Comment est la manipulation non destructive efficace mémoire des collections réalisé dans la programmation fonctionnelle?
 https://stackoverflow.com/questions/1993760
https://stackoverflow.com/questions/1993760
-
22-09-2019 - |
 italiano
italiano english
english français
français española
española 中国
中国 日本の
日本の العربية
العربية Deutsch
Deutsch 한국어
한국어 Português
Português Russian
RussianQuestion
Je suis en train de comprendre comment la manipulation non destructive de grandes collections est mis en œuvre dans la programmation fonctionnelle, à savoir. comment il est possible de modifier ou de supprimer des éléments simples sans avoir à créer une collection complètement nouvelle où tous les éléments, même ceux non modifiés, seront dupliqués en mémoire. (Même si la collection originale serait ramasse-miettes, je pense l'empreinte mémoire et les performances générales d'une telle collection terrible.)
Voici jusqu'où j'ai jusqu'à présent:
En utilisant F #, je suis venu avec une insert fonction qui divise une liste en deux morceaux et introduit un nouvel élément entre les deux, apparemment sans clonage tous les éléments inchangés:
// return a list without its first n elements:
// (helper function)
let rec skip list n =
if n = 0 then
list
else
match list with
| [] -> []
| x::xs -> skip xs (n-1)
// return only the first n elements of a list:
// (helper function)
let rec take list n =
if n = 0 then
[]
else
match list with
| [] -> []
| x::xs -> x::(take xs (n-1))
// insert a value into a list at the specified zero-based position:
let insert list position value =
(take list position) @ [value] @ (skip list position)
Je puis vérifié si les objets à partir d'une liste initiale sont « recyclés » dans de nouvelles listes en utilisant la Object.ReferenceEquals de .NET:
open System
let (===) x y =
Object.ReferenceEquals(x, y)
let x = Some(42)
let L = [Some(0); x; Some(43)]
let M = Some(1) |> insert L 1
Les trois expressions suivantes toutes les évaluent à true, ce qui indique que la valeur visée par x est à nouveau utilisé à la fois dans les listes L et M, par exemple. qu'il y a seulement une copie de cette valeur en mémoire:
L.[1] === x
M.[2] === x
L.[1] === M.[2]
Ma question:
les langages de programmation fonctionnelle valeurs réutilisation généralement au lieu de les cloner vers un nouvel emplacement de mémoire, ou j'eu de la chance avec le comportement de F #? En supposant que le premier, est-ce ainsi que raisonnablement l'édition économe en mémoire des collections peut être mis en œuvre dans la programmation fonctionnelle?
(BTW .: Je sais livre de Chris Okasaki structures de données fonctionnelles Purement , mais ne l'ont pas encore eu le temps de le lire attentivement.)
La solution
Je suis en train de comprendre comment manipulation non destructive d'un grand collections sont mises en œuvre programmation fonctionnelle, par exemple. comment c'est possible de modifier ou d'enlever unique éléments sans avoir à créer une toute nouvelle collection où tous éléments, même ceux non modifiés, sera dupliqué dans la mémoire.
Cette page a quelques descriptions et mises en œuvre de structures de données en F #. La plupart d'entre eux proviennent de structures de données de Okasaki Purement fonctionnels , bien que l'arbre AVL est ma propre mise en œuvre, car il n'a pas été présent dans le livre.
Maintenant, puisque vous avez demandé, de réutiliser des noeuds non modifiés, nous allons prendre d'un simple arbre binaire:
type 'a tree =
| Node of 'a tree * 'a * 'a tree
| Nil
let rec insert v = function
| Node(l, x, r) as node ->
if v < x then Node(insert v l, x, r) // reuses x and r
elif v > x then Node(l, x, insert v r) // reuses x and l
else node
| Nil -> Node(Nil, v, Nil)
Notez que nous réutilisons certains de nos nœuds. Disons que nous commençons par cet arbre:
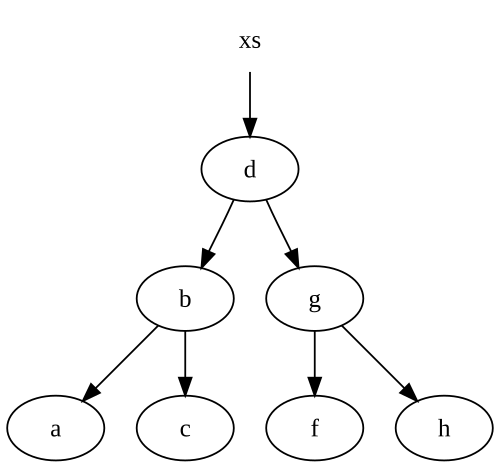
Lorsque nous insérons un e dans l'arbre, nous obtenons un arbre tout neuf, avec quelques-uns des nœuds pointant à notre arbre d'origine:

Si on n'a pas une référence à l'arbre de xs ci-dessus, .NET garbage collecter tous les nœuds sans références en direct, en particulier thed, les nœuds de g et f.
