Como a manipulação não destrutiva de coleções com uso eficiente de memória é alcançada na programação funcional?
 https://stackoverflow.com/questions/1993760
https://stackoverflow.com/questions/1993760
-
22-09-2019 - |
 italiano
italiano english
english français
français española
española 中国
中国 日本の
日本の العربية
العربية Deutsch
Deutsch 한국어
한국어 Português
Português Russian
RussianPergunta
Estou tentando descobrir como a manipulação não destrutiva de grandes coleções é implementada na programação funcional, ou seja.como é possível alterar ou remover elementos únicos sem ter que criar uma coleção completamente nova onde todos os elementos, mesmo os não modificados, serão duplicados na memória.(Mesmo que a coleção original fosse coletada como lixo, eu esperaria que o consumo de memória e o desempenho geral dessa coleção fossem terríveis.)
Isto é o quão longe eu cheguei até agora:
Usando F#, criei uma função insert que divide uma lista em duas partes e introduz um novo elemento intermediário, aparentemente sem clonar todos os elementos inalterados:
// return a list without its first n elements:
// (helper function)
let rec skip list n =
if n = 0 then
list
else
match list with
| [] -> []
| x::xs -> skip xs (n-1)
// return only the first n elements of a list:
// (helper function)
let rec take list n =
if n = 0 then
[]
else
match list with
| [] -> []
| x::xs -> x::(take xs (n-1))
// insert a value into a list at the specified zero-based position:
let insert list position value =
(take list position) @ [value] @ (skip list position)
Em seguida, verifiquei se os objetos de uma lista original são "reciclados" em novas listas usando o .NET Object.ReferenceEquals:
open System
let (===) x y =
Object.ReferenceEquals(x, y)
let x = Some(42)
let L = [Some(0); x; Some(43)]
let M = Some(1) |> insert L 1
Todas as três expressões a seguir são avaliadas como true, indicando que o valor referido por x é reutilizado em listas L e M, ou seja.que existe apenas 1 cópia deste valor na memória:
L.[1] === x
M.[2] === x
L.[1] === M.[2]
Minha pergunta:
As linguagens de programação funcionais geralmente reutilizam valores em vez de cloná-los em um novo local de memória ou tive sorte com o comportamento do F #?Supondo a primeira opção, é assim que a edição de coleções com eficiência de memória pode ser implementada na programação funcional?
(Por falar nisso.:Eu sei sobre O livro de Chris Okasaki Estruturas de dados puramente funcionais, mas ainda não tive tempo de lê-lo completamente.)
Solução
Estou tentando descobrir como a manipulação não destrutiva de grandes coleções é implementada em programação funcional, ou seja. Como é possível alterar ou remover elementos únicos sem precisar criar uma coleção completamente nova, onde todos os elementos, mesmo os não modificados, serão duplicados na memória.
Esta página Possui algumas descrições e implementações de estruturas de dados em F#. A maioria deles vem do Okasaki's Estruturas de dados puramente funcionais, embora a árvore AVL seja minha própria implementação, pois não estava presente no livro.
Agora, desde que você perguntou, sobre a reutilização de nós não modificados, vamos pegar uma árvore binária simples:
type 'a tree =
| Node of 'a tree * 'a * 'a tree
| Nil
let rec insert v = function
| Node(l, x, r) as node ->
if v < x then Node(insert v l, x, r) // reuses x and r
elif v > x then Node(l, x, insert v r) // reuses x and l
else node
| Nil -> Node(Nil, v, Nil)
Observe que reutilizamos alguns de nossos nós. Digamos que começamos com esta árvore:
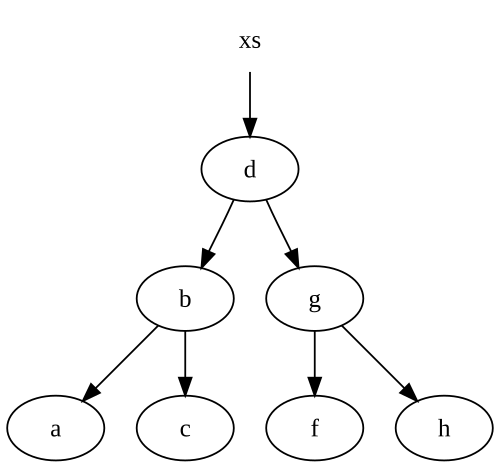
Quando inserimos um e Na árvore, temos uma árvore nova, com alguns dos nós apontando de volta para nossa árvore original:

Se não tivermos uma referência ao xs Árvore acima, então .NET lixo coletará quaisquer nós sem referências vivas, especificamente od, g e f nós.
