten Elemente Klonen:
// return a list without its first n elements:
// (helper function)
let rec skip list n =
if n = 0 then
list
else
match list with
| [] -> []
| x::xs -> skip xs (n-1)
// return only the first n elements of a list:
// (helper function)
let rec take list n =
if n = 0 then
[]
else
match list with
| [] -> []
| x::xs -> x::(take xs (n-1))
// insert a value into a list at the specified zero-based position:
let insert list position value =
(take list position) @ [value] @ (skip list position)
ich dann, ob Objekte von einer ursprünglichen Liste überprüft werden „recycelt“ in neuen Listen von .NET des Object.ReferenceEquals mit:
open System
let (===) x y =
Object.ReferenceEquals(x, y)
let x = Some(42)
let L = [Some(0); x; Some(43)]
let M = Some(1) |> insert L 1
Die folgenden drei Ausdrücke alle bewerten zu true, was darauf hinweist, dass der Wert bezeichnet durch x wiederverwendet wird sowohl in Listen L und M, dh. dass es nur 1 Kopie dieses Wertes im Speicher:
L.[1] === x
M.[2] === x
L.[1] === M.[2]
Meine Frage:
Sie funktionalen Programmiersprachen im Allgemeinen wiederverwenden Werte, anstatt sie an einen neuen Speicherort Klonen oder war ich mit F # 's Verhalten einfach nur Glück? Unter der Annahme, das ehemalige, ist dies, wie vernünftig speichereffiziente Bearbeitung von Sammlungen können in der funktionalen Programmierung umgesetzt werden?
(Btw .: weiß ich über Chris Okasaki Buch rein funktionale Datenstrukturen , aber hatte noch nicht die Zeit, es gründlich zu lesen.)
Lösung
Ich versuche, herauszufinden, wie zerstörungs Manipulation großer Sammlungen implementiert in funktionale Programmierung, dh. wie es ist möglich, einzelne zu verändern oder entfernen Elemente ohne eine zu schaffen, die völlig neue Kollektion, wo alle Elemente, auch die unmodifizierten, wird im Speicher dupliziert werden.
Diese Seite einige Beschreibungen und Implementierungen von Datenstrukturen in F # hat. Die meisten von ihnen kommen aus Okasaki des rein funktionale Datenstrukturen , obwohl der AVL-Baum meine eigene Implementierung ist, da es nicht im Buch war.
Nun, da Sie gefragt, um nicht modifizierte Knoten Wiederverwendung, lassen Sie uns einen einfachen binären Baum:
type 'a tree =
| Node of 'a tree * 'a * 'a tree
| Nil
let rec insert v = function
| Node(l, x, r) as node ->
if v < x then Node(insert v l, x, r) // reuses x and r
elif v > x then Node(l, x, insert v r) // reuses x and l
else node
| Nil -> Node(Nil, v, Nil)
Beachten Sie, dass wir einige unserer Knoten wiederverwenden. Lassen Sie uns sagen, dass wir mit diesem Baum starten:
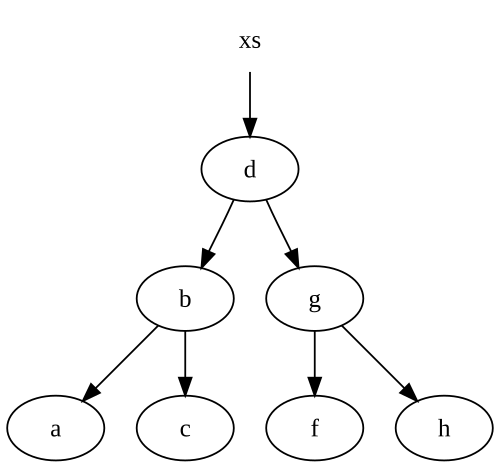
Wenn wir Einsatz einer e in den Baum, so erhalten wir einen brandneuen Baum, mit einigen der Knoten wieder in unserem ursprünglichen Baum zeigen:

Wenn wir oben nicht einen Verweis auf den xs Baum, dann .NET Willen Müll alle Knoten ohne Live-Referenzen sammeln, speziell thed, g und f Knoten.
Beachten Sie, dass wir haben nur die geänderten Knoten auf dem Weg unserer eingesetztem node . Das ist ziemlich typisch in den meisten unveränderlichen Datenstrukturen, einschließlich Listen. So ist die Anzahl der Knoten schaffen wir gleich genau die Anzahl von Knoten brauchen wir, um zu durchlaufen in unsere Datenstruktur einzufügen.