Notez que nous avons seulement des noeuds le long du chemin de notre noeud inséré . Ceci est assez typique dans les structures de données les plus immuables, y compris les listes. Ainsi, le nombre de nœuds que nous créons est exactement égal au nombre de nœuds que nous devons traverser pour insérer dans notre structure de données.
les langages de programmation fonctionnelle Les valeurs de réutilisation en général au lieu de les clonant vers un nouvel emplacement de mémoire, ou ai-je eu de la chance avec F # 's comportement? En supposant que le premier, est cette façon raisonnablement efficace mémoire l'édition des collections peut être mis en œuvre dans la programmation fonctionnelle?
Oui.
Les listes, ne sont cependant pas une structure de données très bonne, puisque la plupart des opérations non négligeables sur les obliger O (n).
support équilibré arbres binaires O (log n) inserts, ce qui signifie que nous créons des copies O (log n) sur chaque insert. Depuis log 2 (10 ^ 15) est ~ = 50, les frais généraux est très très petit pour ces structures de données particulières. Même si vous gardez autour de chaque copie de chaque objet après insertions / suppressions, votre utilisation de la mémoire augmente à un taux de O (n log n) -. Très raisonnable, à mon avis
Autres conseils
Comment il est possible de modifier ou de supprimer des éléments simples sans avoir à créer une collection complètement nouvelle où tous les éléments, même ceux non modifiés, seront dupliqués en mémoire.
Cela fonctionne parce que peu importe quel genre de collection, pointeurs aux éléments sont stockés séparément des éléments eux-mêmes. (Exception: certains compilateurs optimisera de temps en temps, mais ils savent ce qu'ils font.) Donc, par exemple, vous pouvez avoir deux listes qui ne diffèrent que dans le premier élément et partager des queues:
let shared = ["two", "three", "four"]
let l = "one" :: shared
let l' = "1a" :: shared
Ces deux listes ont la partie shared en commun et leurs premiers éléments différents. Ce qui est moins évident est que chaque liste commence également avec une paire unique souvent appelé une « cellule de contre »:
-
Liste
lcommence par une paire contenant un pointeur vers"one"et un pointeur vers la queue commune. -
Liste
l'commence par une paire contenant un pointeur vers"1a"et un pointeur vers la queue commune.
Si seulement nous avions déclaré l et voulait altérer ou enlever le premier élément pour obtenir l', nous ferions ceci:
let l' = match l with
| _ :: rest -> "1a" :: rest
| [] -> raise (Failure "cannot alter 1st elem of empty list")
Il y a coût constant:
-
lfendu dans sa tête et la queue en examinant la cellule de contre. -
Allouer une nouvelle cellule cons montrant
"1a"et la queue.
La nouvelle cellule de contre devient la valeur de la liste l'.
Si vous apportez des modifications ponctuelles comme au milieu d'une grande collection, en général, vous allez utiliser une sorte d'arbre équilibré qui utilise le temps et dans l'espace logarithmique. Moins fréquemment, vous pouvez utiliser une structure de données plus sophistiquées:
-
Gérard Huet de zipper peut être défini pour à peu près toute structure de données arborescente et peuvent être utilisés pour traverser et apporter des modifications de coût constant à ponctuels. Zippers sont faciles à comprendre.
-
Paterson et Hinze de arbres doigt offrent des représentations très sophistiquées de séquences, qui, entre autres astuces vous permettent de changer les éléments au milieu efficace, mais ils sont difficiles à comprendre.