Observe que nós apenas modificamos nós ao longo do caminho do nosso nó inserido. Isso é bastante típico na maioria das estruturas de dados imutáveis, incluindo listas. Portanto, o número de nós que criamos é exatamente igual ao número de nós que precisamos atravessar para inserir em nossa estrutura de dados.
As linguagens de programação funcionais geralmente reutilizam valores em vez de cloná-los em um novo local de memória, ou tive sorte com o comportamento de F#? Assumindo o primeiro, é assim que a edição de coleções com eficiência de memória pode ser implementada na programação funcional?
Sim.
As listas, no entanto, não são uma estrutura de dados muito boa, pois a maioria das operações não triviais nelas exige tempo O (n).
As árvores binárias equilibradas suportam as inserções de O (log n), o que significa que criamos cópias de O (log n) em cada inserção. Desde o log2(10^15) é ~ = 50, a sobrecarga é muito pequena para essas estruturas de dados específicas. Mesmo se você mantiver todas as cópias de todos os objetos após inserções/excluir, o uso da memória aumentará a uma taxa de O (n log n) - muito razoável, na minha opinião.
Outras dicas
Como é possível alterar ou remover elementos únicos sem precisar criar uma coleção completamente nova, onde todos os elementos, mesmo os não modificados, serão duplicados na memória.
Isso funciona porque não importa que tipo de coleção, o Ponteiros para os elementos são armazenados separadamente dos próprios elementos. (Exceção: alguns compiladores otimizarão algumas vezes, mas sabem o que estão fazendo.) Por exemplo, você pode ter duas listas que diferem apenas no primeiro elemento e compartilham Tails:
let shared = ["two", "three", "four"]
let l = "one" :: shared
let l' = "1a" :: shared
Essas duas listas têm o shared parte em comum e seus primeiros elementos diferentes. O que é menos óbvio é que cada lista também começa com um par único, geralmente chamado de "célula contras":
Lista
lcomeça com um par contendo um ponteiro para"one"e um ponteiro para a cauda compartilhada.Lista
l'começa com um par contendo um ponteiro para"1a"e um ponteiro para a cauda compartilhada.
Se tivéssemos declarado apenas l e queria alterar ou remover o primeiro elemento para obter l', faríamos isso:
let l' = match l with
| _ :: rest -> "1a" :: rest
| [] -> raise (Failure "cannot alter 1st elem of empty list")
Há um custo constante:
Dividir
lem sua cabeça e cauda examinando a célula contras.Alocar uma nova célula de contras apontando para
"1a"e a cauda.
A nova célula contras se torna o valor da lista l'.
Se você estiver fazendo alterações no meio de uma grande coleção, normalmente estará usando algum tipo de árvore equilibrada que usa tempo e espaço logarítmicos. Com menos frequência você pode usar uma estrutura de dados mais sofisticada:
Gerard Huet's zíper Pode ser definido para praticamente qualquer estrutura de dados em forma de árvore e pode ser usado para atravessar e fazer modificações pontuais a um custo constante. Os zíperes são fáceis de entender.
Paterson e Hinze árvores dos dedos Ofereça representações muito sofisticadas de seqüências, que, entre outros truques, permitem mudar de elementos no meio com eficiência - mas são difíceis de entender.