Do funktionalen Programmiersprachen im Allgemeinen wiederverwenden Werte statt sie zu einem neuen Speicherplatz klonen, oder war ich einfach nur Glück mit F # 's Verhalten? Unter der Annahme der ersteren wird dies, wie vernünftig speichereffizient Bearbeitung von Sammlungen können sein in der funktionalen Programmierung implementiert?
Ja.
Listen sind jedoch keine sehr gute Datenstruktur, da die meisten nicht-triviale Operationen auf sie benötigen O (n) Zeit.
Balanced Binärbäumen unterstützen O (log n) Einsätze, was bedeutet, wir O (log n) Kopien auf jedem Einsatz erstellen. Da log 2 (10 ^ 15) ~ = 50, der Aufwand ist sehr sehr klein für diese speziellen Datenstrukturen. Auch wenn Sie jede Kopie jedes Objekts nach Einfügungen / Löschungen halten um, Speicherauslastung mit einer Geschwindigkeit von O erhöhen (n log n) -. Sehr vernünftig, meiner Meinung nach
Andere Tipps
Wie ist es möglich, einzelne Elemente zu verändern oder zu entfernen, ohne eine völlig neue Sammlung erstellen zu müssen, in der alle Elemente, auch die unmodifizierten, werden im Speicher dupliziert werden.
Das funktioniert, weil, egal, welche Art von Sammlung, die Zeiger , um die Elemente selbst getrennt von den Elementen gespeichert sind. (Ausnahme: einige Compiler werden einen Teil der Zeit optimieren, aber sie wissen, was sie tun.) So zum Beispiel können Sie zwei Listen, die nur in dem ersten Elemente und Aktien Schwanz unterscheiden:
let shared = ["two", "three", "four"]
let l = "one" :: shared
let l' = "1a" :: shared
haben diese beiden Listen die shared Teil gemeinsam und ihre ersten Elemente unterschiedlich. Was ist weniger offensichtlich ist, dass jede Liste auch mit einem einzigartigen Paar beginnt, oft eine „cons Zelle“ genannt wird:
-
Liste
lbeginnt mit einem Paar einen Zeiger auf"one"und einen Zeiger auf den gemeinsamen Schwanz enthält. -
Liste
l'beginnt mit einem Paar einen Zeiger auf"1a"und einen Zeiger auf den gemeinsamen Schwanz enthält.
Wenn wir hatten nur erklärt l und wollte ändern oder das erste Element entfernen l' zu bekommen, würden wir dies tun:
let l' = match l with
| _ :: rest -> "1a" :: rest
| [] -> raise (Failure "cannot alter 1st elem of empty list")
Es gibt konstant Kosten:
-
Split
lin den Kopf und Schwanz durch die Nachteile Zelle zu untersuchen. -
Vergeben Sie eine neue cons Zelle zeigt auf
"1a"und dem Schwanz.
Die neue cons Zelle wird der Wert der Liste l'.
Wenn Sie machen punktartigen Veränderungen in der Mitte einer großen Sammlung, in der Regel werden Sie irgendeine Art von ausgeglichenem Baum werden, die logarithmische Raum und Zeit verwendet. Seltener können Sie eine komplexere Datenstruktur verwenden:
-
Gerard Huet Reißverschluss kann für fast jede baumartige Datenstruktur definiert werden, und verwendet werden kann, zu durchqueren und machen punktuellen Änderungen bei konstant Kosten. Reißverschlüsse sind leicht zu verstehen.
-
Paterson und Hinze des Finger Bäume bieten sehr anspruchsvolle Darstellungen von Sequenzen, die unter anderen Tricks können Sie auf Wechselelemente in der Mitte effizient, aber sie sind schwer zu verstehen.
Während die referenzierte Objekte sind gleich in Ihrem Code,
Ich glaube, den Speicherplatz für die Referenzen selbst
und die Struktur der Liste
wird durch take dupliziert.
Als Ergebnis, während die referenzierte Objekte gleich sind,
und die Schwänze sind zwischen den beiden Listen geteilt,
die „Zellen“ für die ersten Abschnitte dupliziert.
Ich bin kein Experte in der funktionalen Programmierung, aber vielleicht mit irgendeiner Art von Baum könnte man erreichen Vervielfältigung von nur log (n) Elemente, wie Sie nur den Pfad von der Wurzel neu erstellen müßten zu dem eingefügten Elemente.