Alors que les objets référencés sont les mêmes dans votre code,
Je beleive l'espace de stockage pour les références eux-mêmes
et la structure de la liste
est dupliqué par take.
En conséquence, alors que les objets référencés sont les mêmes,
et les queues sont partagées entre les deux listes,
les « cellules » pour les parties initiales sont dupliqués.
Je ne suis pas un expert en programmation fonctionnelle, mais peut-être avec une sorte d'arbre que vous pourriez réaliser duplication des éléments seulement log (n), comme vous devez recréer seul le chemin de la racine à l'élément inséré.
Il me semble que votre question porte essentiellement sur données immuables , et non les langages fonctionnels en soi . Les données sont en effet nécessairement immuable dans le code purement fonctionnel (cf. transparence référentielle ), mais Je ne suis pas au courant de toutes les langues non-jouet pureté absolue qui appliquent partout (bien que Haskell se rapproche le plus, si vous aimez ce genre de chose).
grosso modo, signifie la transparence référentielle que pas de différence pratique existe entre une variable / expression et la valeur qu'elle détient / est évaluée à. Parce qu'un morceau de données immuables sera (par définition) ne changent jamais, il peut être trivialement identifié à sa valeur et doit se comporter indiscernable de toute autre donnée avec la même valeur.
Par conséquent, en choisissant de tirer aucune distinction sémantique entre deux morceaux de données avec la même valeur, nous avons aucune raison de jamais délibérément construire une valeur en double. Ainsi, en cas d'égalité évidente (par exemple, d'ajouter quelque chose à une liste, en passant comme un argument de fonction, etc.)., Les langues où les garanties de immutabilité sont possibles réutilisent généralement la référence existante, comme vous le dites.
De même, les structures de données immuables possèdent une transparence référentielle intrinsèque de leur structure (mais pas leur contenu). Si l'on suppose toutes les valeurs contenues sont également immuables, cela signifie que les pièces de la structure peuvent être réutilisés en toute sécurité dans les nouvelles structures aussi bien. Par exemple, la queue d'une liste de contre peut souvent être réutilisé; dans votre code, j'attendre à ce que:
(skip 1 L) === (skip 2 M)
... serait aussi est vrai.
La réutilisation est pas toujours possible, cependant; la partie initiale d'une liste supprimée par votre fonction skip ne peut pas vraiment être réutilisé, par exemple. Pour la même raison, quelque chose à la annexant fin d'une liste de contre est une opération coûteuse, car il doit reconstruire une nouvelle liste complète, semblable au problème avec concaténer des chaînes terminées par null.
Dans ce cas, les approches naïves obtenir rapidement dans le domaine de la performance terrible que vous étiez préoccupé. Souvent, il est nécessaire de repenser considérablement les algorithmes et les structures de données pour les adapter avec succès à des données immuables. Les techniques comprennent des structures de rupture en morceaux en couches ou hiérarchiques pour isoler les changements, inversion de parties de la structure pour exposer les mises à jour à bas prix des pièces modifiées fréquemment, ou même le stockage de la structure d'origine à côté d'une collection de mises à jour et en combinant les mises à jour avec l'original à la volée seulement lorsque les données sont accessibles.
Puisque vous utilisez F # ici, je vais supposer que vous êtes au moins un peu familier avec C #; l'inappréciable Eric Lippert a de messages sur des données immuables structures en C # que vous éclairera sans doute bien au-delà de ce que je pouvais fournir. Au cours de plusieurs postes, il démontre (raisonnablement efficaces) mises en œuvre immuables d'une pile, arbre binaire, et la file d'attente à deux extrémités, entre autres. lecture agréable pour tout programmeur .NET!
Vous pouvez être intéressé par les stratégies de réduction des expressions dans les langages de programmation fonctionnels. Un bon livre sur le sujet est La mise en œuvre des langages de programmation fonctionnels , par Simon Peyton Jones, l'un des créateurs de Haskell. Jetez un coup d'oeil en particulier au chapitre suivant Graphique réduction des expressions Lambda car il décrit le partage des sous-expressions communes. Je espère que ça aide, mais je crains qu'il applique uniquement aux langues paresseux.