Embora os objetos referenciados sejam os mesmos em seu código, acredito no espaço de armazenamento para as próprias referências e a estrutura da lista é duplicada por take. Como resultado, enquanto os objetos referenciados são os mesmos e as caudas são compartilhadas entre as duas listas, as "células" para as partes iniciais são duplicadas.
Não sou especialista em programação funcional, mas talvez com algum tipo de árvore você possa obter duplicação apenas de elementos de log (n), pois você precisaria recriar apenas o caminho da raiz para o elemento inserido.
Parece-me que sua pergunta é principalmente sobre dados imutáveis, não linguagens funcionais por si só.Os dados são de fato necessariamente imutáveis em código puramente funcional (cf. transparência referencial), mas não conheço nenhuma linguagem que não seja de brinquedo que imponha pureza absoluta em todos os lugares (embora Haskell seja o mais próximo, se você gosta desse tipo de coisa).
Grosso modo, transparência referencial significa que nenhuma diferença prática existe entre uma variável/expressão e o valor que ela contém/avalia.Como um dado imutável (por definição) nunca mudará, ele pode ser trivialmente identificado com seu valor e deve se comportar de forma indistinguível de quaisquer outros dados com o mesmo valor.
Portanto, ao optar por não fazer nenhuma distinção semântica entre dois dados com o mesmo valor, não temos razão para construir deliberadamente um valor duplicado.Portanto, em casos de igualdade óbvia (por exemplo, adicionar algo a uma lista, passá-lo como um argumento de função, etc.), linguagens onde são possíveis garantias de imutabilidade geralmente reutilizarão a referência existente, como você diz.
Da mesma forma, imutável estruturas de dados possuem uma transparência referencial intrínseca de sua estrutura (embora não de seu conteúdo).Supondo que todos os valores contidos também sejam imutáveis, isso significa que partes da estrutura também podem ser reutilizadas com segurança em novas estruturas.Por exemplo, o final de uma lista de contras pode muitas vezes ser reutilizado;no seu código, eu esperaria que:
(skip 1 L) === (skip 2 M)
...seria também seja verdadeiro.
Porém, a reutilização nem sempre é possível;a parte inicial de uma lista removida pelo seu skip a função não pode realmente ser reutilizada, por exemplo.Pela mesma razão, acrescentar algo ao final de uma lista de contras é uma operação cara, pois deve reconstruir uma lista totalmente nova, semelhante ao problema da concatenação de strings terminadas em nulo.
Nesses casos, abordagens ingênuas rapidamente entram no reino do péssimo desempenho que o preocupava.Freqüentemente, é necessário repensar substancialmente algoritmos e estruturas de dados fundamentais para adaptá-los com sucesso a dados imutáveis.As técnicas incluem quebrar estruturas em partes hierárquicas ou em camadas para isolar alterações, inverter partes da estrutura para expor atualizações baratas a partes modificadas com frequência ou até mesmo armazenar a estrutura original junto com uma coleção de atualizações e combinar as atualizações com o original apenas em tempo real. quando os dados são acessados.
Como você está usando F# aqui, presumo que você esteja pelo menos um pouco familiarizado com C#;o inestimável Eric Lippert tem um uma série de postagens em estruturas de dados imutáveis em C# que provavelmente irão esclarecê-lo muito além do que eu poderia fornecer.Ao longo de vários posts, ele demonstra implementações imutáveis (razoavelmente eficientes) de pilha, árvore binária e fila dupla, entre outras.Leitura deliciosa para qualquer programador .NET!
Você pode estar interessado em estratégias de redução de expressões em linguagens de programação funcionais. Um bom livro sobre o assunto é A implementação de linguagens de programação funcional, por Simon Peyton Jones, um dos criadores de Haskell. Dê uma olhada especialmente no capítulo seguinte Redução de gráficos de expressões lambda uma vez que descreve o compartilhamento de subexpressões comuns. Espero que ajude, mas receio que se aplique apenas a idiomas preguiçosos.