Es klingt für mich wie Ihre Frage in erster Linie um ist unveränderliche Daten , nicht funktionale Sprachen per se . Die Daten sind in der Tat notwendigerweise unveränderlich in rein funktionalen Code (siehe referentielle Transparenz ), aber ich bin nicht bekannt, dass nicht-Spielzeug Sprachen, die überall absolute Reinheit erzwingen (obwohl Haskell am nächsten kommt, wenn Sie wie diese Art der Sache).
Rund Referenz Transparenz Mittel gesprochen, dass kein praktischer Unterschied besteht zwischen einer Variablen / Ausdruck und dem Wert, der es hält / auswertet zu. Weil ein Stück unveränderlicher Daten (per Definition) nie ändern, kann es trivialerweise mit seinem Wert identifiziert werden und sollte nicht unterscheidbar von anderen Daten mit dem gleichen Wert verhalten.
Daher ist es durch die Wahl keine semantische Unterscheidung zwischen zwei Stücken von Daten mit dem gleichen Wert zu ziehen, haben wir keinen Grund, jemals absichtlich einen doppelten Wert aufzubauen. Also, im Fall einer offensichtlichen Gleichheit (zum Beispiel etwas zu einer Liste hinzugefügt, es als Funktion Argument übergeben, & c.), Sprachen, in denen Unveränderlichkeit Garantien möglich sind, werden im Allgemeinen das bestehende Referenzwiederverwenden, wie Sie sagen.
Ebenso unveränderlich Datenstrukturen besitzt eine intrinsische referentielle Transparenz ihre Struktur (wenn auch nicht dessen Inhalt). Unter der Annahme, alle enthaltenen Werte sind auch unveränderlich, bedeutet dies, dass Teile der Struktur sicher in neuen Strukturen und wiederverwendet werden können. Zum Beispiel kann oft der Schwanz einer cons Liste wiederverwendet werden; in Ihrem Code, würde ich erwarten, dass:
(skip 1 L) === (skip 2 M)
... würde auch wahr sein.
Reuse ist nicht immer möglich, obwohl; der Anfangsabschnitt einer durch Ihre skip Funktion entfernt Liste kann nicht wirklich zum Beispiel wiederverwendet werden. Aus dem gleichen Grunde, etwas zu Ende einer cons Liste Anfügen ist eine teuere Operation, da sie mit verketten nullterminierten Strings eine neue Liste, ähnlich das Problem rekonstruieren müssen.
In solchen Fällen naive Ansätze bekommen schnell in das Reich der schrecklichen Leistung Sie angehen. Oft ist es notwendig, im Wesentlichen umdenken grundlegenden Algorithmen und Datenstrukturen, sie zu unveränderlichen Daten erfolgreich anzupassen. Techniken umfassen Bruchstrukturen in Schicht- oder hierarchische Stücke zu isolieren Änderungen, Teile der Struktur Umkehren auf häufig modifizierte Teile billig Updates zu belichten oder sogar neben einer Sammlung von Updates, die ursprünglichen Struktur zu speichern und das Updates mit der Original-on the fly Kombination nur wenn die Daten zugegriffen wird.
Da Sie mit F # hier werde ich Sie mit C # zumindest ein wenig vertraut sind, zu übernehmen; der unschätzbare Eric Lippert hat eine ganze Reihe von Stellen auf unveränderliche Daten Strukturen in C #, die Sie wahrscheinlich erleuchten wird auch über das, was ich bieten könnte. Im Laufe von mehreren Stellen zeigt er (ziemlich effizient) unveränderlich Implementierungen einen Stapel, binären Baum und Deque, unter anderem. Herrliche Lektüre für jeden .NET-Programmierer!
Sie können in Strategien zur Reduzierung von Ausdrücken in funktionalen Programmiersprachen interessiert sein. Ein gutes Buch zu diesem Thema ist Die Implementierung funktionaler Programmiersprachen , von Simon Peyton Jones, einer der Schöpfer von Haskell. Werfen Sie einen Blick vor allem auf folgenden Kapitel Graph Reduzierung der Lambda-Ausdrücke , da sie die gemeinsame Nutzung von Unterausdrücken beschreibt. Hoffe, dass es hilft, aber ich fürchte, es nur zu faul Sprachen gilt.
